CUDA编程入门
参考:CUDA编程原理1
CUDA编程原理2
矩阵乘法
我们用host指代CPU及其内存,而用device指代GPU及其内存。
- global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
- device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
- host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
1.CUDA的整体结构
kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<
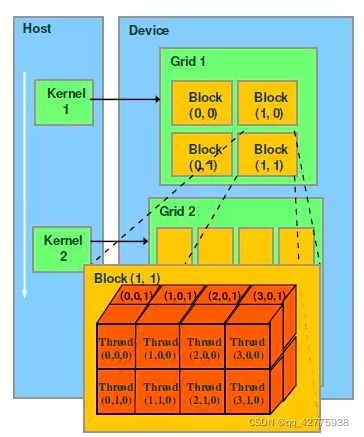
从上图可以看出每一个block可以组织成三维的,但其实block可以1维、2维或3维组织。Grid可以1维、2维组织。
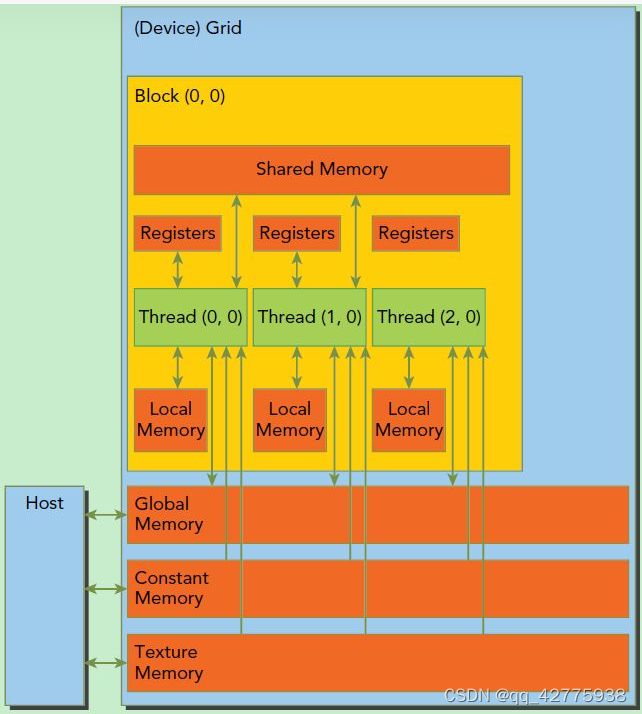
2.CUDA内存模型
如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。
3. Streaming Multiprocessor,SM
SM是GPU的处理器,SM可以并发地执行数百个线程。
- 当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。
- SM一般可以调度多个线程块,一个kernel的各个线程块可能被分配多个SM。
- 当线程块被划分到某个SM上时,它将被进一步划分为多个线程束(一个线程束包含32个线程),因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的
- 由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
SM中包含多个SP,一个GPU可以有多个SM(比如16个),最终一个GPU可能包含有上千个SP。
每个线程由每个线程处理器(SP)执行
线程块由多核处理器(SM)执行
一个kernel其实由一个grid来执行,一个kernel一次只能在一个GPU上执行
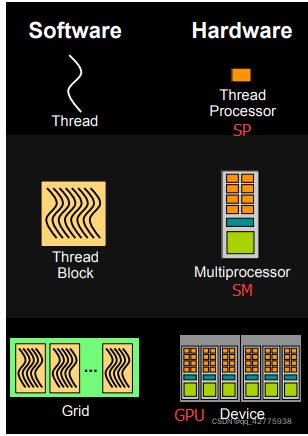
block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行
4.cuda编程的相关函数
- 在device上申请一定字节大小的显存:
cudaMalloc(void** devPtr, size_t size); // 在device上申请一定字节大小的显存
// devPtr是指向所分配内存的指针
// 与cudaFree函数配合使用
- 内存和显存之间的数据拷贝:
cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind);
src指向数据源,而dst是目标区域,count是复制的字节数,其中kind控制复制的方向:cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost及cudaMemcpyDeviceToDevice,如cudaMemcpyHostToDevice将host上数据拷贝到device上。
- 获取线程的id
我们可以用dim3类来表示网格和线程块的组织方式,网格grid可以表示为一维和二维格式,线程块block可以表示为一维、二维和三维的数据格式。
dim3 DimGrid(100, 50); //5000个线程块,维度是100*50
dim3 DimBlock(4, 8, 8); //每个线层块内包含256个线程,线程块内的维度是4*8*8**
最常见的组织方式如下:
dim3 dimGrid(M, N);
dim3 dimBlock(P, Q);
threadId.x = blockIdx.x*blockDim.x+threadIdx.x; // x轴方向上的id号
threadId.y = blockIdx.y*blockDim.y+threadIdx.y; // y轴方向上的id号
5.实现矩阵乘法
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include一致
matrix_mul_gpu << <blockNumber, threadPerBlock >> > (d_dataA, d_dataB, d_dataC, Col);
//拷贝计算数据-一级数据指针
cudaMemcpy(C, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost);
//释放内存
free(A);
free(B);
free(C);
cudaFree(d_dataA);
cudaFree(d_dataB);
cudaFree(d_dataC);
GPUend = clock();
int GPUtime = GPUend - GPUstart;
printf("GPU运行时间:%d\n", GPUtime );
// CPU计算
clock_t CPUstart, CPUend, CPUresult;
int *A2 = (int *)malloc(sizeof(int) * Row * Col);
int *B2 = (int *)malloc(sizeof(int) * Row * Col);
int *C2 = (int *)malloc(sizeof(int) * Row * Col);
//set value
for (int i = 0; i < Row*Col; i++) {
A2[i] = 90;
B2[i] = 10;
}
CPUstart = clock();
matrix_mul_cpu(A2, B2, C2, Col);
CPUend = clock();
int CPUtime = CPUend - CPUstart;
printf("CPU运行时间:%d\n", CPUtime);
printf("加速比为:%lf\n",double(CPUtime)/GPUtime);
return 0;
}
【注】.cu文件好像只能以英文命名,不然可能出错