机器学习 & 知识图谱常用术语
算法常用术语
1. 机器学习
1.1 什么是机器学习
什么是“学习”?学习就是人类通过观察、积累经验,掌握某项技能或能力。就好像我们从小学习识别字母、认识汉字,就是学习的过程。而机器学习(Machine Learning),顾名思义,就是让机器(计算机)也能向人类一样,通过观察大量的数据和训练,发现事物规律,获得某种分析问题、解决问题的能力。
要素:
- 向量(vector):在数学中,向量(也称为欧几里得向量、几何向量、矢量),指具有大小(magnitude)和方向的量。如下图所示;
-
特征(feature):x ,一般是个向量,向量的每个维度表示一个特征因子;如:人的身高、年龄;
-
标签(label):y,目标值,如:该病人可能患的疾病;
-
样本(example):(x ,y);
-
训练集:又称训练样本集,用于模型训练的样本集;
-
验证集:又称验证样本集,用于模型验证的样本集;

理想的目标函数f 是未知的,一般只有一些训练样本集D ,其中有输入x (特征),也有输出y(标签)。机器学习的过程,就是根据先验知识选择模型,该模型对应的hypothesis set (用H表示),H中包含了许多不同的hypothesis,通过演算法A ,在训练样本D上进行训练,选择出一个最好的hypothes,对应的函数表达式g 就是我们最终要求的。一般情况下,g能最接近目标函数f ,这样,机器学习的整个流程就完成了。
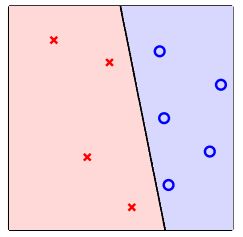
如上图所示:机器学习就是通过二维平面里的点(训练样本集D)(红色点 & 蓝色点)通过演算法(A)学习一条直线(g)将两类点分开。其中理想的分割线(f)是将两类点分的最开的线条,g可以接近f,但无法完全等于f。
1.2 哪些场景可以使用机器学习
事物本身存在某种潜在规律
某些问题难以使用普通编程解决
有大量的数据样本 可供使用
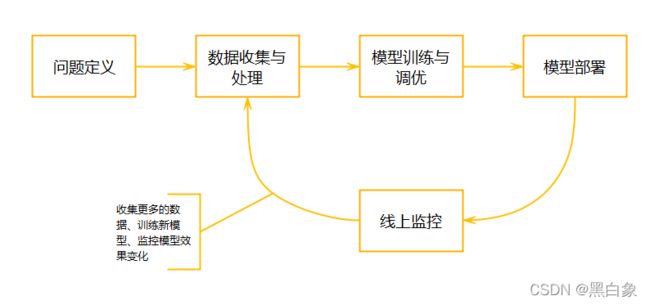
1.3 机器学习工作流程
-
1. 问题定义
-
2.数据获取、分析与特征工程
- 分析 :理解特征的数据类型、值以及分布;理解特征之间的相关性;
- 属性分析
- 属性类型分析

- 数值分析
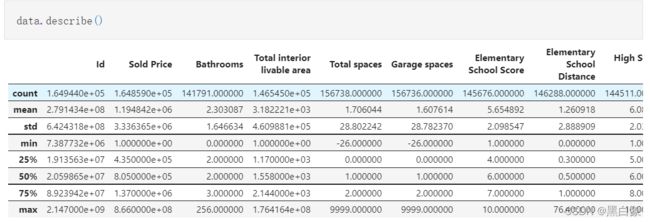
- 数据分布分析
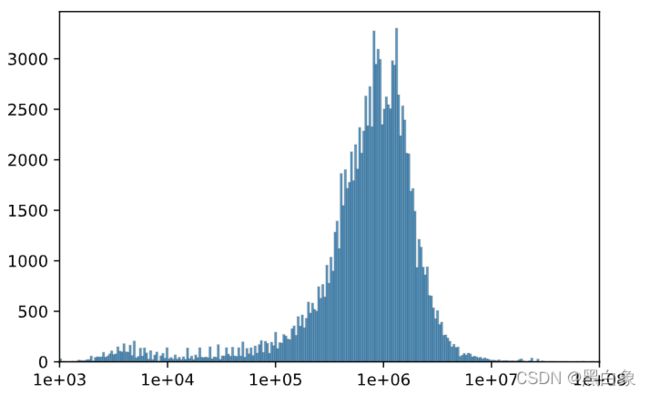
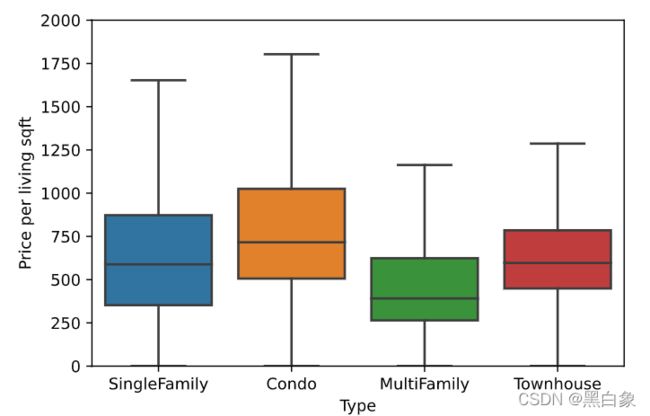
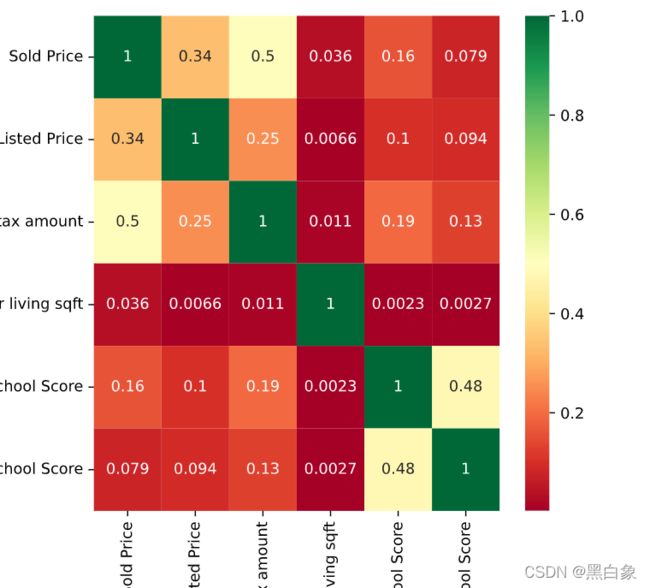
- 相关性分析
- 特征工程 :对原始数据分析处理转化为模型可用的特征
1. 探索性数据分析:数据分布、缺失、异常及相关性等情况;
2. 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;
3. 特征提取:特征表示,特征选择,特征降维等;
- 3.模型训练、评估与调优
1. 模型训练:使用训练集训练模型
2. 模型评估:使用验证集评估模型
- 统计学考量(以二分类为例,p表示正例,n表示负例)
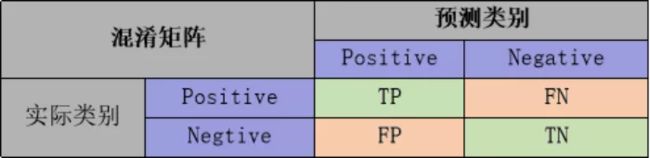
1. TP:实际类别为p,预测类别为p
2. FP:实际类别为n,预测类别为p
3. FN:实际类别为p,预测类别为n
4. TN:实际类别为n,预测类别为n

- 其他考量
- 响应时间:是指用户从客户端发出请求到接收完服务器返回结果的整个过程所需花费的时间;
- 并发用户数:是指在一定时间内,某一时刻同时与服务器进行会话操作的用户数;
- 吞吐量:是指单位时间内,系统处理用户的请求数或页面数量,可以直接反映出软件的承载能力;
- 资源利用率:是指系统资源(CPU、内存、GPU)的利用率;
3. 模型调优:根据模型效果对模型进行调优
- 效果分析:
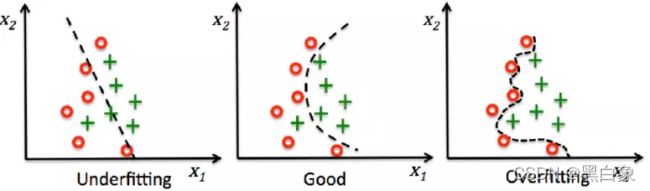
过拟合(Over fitting): 模型在训练集上效果好,在验证集效果不好;
欠拟合(Under fitting): 模型在训练集和验证集效果都不好;
- 模型调优:
1. 调整模型

2. 调整数据

- 4.模型部署 :将模型封装成服务供外围系统使用;
- 5.线上监控 :观察并分析模型真实的效果,收集更多的数据、更新迭代模型;
1. 收集系统日志;
2. 分析线上数据;
3. 根据线上数据调整训练集和验证集;
4. 重新训练、调优模型;
5. 更新模型服务;
2. 知识图谱
2.1 什么是知识图谱
2012 年 5 月,Google 首次提出了“知识图谱”的概念。虽然至今行业尚未形成统一、标准的定义,但Google 知识图谱的宣传语“things not strings”揭示了知识图谱的核心。知识图谱指的是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。
知识图谱由节点和边组成,节点表示实体(entity)、概念(concept)或属性值(value);边表示实体的属性(property)或实体间的关系(relation)。
-
概念:又称为类别(type)、类(category或 class),指反映一组实体的种类或对象类型,如疾病、药品;
-
实体: 又称为对象(object)或实例(instance),指客观世界中具有可区别性且独立存在的某种事物,如 2 型糖尿病、二甲双胍。实体是知识图谱最基本的元素,每个实体可以用一个唯一的ID 进行标识;
-
关系:指连接不同实体的“边”,用以描述实体之间的关联,如二甲双胍和2型糖尿病之间有适应证关系;
-
属性:指某个实体可能具有的特征以及参数,如二甲双胍有医保支付类别属性;
-
属性值:指实体特定属性的值,如二甲双胍的医保支付类别为甲类;
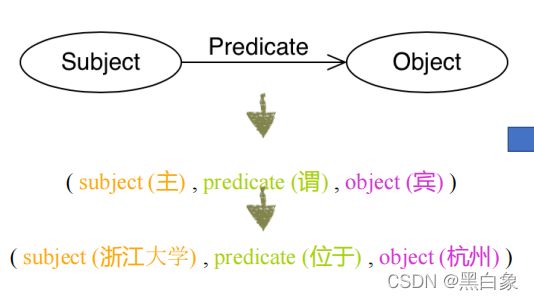
知识图谱在逻辑上分为模式层和数据层。模式层一般指 Schema,是知识图谱的概念模型和逻辑基础,是数据层的规范约束。数据层主要由一系列的事实组成,主要基于模式层定义的模型构建数据,以三元组形式存储。三元组:G=(head,relation/property,tail)是知识图谱数据层的一种通用表示形式,其中 head 是三元组的头节点,tail 是三元组的尾节点,relation/property={r1,r2,r3,…,rM,p1,p2,p3,…,pN} 是知识图谱关系和属性的集合。三元组的基本形式主要包括(实体 1,关系,实体 2)和(实体,属性,属性值)。

2.3 构建流程
-
知识建模 :知识图谱的构建一般可以分为自下而上(Bottom-Up) 和 自 上 而 下(Top-Down)两种方式。前者是先从真实数据中抽取实体和关系,而后归纳总结出知识图谱的Schema;后者则是先归纳总结出知识图谱的 Schema,然后再依据 Schema 进行实体和关系的抽取。通用知识图谱涉及的知识范围广、量级大,一般采用自下而上的方式进行构建;而垂直领域的知识图谱涉及的知识专业性强、难度高,一般采用自上而下的方式进行构建。
-
知识抽取 :知识抽取是知识图谱构建的核心内容,根据任务类型一般可以分为实体识别、关系抽取和事件抽取。其中实体识别和关系抽取应用较广,技术发展也较为成熟,而事件抽取目前在医学领域内应用还较少,仅在传染病学和流行病学领域稍有涉及。
-
知识融合 :知识融合在医学知识图谱的构建中是解决数据异构和冗余的关键步骤,知识融合一般可以分为 Schema 融合和实体对齐。
- Schema 融合:Schema 融合的关键在于充分理解不同知识图谱的 Schema 后,找到其中等价的语义类型和属性关系并建立等价关系。
- 实体对齐:实体对齐是知识融合中最关键的步骤,其主要任务就是判断出的实体间的等价关系,即侧重发现指称真实世界相同对象的不同实例。
- 知识存储 :
- 基于关系型数据库:基于三元组、基于属性表、基于垂直划分表、基于全索引结构
- 基于原生图数据库:属性图、RDF图
- 知识推理 :知识推理是知识图谱构建的重要组成部分,知识推理是指在已有的知识图谱的基础上,通过进一步挖掘出实体间隐含的知识或识别出错误关系的过程。知识推理在知识图谱构建过程中主要应用于知识图谱补全(Knowledge Graph Completion)和知识图谱去噪(Knowledge Graph Cleaning)。知识图谱补全是基于已知的知识图谱中的关系推理出未知的关系;知识图谱去噪则是对三元组正确性的判断和对整个知识图谱逻辑上一致性的校验。
- 知识推理作用:
- 属性补全
- 关系预测
- 错误检测
- 问句扩展
- 语义理解
- 知识推理分类:
1. 基于符号逻辑:局限于显示表示,可解释强;
2. 基于表示学习:易于表示隐式知识,缺乏可解释性;
- 知识应用 :
- 语义搜索:传统的搜索主要为关键词搜索,这种搜索引擎对查询的处理局限于词的表面形式,缺乏知识处理能力和理解能力。将知识图谱应用于搜索是当前实现语义搜索的有效解决方案。知识图谱描述了事物的分类、属性和关系,具有丰富的语义信息,可以为语义搜索提供极大的底层支持。

- 知识问答:基于知识库的问答(Knowledge-Based Question Answering,KBQA)也称知识问答,主要依托于大型的知识库,将用户的自然语言问题转化成结构化查询语句,直接从知识库中导出用户所需的答案。

- 临床决策支持:辅助诊断、治疗方案推荐、合理用药检测
- 药物研发
- 公共卫生事件应对
2.4 其他
- 知识图谱不是单一技术,做知识图谱需要建立系统工程思维
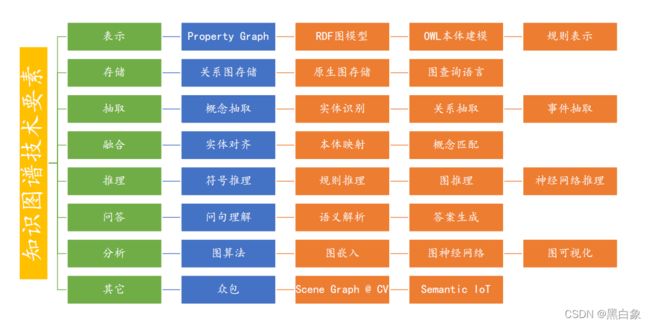
- 知识图谱技术要素
- 知识表示:用易于计算机处理的方式来描述人脑的知识的方法。
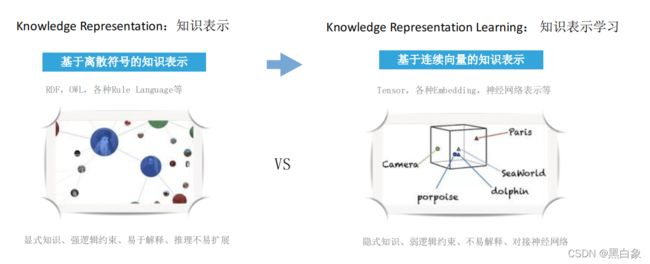
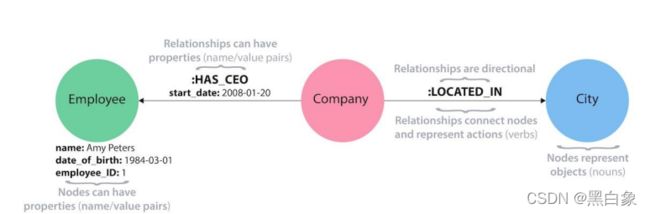
- 属性图(Property Graph):属性图是图数据库Neo4J实现的图结构表示模型,在工业界有广泛应用。在属性图的术语中,属性图是由顶点(Vertex),边(Edge),标签(Label),关系类型还有属性(Property)组成的有向图。
- RDF: 代表 Resource Description Framework (资源描述框架),是国际万维网联盟W3C推动的面向Web的语义数据标准。
- 知识图谱嵌入:知识的向量表示
