pca原理--主成分分析
一:数学基础
1.1 内积
两个向量的 A 和 B 内积我们知道形式是这样的:
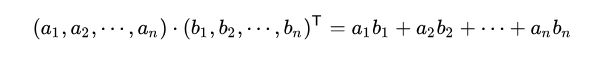
内积运算将两个向量映射为实数,其计算方式非常容易理解,但我们无法看出其物理含义。接下来我们从几何角度来分析,为了简单起见,我们假设 A 和 B 均为二维向量,则:
![]()
其几何表示如下:
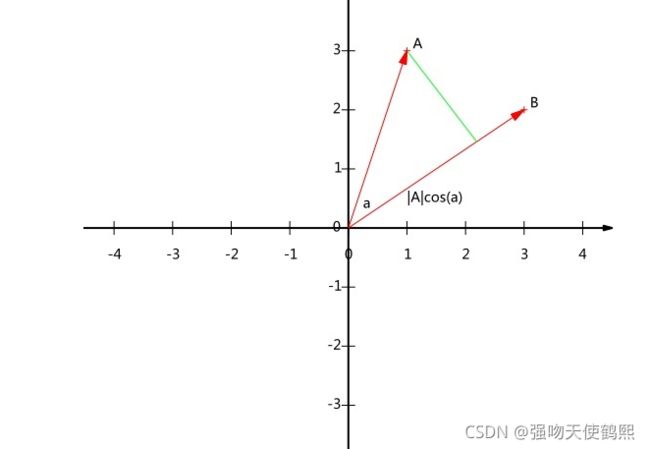
我们可以看到A向量到B向量的内积就等于A向量到B向量的投影长度乘以B向量的模。如果B向量的模等于等于1,即|B| = 1,则有
A*B = |A|COS(α)
也就是说,A 与 B 的内积值等于 A 向 B 所在直线投影的标量大小。
1.2 基
我们都知道坐标轴是向量的参照物,因为向量的数字定义中的每个元素都是向量在对应坐标轴上的投影长度。如下图:

红色部分的投影长度分别为[1,2,3],这正好是向量的数字定义
![]()
如果选择三个坐标轴的方向为向量方向,单位长度1为向量长度,则能够得到三个向量
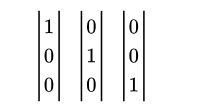
我们称这种向量为单位方向向量,分别称为e1,e2,e3

将上面这三个单位方位向量做一个运算,就可以完整表示原向量的数字定义
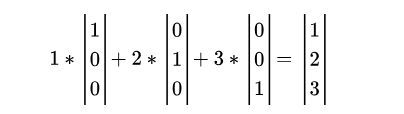
![]()
将上面的运算做一个总结,则有:
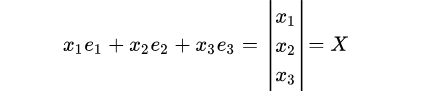
我们将上面的运算中的e1,e2,e3,称为线性空间的一组基,我们可以将基理解为向量数字定义的参照物,而坐标轴实际上是一种特殊的基所在的直线。
1.3 基变换的矩阵表示
一个线性空间Vn,基为{e1,e2,e3,…en}那么任意向量可表示为

如果我们将基变换为另一组基
![]()
则同一向量又可以表示为:
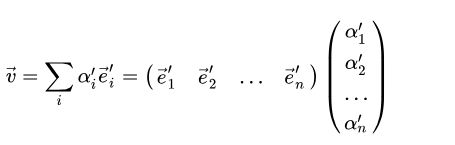
相当于变换了参考系。由线性空间的定义,新的基矢展开为原基矢的线性组合,即
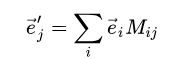
写成矩阵形式则有:

其中矩阵M = (Mij )称为基的变换矩阵。进一步的,将上面式子带入恒等式
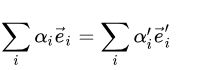
可得变换前后的坐标关系为:
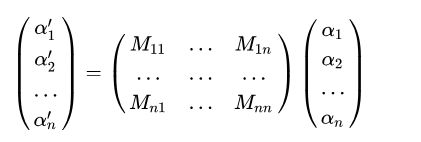
2.0 矩阵的迹
在线性代数中,一个n×n矩阵A的主对角线上各个元素的总和被称为矩阵A的迹,一般记作tr(A)。

2.1 方差
统计学中的方差(样本方差)指的是每个样本与全体样本值的均值的差值的平方值的平均数,他描述的是一维样本的离散程度。公式为如下:

为了方便处理,我们将每个变量的均值都化为 0 ,因此方差可以直接用每个元素的平方和除以元素个数表示:
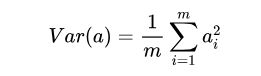
2.2协方差
在一维空间中我们可以用方差来表示一维样本的离散程度,在高维空间中我们用协方差来对高纬数据进行约束,协方差可以表示两个变量的相关性。比如,一个人的身高和体重是否存在一些联系。协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义,来度量各个维度偏离其均值的程度,所以协方差可以这样来定义:
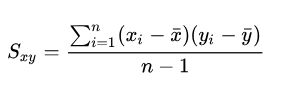
如果结果为正值,则说明两者是线性正相关,也就是说一个人身高越高体重越重。
如果结果为负值, 就说明两者是线性负相关。
如果为0,则两者之间线性不相关,但并不代表两者独立。
我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维,其目标是选择 K 个单位正交基,使得原始数据变换到这组基上后,各变量两两间协方差为 0,而变量方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
2.3 协方差矩阵
针对我们给出的优化目标,接下来我们将从数学的角度来给出优化目标。
我们看到,最终要达到的目的与变量内方差及变量间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们有:
假设我们只有 a 和 b 两个变量,那么我们将它们按列组成矩阵 X:

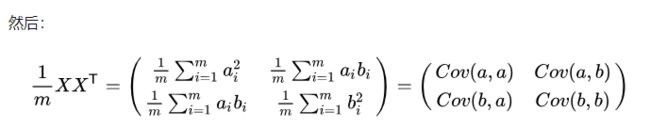
我们可以看到这个矩阵对角线上的分别是两个变量的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵里。
我们很容易被推广到一般情况:
设我们有 m 个 n 维数据记录,将其排列成矩阵 Xm * n,设C = 1\m * xxt,则 C 是一个对称矩阵,其对角线分别对应各个变量的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个变量的协方差。
二:pca的思想
PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是n维的,共有m个数据(x(1),x(2),…,x(m))。我们希望将这m个数据的维度从n维降到n’维,希望这m个n’维的数据集尽可能的代表原始数据集。我们知道数据从n维降到n’维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这n’维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2,n’=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
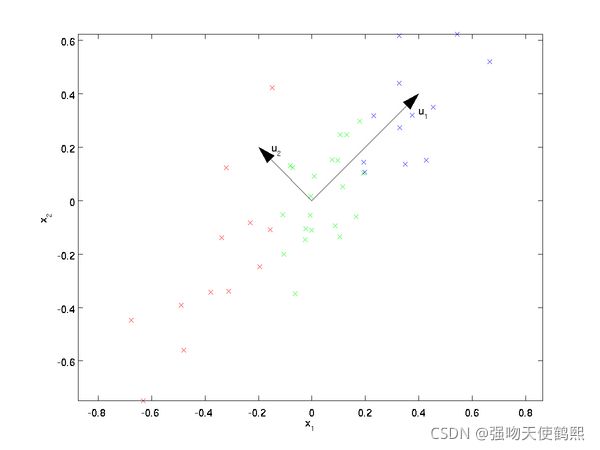
为什么u1比u2好呢?可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开。
假如我们把n’从1维推广到任意维,则我们的希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导–基于最小投影距离和基于最大投影方差
(1)基于最小投影距离(也叫作基于最小平方误差)
我们首先看第一种解释的推导,即样本点到这个超平面的距离足够近,即距离上的平方误差最小化
假设m个n维数据(x(1),x(2),…,x(m))都已经进行了中心化,即Xi求累和等于0,经过投影变换后的信坐标系为{w1,w2,w3…wn}其中w是标准正交基,||w|| = 1,wiTwj = 0,如果我们将数据从n维降到n’维,即丢弃新坐标系中的部分坐标,则新的坐标系为{w1,w2,w3…wn’},样本点x(i)在n’维坐标系中的投影为:
![]()
其中
![]()
是xi在低维坐标系里第j维的坐标。如果我们用zi来恢复原始数据xi,则可以得到恢复数据
![]()
其中w为标准正交基组成的矩阵。
现在我们考虑整个样本集,我们希望所有的样本到这个超平面的距离足够近,即最小化下式:

将这个式子进行整理,可以得到:
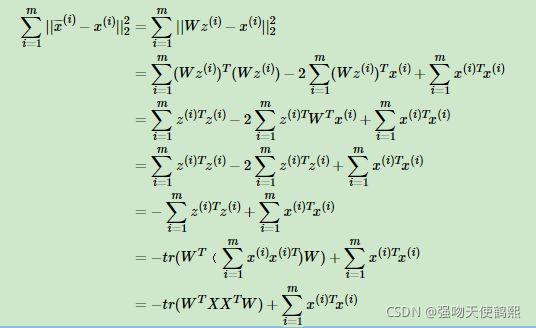
第一步为公式带入,第二步用到了平方和展开,第三部用到了矩阵转秩和WTW=I,第四步带入zi = wt * xi,第五步合并同类项,第六步用到了矩阵的迹,第7步将代数和表达为矩阵形式。我们应该注意,第七步中最后一项是是一个常量,而
![]()
是一个协方差矩阵,最小化上面的式子则等价于
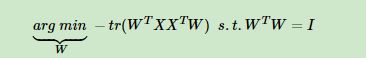
这个最小化不难,直接观察也可以发现最小值对应的W由协方差矩阵XXT最大的n’个特征值对应的特征向量组成,由上面的协方差矩阵的概念我们可知,协方差矩阵的对角线元素都是方差。当然用数学推导也很容易。利用拉格朗日函数可以得到

对W求导有−XXTW+λW=0, 整理下即为:XXTW=λW, 这样可以更清楚的看出,W为XXT的n’个特征向量组成的矩阵,而λ为XXT的若干特征值组成的矩阵,特征值在主对角线上,其余位置为0。当我们将数据集从n维降到n’维时,需要找到最大的n’个特征值对应的特征向量。这n’个特征向量组成的矩阵W即为我们需要的矩阵。对于原始数据集,我们只需要用z(i)=WTx(i),就可以把原始数据集降维到最小投影距离的n’维数据集。如果你熟悉谱聚类的优化过程,就会发现和PCA的非常类似,只不过谱聚类是求前k个最小的特征值对应的特征向量,而PCA是求前k个最大的特征值对应的特征向量。
(2)基于最大投影方差
现在我们来看基于最大投影方差的推导
假设m个n维数据(x(1),x(2),…,x(m))都已经进行了中心化,即Xi求累和等于0,经过投影变换后的新坐标系为{w1,w2,w3…wn}其中w是标准正交基,||w|| = 1,wiT*wj = 0,如果我们将数据从n维降到n’维,即丢弃新坐标系中的部分坐标,则新的坐标系为{w1,w2,w3…wn’},样本点x(i)在n’维坐标系中的投影为:
![]()
其中
![]()
是x(i)在低维坐标系里第j维的坐标。对于任意一个样本x(i),在新的坐标系中的投影为WTx(i),在新坐标系中的投影方差为x(i)TWWTx(i),要使所有的样本的投影方差和最大,也就是最大化![]()
的迹,即:
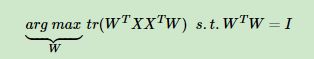
观察第二节的基于最小投影距离的优化目标,可以发现完全一样,只是一个是加负号的最小化,一个是最大化。 利用拉格朗日函数可以得到:

对W求导有XXTW+λW=0, 整理下即为:
![]()
和上面一样可以看出,W为XXT的n’个特征向量组成的矩阵,而−λ为XXT的若干特征值组成的矩阵,特征值在主对角线上,其余位置为0。当我们将数据集从n维降到n’维时,需要找到最大的n’个特征值对应的特征向量。这n’个特征向量组成的矩阵W即为我们需要的矩阵。对于原始数据集,我们只需要用z(i)=WTx(i),就可以把原始数据集降维到最小投影距离的n’维数据集。
三,PCA算法流程
从上面两节可以看出,求样本xi的 n’维的主成分其实就是求样本集的协方差矩阵XXT的前N个特征值对应的特征向量矩阵W,然后对每个样本xi做w矩阵变换: zi = wtxi,即可以达到降维的目的。
下面我们看看具体的算法流程。
输入:n维样本集D=(x(1),x(2),…,x(m)),要降维到的维数n’.
输出:降维后的样本集D′
1,对所有样本去中心化.
2,计算样本集的协方差矩阵XXT
3取出最大的n’个特征值对应的特征向量(w1,w2,w3…wn’)将所有的特征向量标准化后,组成特征向量矩阵w
4,对于样本集中的每一个样本xi,转化为新的样本zi =wtxi
5, 得到输出样本集D′
有时候,我们不指定降维后的n’的值,而是换种方式,指定一个降维到的主成分比重阈值t。这个阈值t在(0,1]之间。假如我们的n个特征值为λ1≥λ2≥…≥λn,则n’可以通过下式得到:
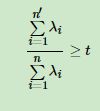
四. PCA实例
下面举一个简单的例子,说明PCA的过程。
假设我们的数据集有10个二维数据(2.5,2.4), (0.5,0.7), (2.2,2.9), (1.9,2.2), (3.1,3.0), (2.3, 2.7), (2, 1.6), (1, 1.1), (1.5, 1.6), (1.1, 0.9),需要用PCA降到1维特征。
首先我们对样本中心化,这里样本的均值为(1.81, 1.91),所有的样本减去这个均值向量后,即中心化后的数据集为(0.69, 0.49), (-1.31, -1.21), (0.39, 0.99), (0.09, 0.29), (1.29, 1.09), (0.49, 0.79), (0.19, -0.31), (-0.81, -0.81), (-0.31, -0.31), (-0.71, -1.01)。
现在我们开始求样本的协方差矩阵,由于我们是二维的,则协方差矩阵为:
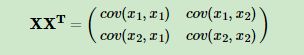
对于我们的数据,求出协方差矩阵为:

求出特征值为(0.0490833989, 1.28402771),对应的特征向量分别为:(0.735178656,0.677873399)T(−0.677873399,−0.735178656)T,由于最大的k=1个特征值为1.28402771,对于的k=1个特征向量为(−0.677873399,−0.735178656)T. 则我们的W=(−0.677873399,−0.735178656)T
我们对所有的数据集进行投影z(i)=WTx(i),得到PCA降维后的10个一维数据集为:(-0.827970186, 1.77758033, -0.992197494, -0.274210416, -1.67580142, -0.912949103, 0.0991094375, 1.14457216, 0.438046137, 1.22382056)
五:KPCA:核主成分分析的介绍
在上面的PCA算法中,我们假设存在一个线性的超平面,可以让我们对数据进行投影。但是有些时候,数据不是线性的,不能直接进行PCA降维。这里就需要用到和支持向量机一样的核函数的思想,先把数据集从n维映射到线性可分的高维N>n,然后再从N维降维到一个低维度n’, 这里的维度之间满足n’ 使用了核函数的主成分分析一般称之为核主成分分析(Kernelized PCA, 以下简称KPCA。假设高维空间的数据是由n维空间的数据通过映射ϕ产生。 则对于n维空间的特征分解:

映射为:
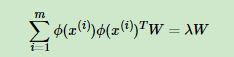
通过在高维空间进行协方差矩阵的特征值分解,然后用和PCA一样的方法进行降维。一般来说,映射ϕ不用显式的计算,而是在需要计算的时候通过核函数完成。由于KPCA需要核函数的运算,因此它的计算量要比PCA大很多。
六:pca算法的总结
pca算法的优点:
1,只用方差衡量信息,不受数据集以外的因素的影响
2,各主成分之间正交,可消除原始数据间的相互影响因素
3,计算方法简单,只需要计算特征值分解,易于计算。
pca的主要缺点:
1,方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃这部分数据,可能会对后面的数据处理产生影响。