ElasticSearch
一、ES的简单介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎。
- 查询 : Elasticsearch 允许执行和合并多种类型的搜索 — 结构化、非结构化、地理位置、度量指标 — 搜索方式随心而变。
- 分析 : 找到与查询最匹配的十个文档是一回事。但是如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。
- 速度 : Elasticsearch 很快。真的,真的很快。
- 可扩展性 : 可以在笔记本电脑上运行。 也可以在承载了 PB 级数据的成百上千台服务器上运行。
- 弹性 : Elasticsearch 运行在一个分布式的环境中,从设计之初就考虑到了这一点。
- 灵活性 : 具备多个案例场景。数字、文本、地理位置、结构化、非结构化。所有的数据类型都欢迎。
二、 ES的基本概念
1.1 索引(Index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
1.2 类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
1.3 文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
三者关系,如图中所示
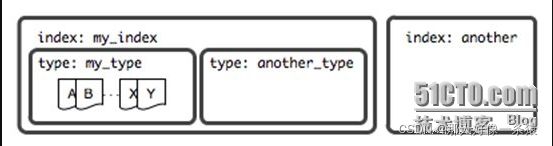
1.4 映射Mapping)
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。另外,ES还提供了额外功能,例如将域中的内容按需排序。事实上,ES也能自动根据其值确定域的类型。

1.5 节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。类似于集群,节点靠其名称进行标识,默认为启动时自动生成的随机Marvel字符名称。用户可以按需要自定义任何希望使用的名称,但出于管理的目的,此名称应该尽可能有较好的识别性。节点通过为其配置的ES集群名称确定其所要加入的集群。
1.6 分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。
ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。
ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
如图所示。

ElasticSearch的RESTful API通过tcp协议的9200端口提供,可通过任何趁手的客户端工具与此接口进行交互,这其中包括最为流行的curl。curl与ElasticSearch交互的通用请求格式如下面所示。
例如,查看ElasticSearch工作正常与否的信息。
![]()
与ElasticSearch集群交互时,其输出数据均为JSON格式,多数情况下,此格式的易读性较差。cat API会在交互时以类似于Linux上cat命令的格式对结果进行逐行输出,因此有着较JSON好些的可读性。调用cat API仅需要向“_cat”资源发起GET请求即可。具体使用方法请查阅官方文档。
- ES安装
安装JDK,至少1.8.0_73以上版本,java –version。

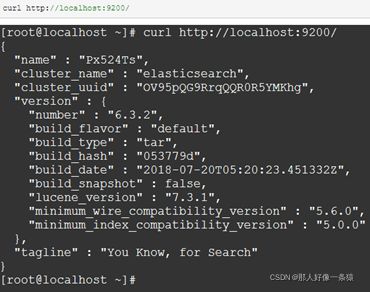
检查Elasticsearch是否正在运行:
四、 The Rest Api
4.1 集群健康

我们可以看到,我们命名为“elasticsearch”的集群现在是green状态。
无论何时我们请求集群健康时,我们会得到green, yellow, 或者 red 这三种状态。
- Green : everything is good(一切都很好)(所有功能正常)
- Yellow : 所有数据都是可用的,但有些副本还没有分配(所有功能正常)
- Red : 有些数据不可用(部分功能正常)
从上面的响应中我们可以看到,集群"elasticsearch"总共有1个节点,0个分片因为还没有数据。
下面看一下集群的节点列表:
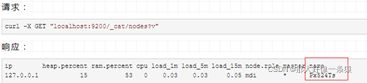
可以看到集群中只有一个节点,它的名字是“Px524Ts”。
4.2 查看全部索引

上面的输出意味着:我们在集群中没有索引。
4.3 创建一个索引
现在,我们创建一个名字叫“customer”的索引,然后查看索引:
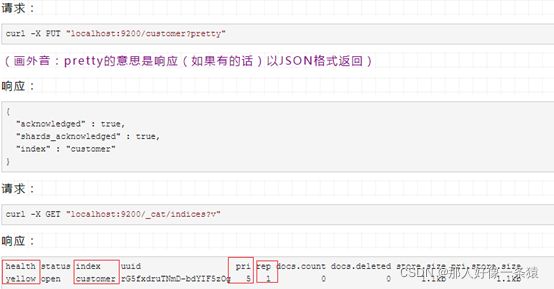
结果的第二行告诉我们,我们现在有叫"customer"的索引,并且他有5个主分片和1个副本(默认是1个副本),有0个文档。
可能你已经注意到这个"customer"索引的健康状态是yellow。回想一下我们之前的讨论,yellow意味着一些副本(尚未)被分配。
之所以会出现这种情况,是因为Elasticsearch默认情况下为这个索引创建了一个副本。由于目前我们只有一个节点在运行,所以直到稍后另一个节点加入集群时,才会分配一个副本(对于高可用性)。一旦该副本分配到第二个节点上,该索引的健康状态将变为green。
4.4 索引并查询一个文档
现在,让我们put一些数据到我们的"customer"索引:
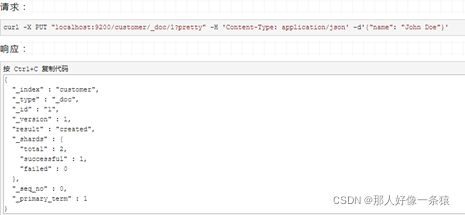
从上面的响应可以看到,我们在"customer"索引下成功创建了一个文档。这个文档还有一个内部id为1,这是我们在创建的时候指定的。
需要注意的是,Elasticsearch并不要求你在索引文档之前就先创建索引,然后才能将文档编入索引。在前面的示例中,如果事先不存在"customer"索引,Elasticsearch将自动创建"customer"索引(也就是说,在新建文档的时候如果指定的索引不存在则会自动创建相应的索引)。
现在,让我重新检索这个文档:
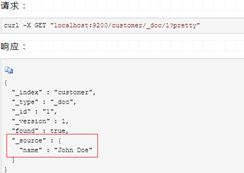
可以看到除了"found"字段外没什么不同,"_source"字段返回了一个完整的JSON文档。
4.5 删除一个索引
现在,让我们删除前面创建的索引,然后查看全部索引。
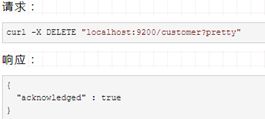
接下来,查看一下:

到现在为止,我们已经学习了创建/删除索引、索引/查询文档这四个命令:

如果我们仔细研究上面的命令,我们实际上可以看到如何在Elasticsearch中访问数据的模式。这种模式可以概括如下:
![]()
4.6 更新文档
事实上,每当我们执行更新时,Elasticsearch就会删除旧文档,然后索引一个新的文档。
下面这个例子展示了如何更新一个文档(ID为1),改变name字段为"Jane Doe",同时添加一个age字段:

下面这个例子用脚本来将age增加5;

在上面例子中,ctx._source引用的是当前源文档;
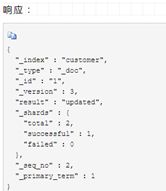
4.7 删除文档
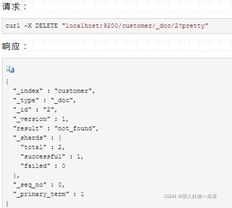
删除文档相当简单。这个例子展示了如何从"customer"索引中删除ID为2的文档:
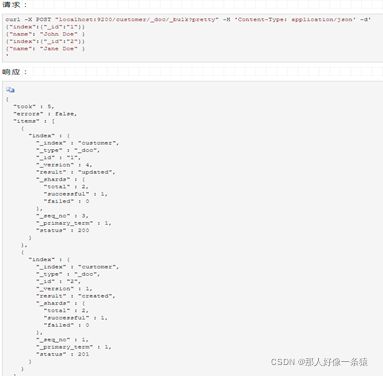
4.8 批处理
除了能够索引、更新和删除单个文档之外,Elasticsearch还可以使用_bulk API批量执行上述任何操作。
这个功能非常重要,因为它提供了一种非常有效的机制,可以在尽可能少的网络往返的情况下尽可能快地执行多个操作。
下面的例子,索引两个文档(ID 1 - John Doe 和 ID 2 - Jane Doe):
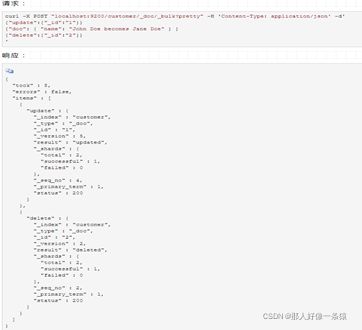
接下来的例子展示了,更新第一个文档(ID为1),删除第二个文档(ID为2):
现在,我们来重新查看一下索引文档:
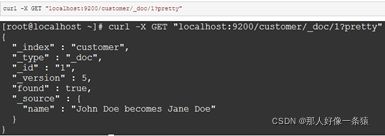
4.9 检索数据
现在我们已经了解了基础知识,让我们尝试处理一个更真实的数据集。我准备了一个关于客户银行账户信息的虚构JSON文档示例。每个文档都有以下格式:

加载示例数据:
你可以从https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json下载示例数据,取它到我们的当前目录,并且加载到我们的集群中:新建一个文件accounts.json,然后将数据复制粘贴到该文件中,保存退出。这个accounts.json文件所在目录下执行如下命令:
![]()
此时,accounts.json中的文档数据便被索引到"bank"索引下,我们查看一下索引:
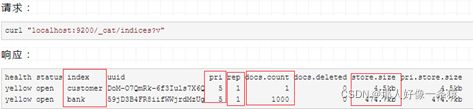
可以看到,现在我们的集群中有两个索引,分别是"customer"和"bank";"customer"索引,1个文档,"bank"索引有1000个文档。
4.10 The Search API
现在让我们从一些简单的搜索开始。运行搜索有两种基本方法:一种是通过REST请求URI发送检索参数,另一种是通过REST请求体发送检索参数(一种是把检索参数放在URL后面,另一种是放在请求体里面。相当于HTTP的GET和POST请求)。
请求体方法允许你更有表现力,也可以用更可读的JSON格式定义搜索。用于搜索的REST API可从_search端点访问。下面的例子返回"bank"索引中的所有文档。
![]()
让我们来剖析一下上面的请求:我们在"bank"索引中检索,q=*参数表示匹配所有文档;sort=account_number:asc表示每个文档的account_number字段升序排序;pretty参数表示返回漂亮打印的JSON结果。响应结果看起来是这样的:

可以看到,响应由下列几部分组成:
- took : Elasticsearch执行搜索的时间(以毫秒为单位)
- timed_out : 告诉我们检索是否超时
- _shards : 告诉我们检索了多少分片,以及成功/失败的分片数各是多少
- hits : 检索的结果
- hits.total : 符合检索条件的文档总数
- hits.hits : 实际的检索结果数组(默认为前10个文档)
- hits.sort : 排序的key(如果按分值排序的话则不显示)
- hits._score 和 max_score 现在我们先忽略这些字段
下面是一个和上面相同,但是用请求体的例子:

区别在于,我们没有在URI中传递q=*,而是向_search API提供json风格的查询请求体。很重要的一点是,一旦返回搜索结果,Elasticsearch就完全完成了对请求的处理,不会在结果中维护任何类型的服务器端资源或打开游标。这是许多其他平台如SQL形成鲜明对比。
4.11 查询语言
Elasticsearch提供了一种JSON风格的语言,您可以使用这种语言执行查询。这被成为查询DSL。查询语言非常全面,乍一看可能有些吓人,但实际上最好的学习方法是从几个基本示例开始。回到我们上一个例子,我们执行这样的查询:

查询部分告诉我们查询定义是什么,match_all部分只是我们想要运行的查询类型。这里match_all查询只是在指定索引中搜索所有文档。
除了查询参数外,我们还可以传递其他参数来影响搜索结果。在上面部分的例子中,我们传的是sort参数,这里我们传size:

注意:如果size没有指定,则默认是10。
下面的例子执行match_all,并返回第10到19条文档:

from参数(从0开始)指定从哪个文档索引开始,并且size参数指定从from开始返回多少条。这个特性在分页查询时非常有用。注意:如果没有指定from,则默认从0开始这个示例执行match_all,并按照帐户余额降序对结果进行排序,并返回前10个(默认大小)文档。

4.12 搜索
继续学习查询DSL。首先,让我们看一下返回的文档字段。默认情况下,会返回完整的JSON文档(PS:也就是返回所有字段),这被称为source。如果我们不希望返回整个源文档,我们可以从源文档中只请求几个字段来返回。下面的例子展示了只返回文档中的两个字段:account_number 和 balance字段:

(相当于SELECT account_number, balance FROM bank)。
现在让我们继续查询部分。以前,我们已经看到了如何使用match_all查询匹配所有文档。现在让我们引入一个名为match query的新查询,它可以被看作是基本的字段搜索查询(即针对特定字段或字段集进行的搜索)。
下面的例子返回account_number为20的文档:

(相当于SELECT * FROM bank WHERE account_number = 20)。
下面的例子返回address中包含"mill"的账户:

(相当于SELECT * FROM bank WHERE address LIKE '%mill%')。
下面的例子返回address中包含"mill"或者"lane"的账户:

(相当于SELECT * FROM bank WHERE address LIKE '%mill' OR address LIKE '%lane%')。
让我们来引入bool查询,bool查询允许我们使用布尔逻辑将较小的查询组合成较大的查询。
下面的例子将两个match查询组合在一起,返回address中包含"mill"和"lane"的账户:
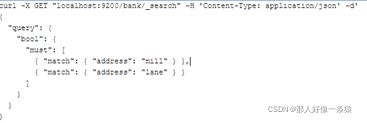
(相当于SELECT * FROM bank WHERE address LIKE '%mill%lane%')。
上面是bool must查询,下面这个是bool shoud查询:

(must相当于and,shoud相当于or,must_not相当于!);
(逻辑运算符:与/或/非,and/or/not,在这里就是must/should/must_not)。
我们可以在bool查询中同时组合must、should和must_not子句。此外,我们可以在任何bool子句中编写bool查询,以模拟任何复杂的多级布尔逻辑。
下面的例子是一个综合应用:

(相当于SELECT * FROM bank WHERE age LIKE '%40%' AND state NOT LIKE '%ID%')。
4.13 过滤
分数是一个数值,它是文档与我们指定的搜索查询匹配程度的相对度量(PS:相似度)。分数越高,文档越相关,分数越低,文档越不相关。
但是查询并不总是需要产生分数,特别是当它们仅用于“过滤”文档集时。Elasticsearch检测到这些情况并自动优化查询执行,以便不计算无用的分数。
我们在前一节中介绍的bool查询还支持filter子句,该子句允许使用查询来限制将由其他子句匹配的文档,而不改变计算分数的方式。
作为一个例子,让我们引入range查询,它允许我们通过一系列值筛选文档。这通常用于数字或日期过滤。
下面这个例子用一个布尔查询返回所有余额在20000到30000之间(包括30000,BETWEEN...AND...是一个闭区间)的账户。换句话说,我们想要找到余额大于等于20000并且小于等等30000的账户:

4.14 聚集
(相当于SQL中的聚集函数,比如分组、求和、求平均数之类的)。
首先,这个示例按state对所有帐户进行分组,然后按照count数降序(默认)返回前10条(默认):
(相当于按state分组,然后count(*),每个组中按照COUNT(*)数取 top 10)。
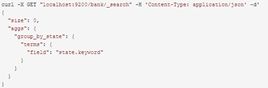
在SQL中,上面的聚集操作类似于:
![]()

注意,我们将size=0设置为不显示搜索结果,因为我们只想看到响应中的聚合结果。
接下来的例子跟上一个类似,按照state分组,然后取balance的平均值。
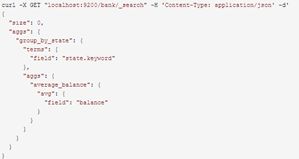
在SQL中,相当于:
![]()
下面这个例子展示了我们如何根据年龄段(20-29岁,30-39岁,40-49岁)来分组,然后根据性别分组,最后得到平均账户余额,每个年龄等级,每个性别:
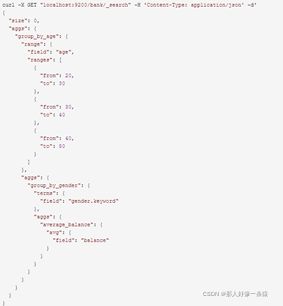
五、 ES的实现原理及索引原理
5.1 ES的实现原理
5.1.1 write(写)/create(创建)操作实现原理
当您向协调节点发送请求以索引新文档时,将执行以下操作:
- 所有在Elasticsearch集群中的节点都包含:有关哪个分片存在于哪个节点上的元数据。协调节点(coordinating node)使用文档ID(默认)将文档路由到对应的分片。Elasticsearch将文档ID以murmur3作为散列函数进行散列,并通过索引中的主分片数量进行取模运算,以确定文档应被索引到哪个分片。
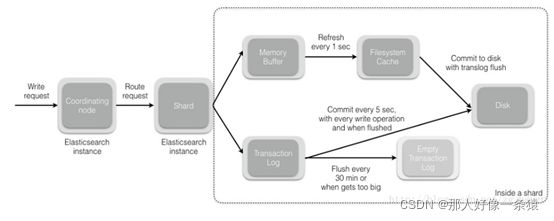
shard = hash(document_id) % (num_of_primary_shards) - 当节点接收到来自协调节点的请求时,请求被写入到translog(我们将在后续的post中间讲解translog),并将该文档添加到内存缓冲区。如果请求在主分片上成功,则请求将并行发送到副本分片。只有在所有主分片和副本分片上的translog被fsync’ed后,客户端才会收到该请求成功的确认。
- 内存缓冲区以固定的间隔刷新(默认为1秒),并将内容写入文件系统缓存中的新段。此分段的内容更尚未被fsync’ed(未被写入文件系统),分段是打开的,内容可用于搜索。
- translog被清空,并且文件系统缓存每隔30分钟进行一次fsync,或者当translog变得太大时进行一次fsync。这个过程在Elasticsearch中称为flush。在刷新过程中,内存缓冲区被清除,内容被写入新的文件分段(segment)。当文件分段被fsync’ed并刷新到磁盘,会创建一个新的提交点(其实就是会更新文件偏移量,文件系统会自动做这个操作)。旧的translog被删除,一个新的开始。
- 下图显示了写入请求和数据流程:
5.1.2 Update和Delete实现原理
删除和更新操作也是写操作。但是,Elasticsearch中的文档是不可变的(immutable),因此不能删除或修改。那么,如何删除/更新文档呢?
磁盘上的每个分段(segment)都有一个.del文件与它相关联。当发送删除请求时,该文档未被真正删除,而是在.del文件中标记为已删除。此文档可能仍然能被搜索到,但会从结果中过滤掉。当分段合并时(我们将在后续的帖子中包括段合并),在.del文件中标记为已删除的文档不会被包括在新的合并段中。
现在,我们来看看更新是如何工作的。创建新文档时,Elasticsearch将为该文档分配一个版本号。对文档的每次更改都会产生一个新的版本号。当执行更新时,旧版本在.del文件中被标记为已删除,并且新版本在新的分段中编入索引。旧版本可能仍然与搜索查询匹配,但是从结果中将其过滤掉。
indexed/updated文档后,我们希望执行搜索请求。我们来看看如何在Elasticsearch中执行搜索请求。
5.1.3 Read的实现原理
读操作由两个阶段组成:
- 查询阶段(Query Phase)
- 获取阶段(Fetch Phase)
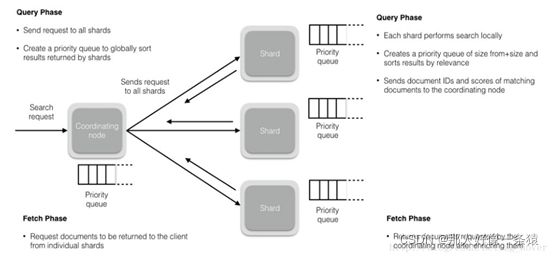
5.1.4 查询阶段(Query Phase)
在此阶段,协调节点将搜索请求路由到索引(index)中的所有分片(shards)(包括:主要或副本)。分片独立执行搜索,并根据相关性分数创建一个优先级排序结果(稍后我们将介绍相关性分数)。所有分片将匹配的文档和相关分数的文档ID返回给协调节点。协调节点创建一个新的优先级队列,并对全局结果进行排序。可以有很多文档匹配结果,但默认情况下,每个分片将前10个结果发送到协调节点,协调创建优先级队列,从所有分片中分选结果并返回前10个匹配。
5.1.5 获取阶段(Fetch Phase)
在协调节点对所有结果进行排序,已生成全局排序的文档列表后,它将从所有分片请求原始文档。
所有的分片都会丰富文档并将其返回到协调节点。
5.2 ES的索引原理
Elasticsearch最关键的就是提供强大的索引能力了,Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能。
为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如上面例子中的name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默的为这些字段建立索引--倒排索引,因为Elasticsearch最核心功能是搜索。
5.2.1 倒排索引

假设有这么几条数据:
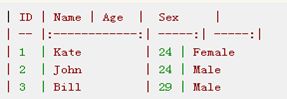
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
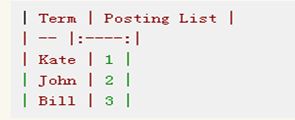
Age:
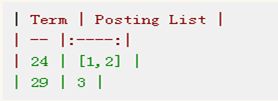
Sex:
5.2.1.1 Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
5.2.1.2 Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
5.2.1.3 Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
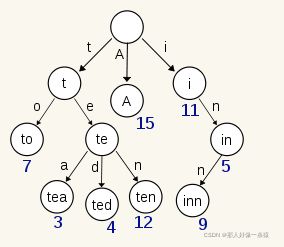
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
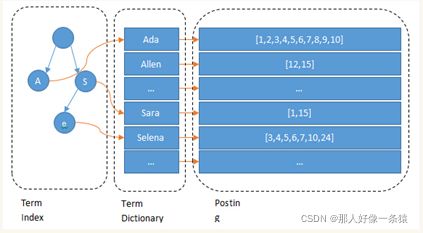
所以erm index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
5.2.2 压缩技巧
上面说到用FST压缩term index外,对posting list也有压缩技巧。我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对这些文档id压缩的呢?
5.2.2.1 Frame Of Reference
原理:增量编码压缩,将大数变小数,按字节存储。
首先,Elasticsearch要求posting list是有序的(为了提高搜索的性能,),这样做的一个好处是方便压缩,看下面这个图例:
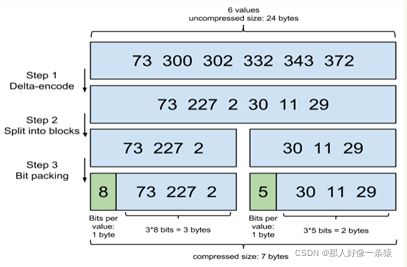
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
5.2.2.2 Roaring bitmaps
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
5.3 联合索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?
- 利用跳表(Skip list)的数据结构快速做“与”运算,或者
- 利用上面提到的bitset按位“与”
先看看跳表的数据结构:

将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如55,先找到level2的31,再找到level1的47,最后找到55,一共3次查找,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引:
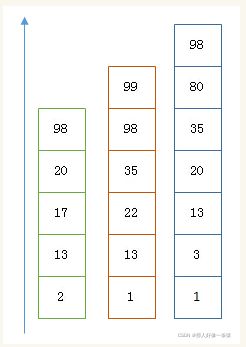
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
- 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
- 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
六、Java Api
6.1 Java Api连接ES客户端初始化
6.1.1 RestClient

6.1.2 TransportClient
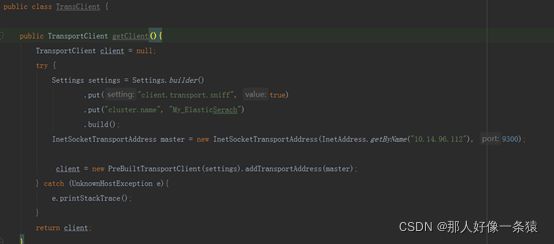
6.1.3 JestClient
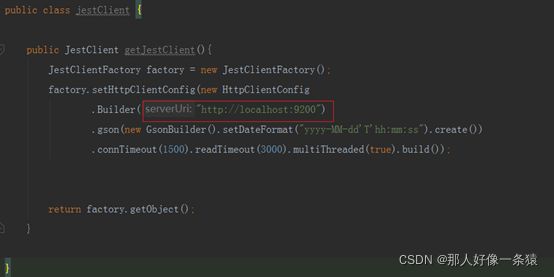
6.2 添加索引
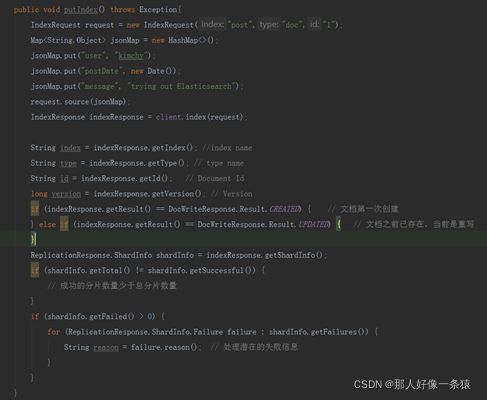
在添加索引时,有版本冲突的话,会抛出ElasticsearchException错误。
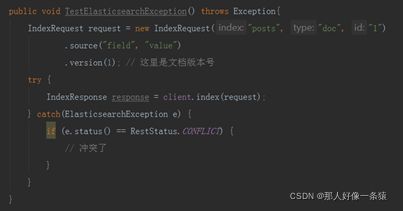
如果将onType设置为create,, 而且如果索引的文档与已存在的文档在 index, type 和 id 上均相同,也会抛出冲突异常。

6.3 索引查找
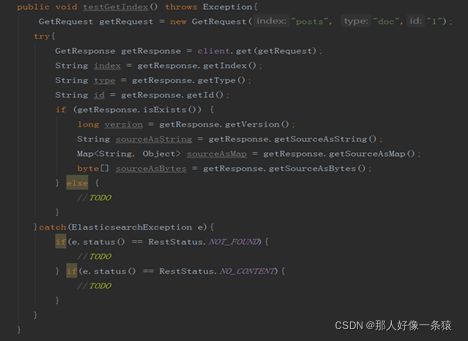
6.4 索引删除
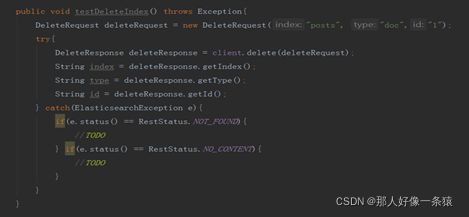
6.5 根据索引更新文档内容
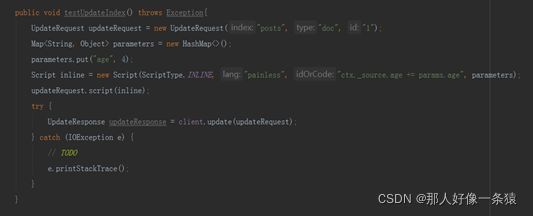
6.6 Bulk Api
bulk接口是批量index/update/delete操作,在API中,只需要一个bulk request就可以完成一批请求。并且不同类型的request可以写在同一个bulk request里。(注意:Bulk API只接受JSON和SMILE格式.其他格式的数据将会报错)。
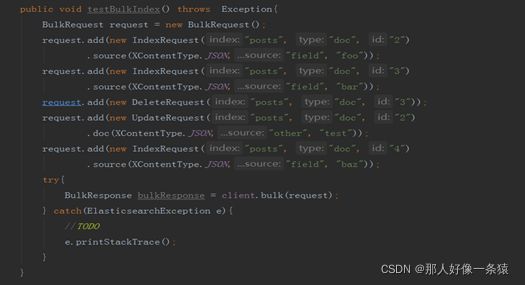
6.7 Search Api
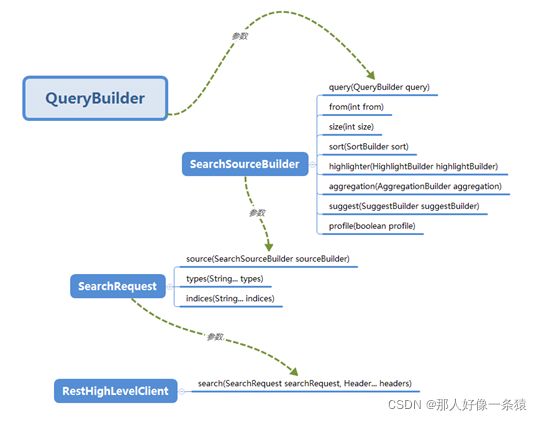
6.8 Search Api查询关系
附件:索引增删改查demo。
package com.hikvision.demo;
import io.searchbox.indices.DeleteIndex;
import org.apache.http.HttpHost;
import org.elasticsearch.ElasticsearchException;
import org.elasticsearch.action.DocWriteRequest;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.bulk.BackoffPolicy;
import org.elasticsearch.action.bulk.BulkProcessor;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.*;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.ShardSearchFailure;
import org.elasticsearch.action.support.replication.ReplicationResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.unit.ByteSizeUnit;
import org.elasticsearch.common.unit.ByteSizeValue;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.search.MultiMatchQuery;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.script.Script;
import org.elasticsearch.script.ScriptType;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.FieldSortBuilder;
import org.elasticsearch.search.sort.ScoreSortBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.search.suggest.SuggestBuilder;
import org.elasticsearch.search.suggest.SuggestBuilders;
import org.elasticsearch.search.suggest.SuggestionBuilder;
import org.elasticsearch.threadpool.ThreadPool;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.net.InetAddress;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
public class OperationIndex {
private static final Logger LOG = LoggerFactory.getLogger(OperationIndex.class);
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("10.14.96.112",9200,"https"))
.build());
public void putIndex() throws Exception{
IndexRequest request = new IndexRequest("post","doc","1");
Map jsonMap = new HashMap<>();
jsonMap.put("user", "kimchy");
jsonMap.put("postDate", new Date());
jsonMap.put("message", "trying out Elasticsearch");
request.source(jsonMap);
IndexResponse indexResponse = client.index(request);
String index = indexResponse.getIndex(); //index name
String type = indexResponse.getType(); // type name
String id = indexResponse.getId(); // Document Id
long version = indexResponse.getVersion(); // Version
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) { // 文档第一次创建
} else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) { // 文档之前已存在,当前是重写
}
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
// 成功的分片数量少于总分片数量
}
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
String reason = failure.reason(); // 处理潜在的失败信息
}
}
}
public void TestElasticsearchException() throws Exception{
IndexRequest request = new IndexRequest("posts", "doc", "1")
.source("field", "value")
.version(1); // 这里是文档版本号
try {
IndexResponse response = client.index(request);
} catch(ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
// 冲突了
}
}
}
public void TestCreateElasticsearchException() throws Exception{
IndexRequest request = new IndexRequest("posts", "doc", "1")
.source("field", "value")
.opType(DocWriteRequest.OpType.CREATE);
try {
IndexResponse response = client.index(request);
} catch(ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
}
}
}
public void testGetIndex() throws Exception{
GetRequest getRequest = new GetRequest("posts", "doc","1");
try{
GetResponse getResponse = client.get(getRequest);
String index = getResponse.getIndex();
String type = getResponse.getType();
String id = getResponse.getId();
if (getResponse.isExists()) {
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString();
Map sourceAsMap = getResponse.getSourceAsMap();
byte[] sourceAsBytes = getResponse.getSourceAsBytes();
} else {
//TODO
}
}catch(ElasticsearchException e){
if(e.status() == RestStatus.NOT_FOUND){
//TODO
} if(e.status() == RestStatus.NO_CONTENT){
//TODO
}
}
}
public void testDeleteIndex() throws Exception{
DeleteRequest deleteRequest = new DeleteRequest("posts", "doc","1");
try{
DeleteResponse deleteResponse = client.delete(deleteRequest);
String index = deleteResponse.getIndex();
String type = deleteResponse.getType();
String id = deleteResponse.getId();
} catch(ElasticsearchException e){
if(e.status() == RestStatus.NOT_FOUND){
//TODO
} if(e.status() == RestStatus.NO_CONTENT){
//TODO
}
}
}
public void testUpdateIndex() throws Exception{
UpdateRequest updateRequest = new UpdateRequest("posts", "doc", "1");
Map parameters = new HashMap<>();
parameters.put("age", 4);
Script inline = new Script(ScriptType.INLINE, "painless", "ctx._source.age += params.age", parameters);
updateRequest.script(inline);
try {
UpdateResponse updateResponse = client.update(updateRequest);
} catch (IOException e) {
// TODO
e.printStackTrace();
}
}
public void testUpdateIndexForString() throws Exception{
UpdateRequest updateRequest = new UpdateRequest("posts", "doc", "1");
String jsonString = "{" +
"\"updated\":\"2017-01-02\"," +
"\"reason\":\"easy update\"" +
"}";
updateRequest.doc(jsonString, XContentType.JSON);
try {
client.update(updateRequest);
} catch (IOException e) {
// TODO
e.printStackTrace();
}
}
public void testUpdateIndexForMap() throws Exception{
Map jsonMap = new HashMap<>();
jsonMap.put("updated", new Date());
jsonMap.put("reason", "dailys update");
UpdateRequest updateRequest = new UpdateRequest("posts", "doc", "1").doc(jsonMap);
try {
client.update(updateRequest);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void testUpdateIndexForXContentBuilder() throws Exception{
try {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("updated", new Date());
System.out.println(new Date());
builder.field("reason", "daily update");
}
builder.endObject();
UpdateRequest request = new UpdateRequest("posts", "doc", "1")
.doc(builder);
client.update(request);
} catch (IOException e) {
// TODO
}
}
public void testUpdateIndexForKeyValue() throws Exception{
try {
UpdateRequest request = new UpdateRequest("posts", "doc", "1")
.doc("updated", new Date(),
"reason", "daily updatesss");
client.update(request);
} catch (IOException e) {
// TODO: handle exception
}
}
public void testBulkIndex() throws Exception{
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("posts", "doc", "2")
.source(XContentType.JSON,"field", "foo"));
request.add(new IndexRequest("posts", "doc", "3")
.source(XContentType.JSON,"field", "bar"));
request.add(new DeleteRequest("posts", "doc", "3"));
request.add(new UpdateRequest("posts", "doc", "2")
.doc(XContentType.JSON,"other", "test"));
request.add(new IndexRequest("posts", "doc", "4")
.source(XContentType.JSON,"field", "baz"));
try{
BulkResponse bulkResponse = client.bulk(request);
} catch(ElasticsearchException e){
//TODO
e.printStackTrace();
}
}
public void testBulkProcessorIndex() throws Exception{
Settings settings = Settings.EMPTY;
ThreadPool threadPool = new ThreadPool(settings); //构建新的线程池
BulkProcessor.Listener listener = new BulkProcessor.Listener() {
//构建bulk listener
@Override
public void beforeBulk(long executionId, BulkRequest request) {
//重写beforeBulk,在每次bulk request发出前执行,在这个方法里面可以知道在本次批量操作中有多少操作数
int numberOfActions = request.numberOfActions();
LOG.debug("Executing bulk [{}] with {} requests", executionId, numberOfActions);
}
@Override
public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
//重写afterBulk方法,每次批量请求结束后执行,可以在这里知道是否有错误发生。
if (response.hasFailures()) {
LOG.warn("Bulk [{}] executed with failures", executionId);
} else {
LOG.debug("Bulk [{}] completed in {} milliseconds", executionId, response.getTook().getMillis());
}
}
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
//重写方法,如果发生错误就会调用。
LOG.error("Failed to execute bulk", failure);
}
};
BulkProcessor.Builder builder = new BulkProcessor.Builder(client::bulkAsync, listener, threadPool);//使用builder做批量操作的控制
BulkProcessor bulkProcessor = builder.build();
//在这里调用build()方法构造bulkProcessor,在底层实际上是用了bulk的异步操作
builder.setBulkActions(500); //执行多少次动作后刷新bulk.默认1000,-1禁用
builder.setBulkSize(new ByteSizeValue(1L, ByteSizeUnit.MB));//执行的动作大小超过多少时,刷新bulk。默认5M,-1禁用
builder.setConcurrentRequests(0);//最多允许多少请求同时执行。默认是1,0是只允许一个。
builder.setFlushInterval(TimeValue.timeValueSeconds(10L));//设置刷新bulk的时间间隔。默认是不刷新的。
builder.setBackoffPolicy(BackoffPolicy.constantBackoff(TimeValue.timeValueSeconds(1L), 3)); //设置补偿机制参数。由于资源限制(比如线程池满),批量操作可能会失败,在这定义批量操作的重试次数。
//新建三个 index 请求
IndexRequest one = new IndexRequest("posts", "doc", "1").
source(XContentType.JSON, "title", "In which order are my Elasticsearch queries executed?");
IndexRequest two = new IndexRequest("posts", "doc", "2")
.source(XContentType.JSON, "title", "Current status and upcoming changes in Elasticsearch");
IndexRequest three = new IndexRequest("posts", "doc", "3")
.source(XContentType.JSON, "title", "The Future of Federated Search in Elasticsearch");
//新的三条index请求加入到上面配置好的bulkProcessor里面。
bulkProcessor.add(one);
bulkProcessor.add(two);
bulkProcessor.add(three);
// add many request here.
//bulkProcess必须被关闭才能使上面添加的操作生效
bulkProcessor.close(); //立即关闭
//关闭bulkProcess的两种方法:
try {
//2.调用awaitClose.
//简单来说,就是在规定的时间内,是否所有批量操作完成。全部完成,返回true,未完成返//回false
boolean terminated = bulkProcessor.awaitClose(30L, TimeUnit.SECONDS);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void testSearchIndex() throws Exception{
SearchRequest searchRequest = new SearchRequest();
// 设置搜索的 type
searchRequest.types("doc");
// 配置搜索时偏爱使用本地分片,默认是使用随机分片
searchRequest.preference("_local");
// 设置 routing 参数
searchRequest.routing("routing");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryBuilder queryBuilder = QueryBuilders.matchQuery("user", "kimchy");
//是否模糊查询
((MatchQueryBuilder) queryBuilder).fuzziness(Fuzziness.AUTO);
//设置前缀长度
((MatchQueryBuilder) queryBuilder).prefixLength(3);
//设置最大膨胀系数
((MatchQueryBuilder) queryBuilder).maxExpansions(10);
//设置查询
sourceBuilder.query(queryBuilder);
//设置从那里开始
sourceBuilder.from(0);
//每页5条
sourceBuilder.size(5);
//设置超时时间
sourceBuilder.timeout(new TimeValue(60,TimeUnit.SECONDS));
// 根据分数 _score 降序排列 (默认行为)
sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));
// 根据 id 降序排列
sourceBuilder.sort(new FieldSortBuilder("_id").order(SortOrder.DESC));
//默认情况下,查询请求会返回文档的内容,配置禁止对_source的获取
sourceBuilder.fetchSource(false);
//使用通配符模式以更细的粒度包含或排除特定的字段:
String[] includeFields = new String[] {"title", "user", "innerObject.*"};
String[] excludeFields = new String[] {"_type"};
sourceBuilder.fetchSource(includeFields,excludeFields);
//设置结果的高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
// title 字段高亮
HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title");
// 配置高亮类型
highlightTitle.highlighterType("unified");
//添加到builder
highlightBuilder.field(highlightTitle);
//user字段高亮
HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");
highlightBuilder.field(highlightUser);
sourceBuilder.highlighter(highlightBuilder);
//聚合请求
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company").field("company.keyword");
aggregation.subAggregation(AggregationBuilders.avg("average_age").field("age"));
sourceBuilder.aggregation(aggregation);
//建议请求
SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.termSuggestion("user").text("kmichy");
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder);
sourceBuilder.suggest(suggestBuilder);
//对请求和聚合分析,将profile标志位设置为true
sourceBuilder.profile(true);
try{
SearchResponse searchResponse = client.search(searchRequest.source(sourceBuilder));
// HTTP 状态码
RestStatus status = searchResponse.status();
// 查询占用的时间
TimeValue took = searchResponse.getTook();
// 是否由于 SearchSourceBuilder 中设置 terminateAfter 而过早终止
boolean terminatedEarly = searchResponse.isTerminatedEarly();
//是否超时
boolean timeOut = searchResponse.isTimedOut();
//分片总数量
int totalShards = searchResponse.getTotalShards();
//成功的分片
int successfulShards = searchResponse.getSuccessfulShards();
//失败的分片
int failureShards = searchResponse.getFailedShards();
for(ShardSearchFailure failure : searchResponse.getShardFailures()){
//TODO
}
//获取SearchHits,访问返回的文档
SearchHits hits = searchResponse.getHits();
//查询命中的数量
long totalHits = hits.getTotalHits();
//最大分值
float maxScore = hits.getMaxScore();
//遍历循环获取结果
SearchHit[] searchHits = hits.getHits();
for(SearchHit hit : searchHits){
//TODO
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
Map sourceAsMap = hit.getSourceAsMap();
String documentTitle = (String)sourceAsMap.get("title");
List