大数据系统与大规模数据分析--第二次作业操作,hadoop编程、同步图计算
大数据第二次作业操作
大家好,我是【豆干花生】,这次我带来了大数据的第二次实践作业~
主要内容为hadoop编程,使用GraphLite进行同步图计算
可以说十分具体了,包含了具体操作、代码指令、各个步骤截图。
文章目录
- 大数据第二次作业操作
-
- 一.作业内容
- 二.第一个作业--hadoop编程
-
- 1.具体代码如下:
- 2.准备工作:
- 3.具体操作
- 三.第二个作业--同步图计算,SSSP
-
- 1.具体代码
- 2.准备工作
- 3.具体操作
- 完成!
一.作业内容

两个作业:hadoop编程实现wordcount功能,以及同步图实现pagerank运算


同步图我选择的是group0:sssp这个作业


二.第一个作业–hadoop编程
1.具体代码如下:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// Modified by Shimin Chen to demonstrate functionality for Homework 2
// April-May 2015
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Hw2Part1 {
// This is the Mapper class
// reference: http://hadoop.apache.org/docs/r2.6.0/api/org/apache/hadoop/mapreduce/Mapper.html
//
public static class TokenizerMapper
extends Mapper<Object, Text, Text, FloatWritable>{
private Text word = new Text();
private FloatWritable duration = new FloatWritable();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException
{
String[] vals = value.toString().split("\\s+");
if (vals.length != 3)
return;
try
{
duration.set(Float.parseFloat(vals[2]));
}
catch(NumberFormatException e)
{
return;
}
word.set(vals[0] + " " + vals[1]);
context.write(word, duration);
}
}
// This is the Reducer class
// reference http://hadoop.apache.org/docs/r2.6.0/api/org/apache/hadoop/mapreduce/Reducer.html
//
// We want to control the output format to look at the following:
//
// count of word = count
//
public static class CountAvgReducer
extends Reducer<Text,FloatWritable,Text,Text> {
private Text result_key= new Text();
private Text result_value= new Text();
public void reduce(Text key, Iterable<FloatWritable> values,
Context context
) throws IOException, InterruptedException {
float sum = 0;
int count = 0;
float avg = 0;
String spaceStr = " ";
for (FloatWritable val : values) {
sum += val.get();
count ++;
}
avg = sum/count;
String avgStr = String.format("%.3f", avg);
// generate result key
result_key.set(key);
// generate result value
result_value.set(Integer.toString(count));
result_value.append(spaceStr.getBytes(), 0, spaceStr.length());
result_value.append(avgStr.getBytes(), 0, avgStr.length());
context.write(result_key, result_value);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: " );
System.exit(2);
}
// key and value seperate by space, not tab.
conf.set("mapreduce.output.textoutputformat.separator", " ");
System.out.println(otherArgs[0]);
System.out.println(otherArgs[1]);
Job job = Job.getInstance(conf, "Hw2Part1");
job.setJarByClass(Hw2Part1.class);
job.setMapperClass(TokenizerMapper.class);
//job.setCombinerClass(IntSumCombiner.class);
job.setReducerClass(CountAvgReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// add the input paths as given by command line
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// add the output path as given by the command line
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[1]));
System.out.println(otherArgs[0]);
System.out.println(otherArgs[1]);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.准备工作:
之前已经配置好对应的软件啦
先打开docker desktop及内部对应的容器:
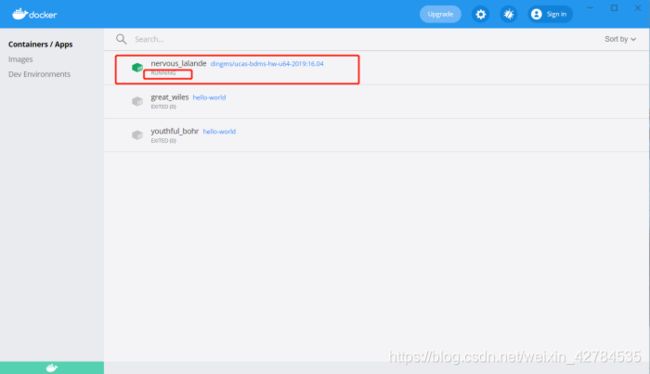
再在vscode里进入到对应的文件夹:
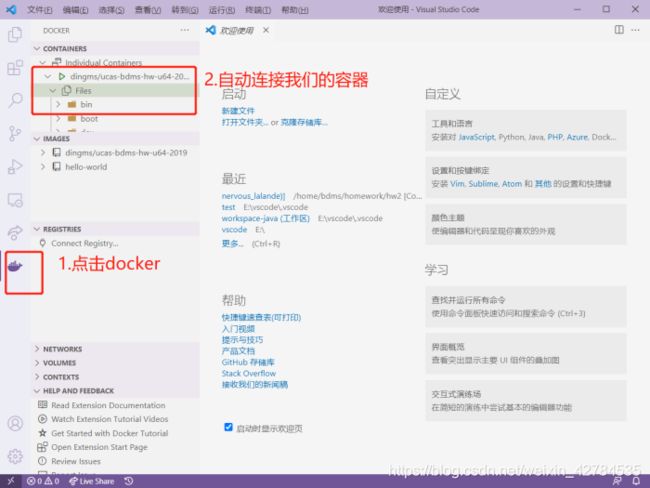
打开docker之后,在vscode中ctrl+shift+p,出现命令行,之后attach to running container。
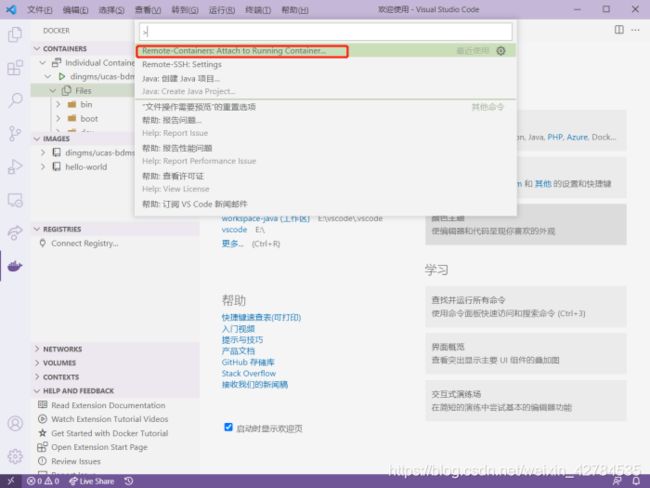
选择我们需要的容器:
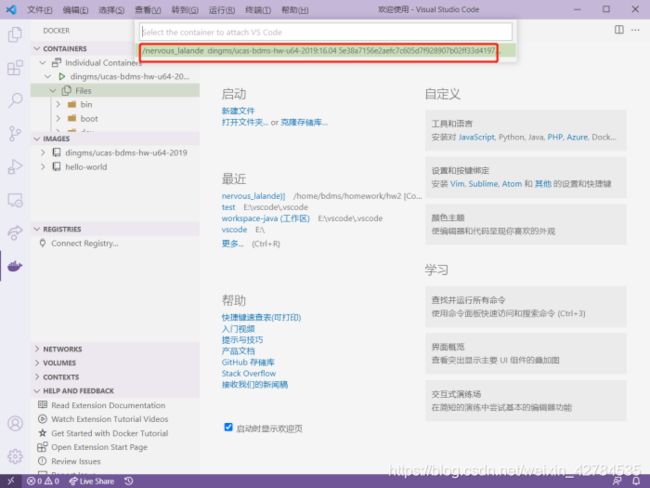
进入新的页面后,我们可以添加我们需要的文件夹到工作区(我之前已经添加):

选择左上角的文件,点击“将文件夹添加到工作区”,然后输入对应的文件夹就好了:
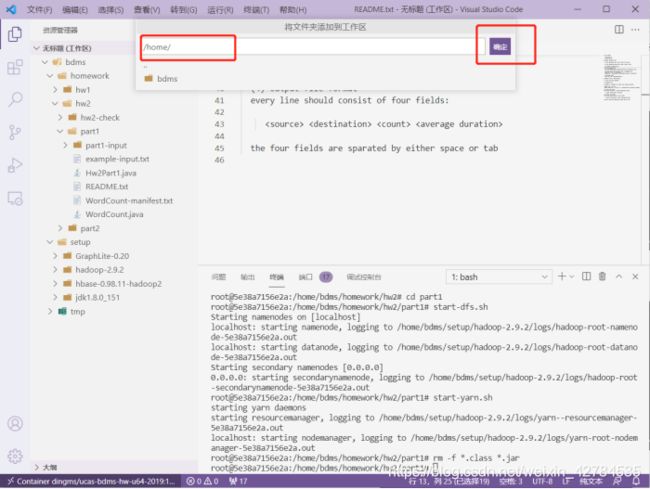
3.具体操作
打开终端:

在vscode下方的终端内操作,如果没有进入hw2的part1,要先通过cd进入。
打开readme.txt来查看怎末操作:
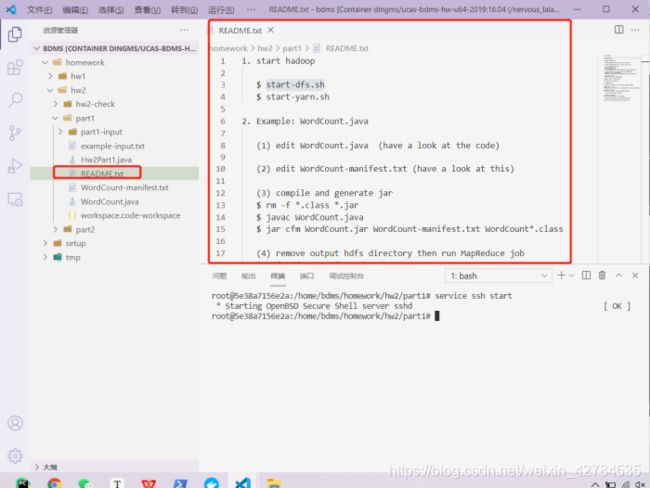
0. start ssh
$ service ssh start
1. start hadoop
$ start-dfs.sh
$ start-yarn.sh
2. Example: WordCount.java
(1) edit WordCount.java (have a look at the code)
(2) edit WordCount-manifest.txt (have a look at this)
(3) compile and generate jar
$ rm -f *.class *.jar
$ javac WordCount.java
$ jar cfm WordCount.jar WordCount-manifest.txt WordCount*.class
(4) remove output hdfs directory then run MapReduce job
$ hdfs dfs -rm -f -r /hw2/output
$ hadoop jar ./WordCount.jar /hw2/example-input.txt /hw2/output
(5) display output
$ hdfs dfs -cat '/hw2/output/part-*'
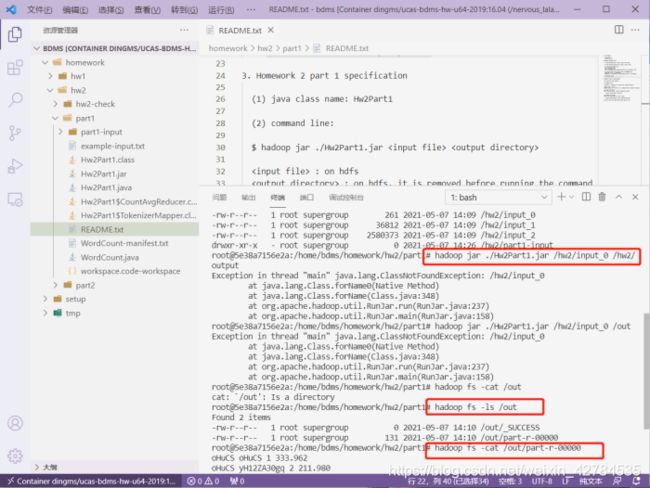
3. Homework 2 part 1 specification
(1) java class name: Hw2Part1
(2) command line:
$ hadoop jar ./Hw2Part1.jar 终端操作如下:
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# service ssh start
* Starting OpenBSD Secure Shell server sshd [ OK ]
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# start-dfs.sh
Starting namenodes on [localhost]
localhost: namenode running as process 4299. Stop it first.
localhost: datanode running as process 4480. Stop it first.
Starting secondary namenodes [0.0.0.0]
0.0.0.0: secondarynamenode running as process 4715. Stop it first.
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# start-yarn.sh
starting yarn daemons
resourcemanager running as process 5036. Stop it first.
localhost: nodemanager running as process 5158. Stop it first.
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# rm -f *.class *.jar
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# javac Hw2Part1.java
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# jar cfm Hw2Part1.jar WordCount-manifest.txt Hw2Part1*.class
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hdfs dfs -rm -f -r /hw2/output
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop fs -put part1-input/ /hw2put: `/hw2/part1-input/input_0': File exists
put: `/hw2/part1-input/input_1': File exists
put: `/hw2/part1-input/input_2': File exists
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop fs -ls /hw2Found 4 items
-rw-r--r-- 1 root supergroup 261 2021-05-07 14:09 /hw2/input_0
-rw-r--r-- 1 root supergroup 36812 2021-05-07 14:09 /hw2/input_1
-rw-r--r-- 1 root supergroup 2580373 2021-05-07 14:09 /hw2/input_2
drwxr-xr-x - root supergroup 0 2021-05-07 14:26 /hw2/part1-input
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop jar ./Hw2Part1.jar /hw2/input_0 /hw2/output
Exception in thread "main" java.lang.ClassNotFoundException: /hw2/input_0
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:237)
at org.apache.hadoop.util.RunJar.main(RunJar.java:158)
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop jar ./Hw2Part1.jar /hw2/input_0 /outException in thread "main" java.lang.ClassNotFoundException: /hw2/input_0
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:237)
at org.apache.hadoop.util.RunJar.main(RunJar.java:158)
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop fs -cat /outcat: `/out': Is a directory
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop fs -ls /outFound 2 items
-rw-r--r-- 1 root supergroup 0 2021-05-07 14:10 /out/_SUCCESS
-rw-r--r-- 1 root supergroup 131 2021-05-07 14:10 /out/part-r-00000
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hadoop fs -cat /out/part-r-00000oHuCS oHuCS 1 333.962
oHuCS yH12ZA30gq 2 211.980
sb4tF0D0 oHuCS 2 380.608
sb4tF0D0 sb4tF0D0 1 38.819
sb4tF0D0 yH12ZA30gq 4 299.914
root@5e38a7156e2a:/home/bdms/homework/hw2/part1# hdfs dfs -cat /out/part-r-00000
oHuCS oHuCS 1 333.962
oHuCS yH12ZA30gq 2 211.980
sb4tF0D0 oHuCS 2 380.608
sb4tF0D0 sb4tF0D0 1 38.819
sb4tF0D0 yH12ZA30gq 4 299.914
root@5e38a7156e2a:/home/bdms/homework/hw2/part1#
打开ssh和hadoop,删除之前的中间文件,生成.class和jar包,将input文件存入hdfs

生成对应结果,并展示对应结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kBCVFSFS-1628671095988)(C:\Users\YUANMU\AppData\Roaming\Typora\typora-user-images\image-20210508162633956.png)]](http://img.e-com-net.com/image/info8/3ae96a1ee37a48c586afdf09eca602b2.jpg)
三.第二个作业–同步图计算,SSSP

1.具体代码
/**
* @file PageRankVertex.cc
* @author Songjie Niu, Shimin Chen
* @version 0.1
*
* @section LICENSE
*
* Copyright 2016 Shimin Chen ([email protected]) and
* Songjie Niu ([email protected])
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
* @section DESCRIPTION
*
* This file implements the PageRank algorithm using graphlite API.
*
*/
#include
#include
#include
#include "GraphLite.h"
#define VERTEX_CLASS_NAME(name) SSSP##name
#define EPS 1e-6
unsigned long long startVertex = 0;
class VERTEX_CLASS_NAME(InputFormatter): public InputFormatter {
public:
int64_t getVertexNum() {
unsigned long long n;
sscanf(m_ptotal_vertex_line, "%lld", &n);
m_total_vertex= n;
return m_total_vertex;
}
int64_t getEdgeNum() {
unsigned long long n;
sscanf(m_ptotal_edge_line, "%lld", &n);
m_total_edge= n;
return m_total_edge;
}
int getVertexValueSize() {
m_n_value_size = sizeof(double);
return m_n_value_size;
}
int getEdgeValueSize() {
m_e_value_size = sizeof(double);
return m_e_value_size;
}
int getMessageValueSize() {
m_m_value_size = sizeof(double);
return m_m_value_size;
}
void loadGraph() {
unsigned long long last_vertex;
unsigned long long from;
unsigned long long to;
double weight = 0;
double value = 0;
int outdegree = 0;
const char *line= getEdgeLine();
// Note: modify this if an edge weight is to be read
// modify the 'weight' variable
sscanf(line, "%lld %lld %lf", &from, &to, &weight);
addEdge(from, to, &weight);
last_vertex = from;
++outdegree;
for (int64_t i = 1; i < m_total_edge; ++i) {
line= getEdgeLine();
// Note: modify this if an edge weight is to be read
// modify the 'weight' variable
sscanf(line, "%lld %lld %lf", &from, &to, &weight);
if (last_vertex != from) {
addVertex(last_vertex, &value, outdegree);
last_vertex = from;
outdegree = 1;
}
else
{
++outdegree;
}
addEdge(from, to, &weight);
}
addVertex(last_vertex, &value, outdegree);
}
};
class VERTEX_CLASS_NAME(OutputFormatter): public OutputFormatter {
public:
void writeResult() {
int64_t vid;
double value;
char s[1024];
for (ResultIterator r_iter; ! r_iter.done(); r_iter.next() ) {
r_iter.getIdValue(vid, &value);
int n = sprintf(s, "%lld: %0.lf\n", (unsigned long long)vid, value);
writeNextResLine(s, n);
}
}
};
// An aggregator that records a double value tom compute sum
class VERTEX_CLASS_NAME(Aggregator): public Aggregator {
public:
void init() {
m_global = 0;
m_local = 0;
}
void* getGlobal() {
return &m_global;
}
void setGlobal(const void* p) {
m_global = * (double *)p;
}
void* getLocal() {
return &m_local;
}
void merge(const void* p) {
m_global += * (double *)p;
}
void accumulate(const void* p) {
m_local += * (double *)p;
}
};
class VERTEX_CLASS_NAME(): public Vertex {
public:
void compute(MessageIterator* pmsgs) {
if(getSuperstep() == 0)
{
//if is startVertex, send length to neighbours.
if(m_pme->m_v_id == startVertex)
{
Vertex::OutEdgeIterator it = getOutEdgeIterator();
for( ; !it.done(); it.next())
{
sendMessageTo(it.target(), getValue() + it.getValue());
}
}
//if not startVertex, set value max.
else
{
*mutableValue() = __DBL_MAX__;
sendMessageToAllNeighbors(__DBL_MAX__);
}
}
else
{
if(getSuperstep() >= 2)
{
//if all vertexs no change happened, return;
double global_val = * (double *)getAggrGlobal(0);
if (global_val == 0 ) {
voteToHalt(); return;
}
}
double val = getValue();
for( ; !pmsgs->done(); pmsgs->next())
{
double msgVal = pmsgs->getValue();
if (msgVal < getValue())
*mutableValue() = msgVal;
}
//if this vertex value changed, add 1 as mark. Don't care how change how much.
if(val != getValue())
{
double acc = 1;
accumulateAggr(0, &acc);
}
Vertex::OutEdgeIterator it = getOutEdgeIterator();
if(getValue() != __DBL_MAX__)
{
for( ;!it.done(); it.next())
{
sendMessageTo(it.target(), getValue() + it.getValue());
}
}
else
sendMessageToAllNeighbors(__DBL_MAX__);
}
}
};
class VERTEX_CLASS_NAME(Graph): public Graph {
public:
VERTEX_CLASS_NAME(Aggregator)* aggregator;
public:
// argv[0]: PageRankVertex.so
// argv[1]:
// argv[2]: 2.准备工作
阅读/hw2/part2里的readme.txt:
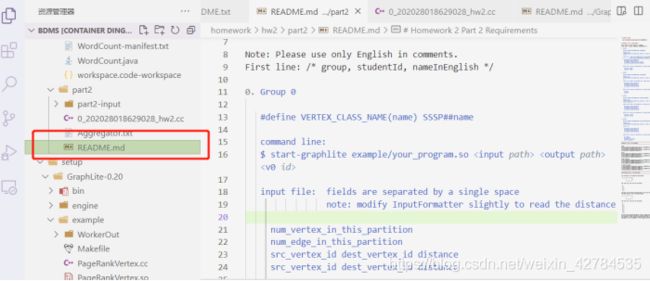
# GraphLite Usage
@see /home/bdms/setup/GraphLite-0.20/README.md
# Homework 2 Part 2 Requirements
Note: Please use only English in comments.
First line: /* group, studentId, nameInEnglish */
0. Group 0
#define VERTEX_CLASS_NAME(name) SSSP##name
command line:
$ start-graphlite example/your_program.so 这里需要使用GraphLite-0.20,但是docker里已经安装了,所以可以直接到对应文件夹去查看:
# GraphLite Usage
@see /home/bdms/setup/GraphLite-0.20/README.md

------------------------------------------------------------
Requirements
------------------------------------------------------------
1. JDK 1.7.x
2. Hadoop 2.6.x
3. protocol buffers
$ apt-get install protobuf-c-compiler libprotobuf-c0 libprotobuf-c0-dev
------------------------------------------------------------
Directory Structure
------------------------------------------------------------
bin/ scripts and graphlite executable
engine/ graphlite engine source code
example/ PageRank example
include/ header that represents programming API
Input/ a number of small example graphs
Output/ empty, will contain the output of a run
Makefile this can make both engine and example
LICENSE.txt Apache License, Version 2.0
README.txt this file
------------------------------------------------------------
Build graphlite
------------------------------------------------------------
1. source bin/setenv
(1) edit bin/setenv, set the following paths:
JAVA_HOME, HADOOP_HOME, GRAPHLITE_HOME
(2) $ . bin/setenv
2. build graphlite
$ cd engine
$ make
check if bin/graphlite is successfully generated.
------------------------------------------------------------
Compile and Run Vertex Program
------------------------------------------------------------
1. build example
$ cd example
$ make
check if example/PageRankVertex.so is successfully generated.
2. run example
$ start-graphlite example/PageRankVertex.so Input/facebookcombined_4w Output/out
PageRankVertex.cc declares 5 processes, including 1 master and 4 workers.
So the input graph file is prepared as four files: Input/facebookcombined_4w_[1-4]
The output of PageRank will be in: Output/out_[1-4]
Workers generate log files in WorkOut/worker*.out
------------------------------------------------------------
Write Vertex Program
------------------------------------------------------------
Please refer to PageRankVertex.cc
1. change VERTEX_CLASS_NAME(name) definition to use a different class name
2. VERTEX_CLASS_NAME(InputFormatter) can be kept as is
3. VERTEX_CLASS_NAME(OutputFormatter): this is where the output is generated
4. VERTEX_CLASS_NAME(Aggregator): you can implement other types of aggregation
5. VERTEX_CLASS_NAME(): the main vertex program with compute()
6. VERTEX_CLASS_NAME(Graph): set the running configuration here
7. Modify Makefile:
EXAMPLE_ALGOS=PageRankVertex
if your program is your_program.cc, then
EXAMPLE_ALGOS=your_program
make will produce your_program.so
------------------------------------------------------------
Use Hash Partitioner
------------------------------------------------------------
bin/hash-partitioner.pl can be used to divide a graph input
file into multiple partitions.
$ hash-partitioner.pl Input/facebookcombined 4
will generate: Input/facebookcombined_4w_[1-4]
根据上面的reedme.txt,我们先来学习一下graphlite的基本操作

由于docker内部已经部署过对应的环境了,所以我们直接使用

apt-get操作直接跳过,因为之前已经部署。下面这几个操作也可以直接跳过:
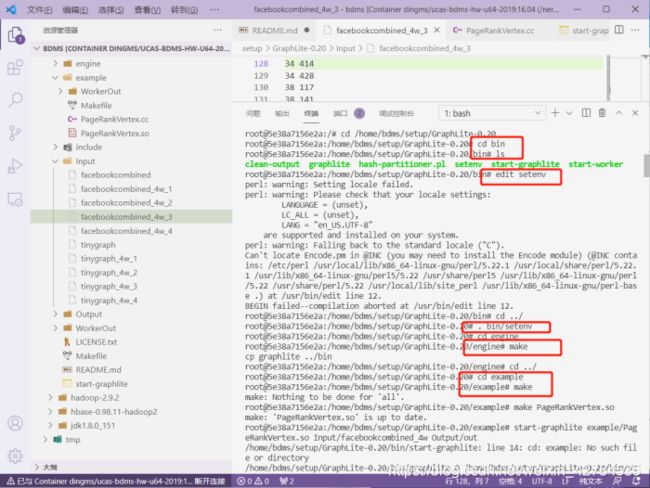
连接ssh,来开启grphlite
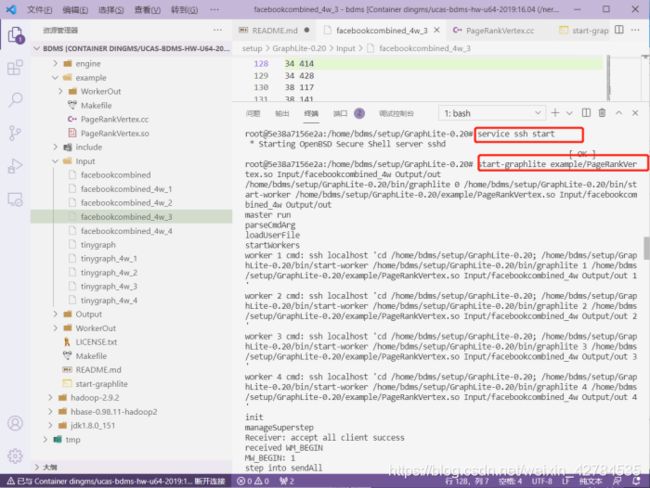


这里我们有更改相关的配置文件和程序,直接使用提供的。
之后运行hash操作,忽略warning:
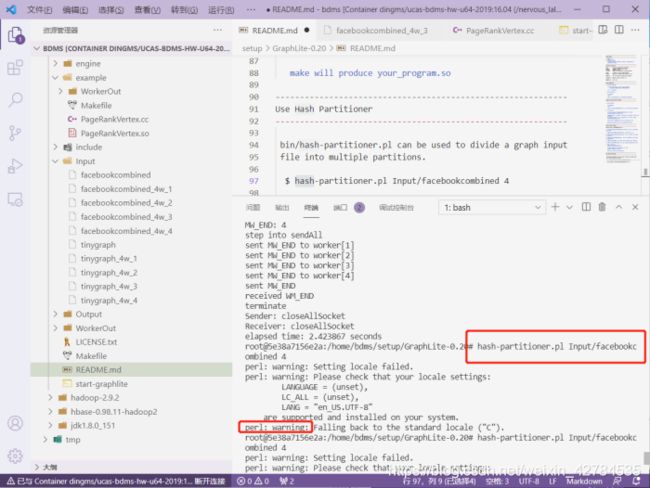
3.具体操作
根据之前的readme.txt,
我们再看看part2里的readme.txt:
# GraphLite Usage
@see /home/bdms/setup/GraphLite-0.20/README.md
# Homework 2 Part 2 Requirements
Note: Please use only English in comments.
First line: /* group, studentId, nameInEnglish */
0. Group 0
#define VERTEX_CLASS_NAME(name) SSSP##name
command line:
$ start-graphlite example/your_program.so 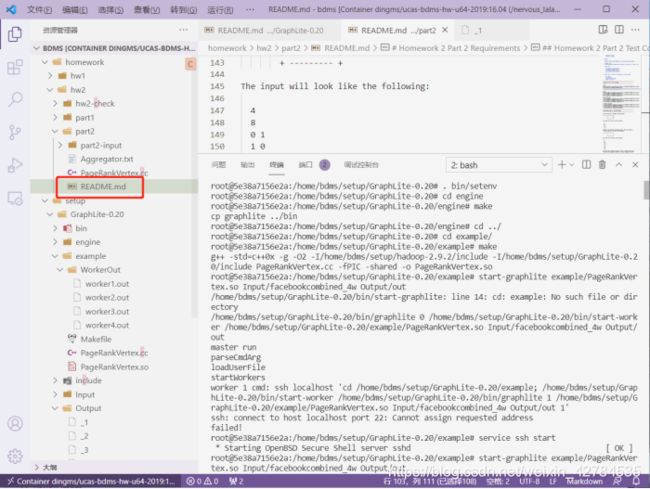


显然有两个地方需要注意,
在.cc文件里修改一个名字为SSSP,执行graplite的时候要注意一下。
我把/home/bdms/setup/GraphLite-0.20/example里的.cc文件换成我需要的文件了
把数据也复制到了/example文件夹下:
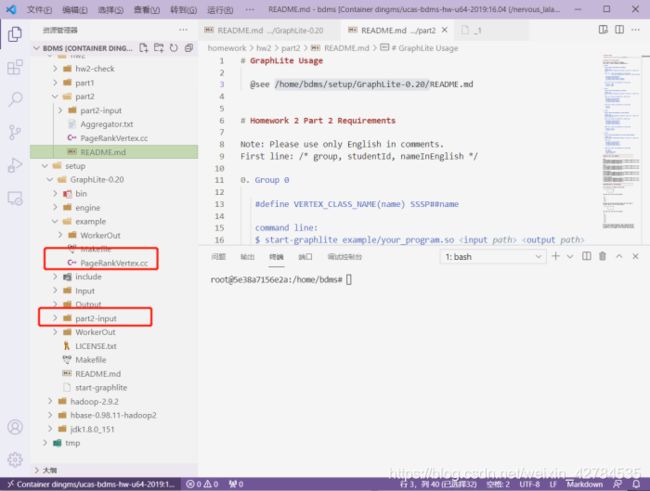
依次输入:



注意一个问题:运行一次graphlite,之后在运行要删除对应的进程
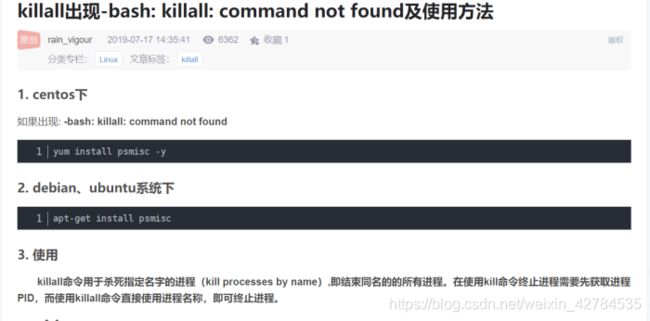
apt-get install psmisckillall graphlite
完成!
太舒服了,结束
码字不易,都看到这里了不如点个赞哦~
我是【豆干花生】,你的点赞+收藏+关注,就是我坚持下去的最大动力~

亲爱的朋友,这里是我新成立的公众号,欢迎关注!
公众号内容包括但不限于人工智能、图像处理、信号处理等等~之后还将推出更多优秀博文,敬请期待! 关注起来,让我们一起成长!
