Keras 实现 FCN 语义分割并训练自己的数据之 FCN-32s
Keras 实现 FCN 语义分割并训练自己的数据之 FCN-32s
-
- 一. Keras Sequential 模型定义全卷积神经网络模型(FCN)
- 二. 训练
- 三. 预测
- 四. 输出标记
- 五. 大图训练与预测
语义分割说起来高大上, 其实就是一个抠图大法, 要让电脑学会自动抠图, 那要先教其如何抠图
相信你已经把 FCN 的教程看得够多了, 现在需要的是手动实践一下, 但是又不知道从哪里下手, 那你看这篇文章就看对了
这里我以二分类为例, 多分类的以后再讲, 其实也没有多大区别, 万事先从简单的开始循序渐进才能降低学习难度, 下面要讲的网络结构也是从 FCN 最简单的形式开始
在 语义分割之 加载训练数据 中已经讲过了如何用 Generator 的方式加载数据, 现在就只差训练了
一. Keras Sequential 模型定义全卷积神经网络模型(FCN)
相对于 Sequential 模型, Functional API 可以实现更复杂的模型, 但是今天我们要从简单的入手, 所以先选择 Sequential 模型来实现. 整个过程我用的是 Jupyter Notebook 中完成的, 需要的库如下
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
import os
import os.path as osp
import cv2 as cv
from PIL import Image # 这里需要的库和加载数据的库是一样的
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
这里的模型旨在说明问题, 先不管性能和效果如何, 把网络搭建好并跑起来才是初学者应该关心的问题. 而不是一开始就要实现一个完美的网络模型, 所以不要想一下子就搞得非常好, 等把这个简单的跑起来之后, 再分析一下哪里不足改哪里. 这样改的时候才有了改的基础. 这才是动手能力强的人的逻辑. 不要坐在那里空想, 一定要动手敲代码
# 定义模型
project_name = "fcn_segment"
channels = 3
std_shape = (320, 320, channels) # 输入尺寸, std_shape[0]: img_rows, std_shape[1]: img_cols
# 这个尺寸按你的图像来, 如果你的图大小不一, 那 img_rows 和 image_cols
# 都要设置成 None, 如果你在用 Generator 加载数据时有扩展边缘, 那 std_shape
# 就是扩展后的尺寸
model = keras.Sequential(name = project_name)
model.add(keras.layers.Conv2D(32, kernel_size = (3, 3), activation = "relu",
padding = "same", input_shape = std_shape,
name = "conv_1"))
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_1"))
model.add(keras.layers.Conv2D(64, kernel_size = (3, 3), activation = "relu",
padding = "same", name = "conv_2"))
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_2"))
model.add(keras.layers.Conv2D(128, kernel_size = (3, 3), activation = "relu",
padding = "same", name = "conv_3"))
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_3"))
model.add(keras.layers.Conv2D(256, kernel_size = (3, 3), activation = "relu",
padding = "same", name = "conv_4"))
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_4"))
model.add(keras.layers.Conv2D(512, kernel_size = (3, 3), activation = "relu",
padding = "same", name = "conv_5"))
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_5"))
注意上面对 std_shape 的注释, 如果你图像尺寸大小相同, 那加载数据时 batch_size 可以大于 1, 如果不相同, 那 batch_size 只能是 1 了
相信你已经看出来了, 上面的模型并没有全部完成, 只表示了卷积和池化的部分, 一共有 5 组 10 层, 每组包括一个 Conv2D 和一个 MaxPool2D. 最后的输出是 10 * 10 * 512, 表示 大小为 10 * 10, 通道数为 512. 这就是和传统的 CNN 网络相同的部分. 这部分用来检测图像中是否有目标存在, 并且在哪里, 也就是 Feature map. 在结构上和 VGG 之类的并不相同, 因为为了说明问题, 先把所有的问题都简化. 图像经过上面的 5 组操作之后, 尺寸缩小到原来的 1 / 32
接下来的网络就是要把上面的输出还原到与输入相同的尺寸. 直接来一个简单粗暴的 32 倍上采样还原到原来的输入尺寸, 这里使用不需要训练的 UpSampling2D 来进行, 默认使用 nearest 插值方式, 换成 bilinear 有惊喜
model.add(keras.layers.UpSampling2D(size = (32, 32), interpolation = "nearest", name = "upsamping_6"))
好了, 网络已经 差不多 定义完成, 是不是比你想象的更简单. 当然这样的网络性能可能好不到哪里去, 至少我们按 FCN 的原理迈出了一大步

到这里应该有同学提问才对, 输出是有输出了, 是不是差了点什么东西?, 但是又说不上来. Yes, 缺少了评价输出结果的损失函数
想一下之前学过的全连接神经网络, 在二分类问题上, 输出层只有一个神经元, 使用 Sigmoid 激活函数, 损失函数为 binary_crossentropy. 那问题来了, 现在的输出可不只一个神经元, 而是和输入相同尺寸的且有 512 个通道的图像, 乖乖不得了了, 怎么弄?
回忆一下, FCN 语义分割最后是对像素进行分类, 有多少类最后的输出图像就有多少个通道, 每个通道的像素值代表了这个通道的像素应划分到哪一个类别的概率, 如果某一个像素位置在第 3 通道的值最大, 那这个位置的像素就属性第 3 个分类
好了, 是不是有一点眉目了, 二分类也是分类的一种吧, 所以我们需要把上面输出的 512 个通道变成两个通道. 这里我们再简化一下, 二分类只需要一个通道, 值小于 0.5 就是背景, 大于 0.5 就是目标. 这样是不是就可以用 Sigmoid 激活了呢, 通道数是定下来了, 但是要怎么变成 1 个通道呢?
你再看一下上面的卷积层, 是不是通道数在增加, 通道数目取决于卷积核的数目, 所以我们只需要用 1 个 512 通道的卷积核再卷积一下就可以了. 是不是很神奇?
# 第 5 组 MaxPool2D
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_5"))
model.add(keras.layers.UpSampling2D(size = (32, 32), interpolation = "nearest", name = "upsamping_6"))
# 这里只有一个卷积核, 可以把 kernel_size 改成 1 * 1, 也可以是其他的, 只是要注意 padding 的尺寸
# 也可以放到 upsamping_6 的前面, 试着改一下尺寸和顺序看一下效果
# 这里只是说明问题, 尺寸和顺序不一定是最好的
model.add(keras.layers.Conv2D(1, kernel_size = (3, 3), activation = "sigmoid",
padding = "same", name = "conv_7"))
到了这里, 输出的通道数是 1 了, Sigmoid 激活函数也出现了, 最后 compile
model.compile(optimizer = "adam",
loss = "binary_crossentropy",
metrics = ["accuracy"])
model.summary()
Model: "fcn_segment"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_1 (Conv2D) (None, 320, 320, 32) 896
_________________________________________________________________
max_pool_1 (MaxPooling2D) (None, 160, 160, 32) 0
_________________________________________________________________
conv_2 (Conv2D) (None, 160, 160, 64) 18496
_________________________________________________________________
max_pool_2 (MaxPooling2D) (None, 80, 80, 64) 0
_________________________________________________________________
conv_3 (Conv2D) (None, 80, 80, 128) 73856
_________________________________________________________________
max_pool_3 (MaxPooling2D) (None, 40, 40, 128) 0
_________________________________________________________________
conv_4 (Conv2D) (None, 40, 40, 256) 295168
_________________________________________________________________
max_pool_4 (MaxPooling2D) (None, 20, 20, 256) 0
_________________________________________________________________
conv_5 (Conv2D) (None, 20, 20, 512) 1180160
_________________________________________________________________
max_pool_5 (MaxPooling2D) (None, 10, 10, 512) 0
_________________________________________________________________
upsamping_6 (UpSampling2D) (None, 320, 320, 512) 0
_________________________________________________________________
conv_7 (Conv2D) (None, 320, 320, 1) 4609
=================================================================
Total params: 1,573,185
Trainable params: 1,573,185
Non-trainable params: 0
_________________________________________________________________
二. 训练
语义分割之 加载训练数据 中已经讲过训练的套路了. 这里就按套路来, 接代码如下
# 训练模型
epochs = 16
batch_size = 1 # 当训练图像的尺寸不一样时, 就只能是 1, 不然会把输入数据 shape 不对
# train_path 和 valid_path 由前面的 get_data_path 得到
# 这两个 reader 源源不断地提供训练所需要的数据, 这就是 yield 神奇的地方
train_reader = segment_reader(train_path, batch_size, shuffle_enable = True)
valid_reader = segment_reader(valid_path, batch_size, shuffle_enable = True)
history = model.fit(x = train_reader, # 训练数据
steps_per_epoch = len(train_path) // batch_size,
epochs = epochs,
verbose = 1,
validation_data = valid_reader, # 验证数据
validation_steps = max(1, len(valid_path) // batch_size),
max_queue_size = 8,
workers = 1)
随便训练一下就有很高的正确率, 不过不能说明什么, 因为背景的像素点比目标的像素点多得多

三. 预测
预测很简单, 直接喂数据就可以了, 也可以用 Generator 的方式进行
# test_path 可以是 get_data_path 返回的 test 目录, 要分割成三部分, 可以像下面这样
# train_path, valid_path, test_path = get_data_path(data_path, (0.7, 0.2, 0.1))
# test_path 也可以是你手动列出来的目录
#
# train_mode = False 可以返回 roi, 运行一次可以预测一个 batch_size
test_reader = segment_reader(test_path, batch_size = 1, train_mode = False)
有了上面的 test_reader 就可以预测了
# 运行一次测试一个 batch_size
batch_x, batch_roi = next(test_reader)
batch_y = model.predict(batch_x)
那怎么显示预测结果呢
# 显示预测结果
show_index = 0 # 显示 batch_size 中的序号, 这里显示第 0 个
roi = batch_roi[show_index]
x = batch_x[show_index][roi[1]: roi[1] + roi[3], roi[0]: roi[0] + roi[2]]
y = batch_y[show_index][roi[1]: roi[1] + roi[3], roi[0]: roi[0] + roi[2]]
plt.figure("segment", figsize = (6, 4))
plt.subplot(1, 2, 1)
plt.axis("on")
plt.title("test", color = "orange")
plt.imshow(x[..., : : -1])
plt.subplot(1, 2, 2)
plt.axis("on")
plt.title("predict", color = "orange")
plt.imshow(np.squeeze(y), cmap = "gray")
plt.show()
直接 32 倍上采样出来的结果很粗糙, 贴一个我用 nearest 插值和 groudn_truth 比较的图
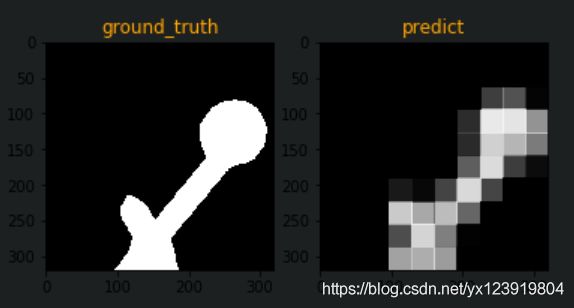
此时 predict 图像并不是二值化的结果, 因为没有做二值化的操作, 此时的各像素的预测值是 y 的输出值. 要二值化的话, 自己选择一个合适的阈值, 不一定是 0.5
四. 输出标记
预测结果是有了, 如何标记到原始图像上? 选择一个合适的阈值, 预测值超过阈值就在原图上增加一个颜色值就可以了, 看起来标记也是透明的, 还可以单独标记一个 Mask 以作他用
# 标记预测结果
img_marked = x.copy(); # 标记后的图像
# 单独使用的 Mask
img_mask = np.zeros((img_marked.shape[0], img_marked.shape[1], 1), dtype = np.uint8)
for r in range(img_marked.shape[0]):
for c in range(img_marked.shape[1]):
if y[r][c] >= 0.5: # 阈值
img_marked[r][c] += [0, 0, 0.3] # 在 img_marked 上标记为红色
# 三个值分别是 BGR 颜色, 值越小越透明
img_mask[r][c] = 255
plt.figure("mark_image", figsize = (6, 3))
plt.subplot(1, 1, 1)
plt.axis("on")
plt.title("img_marked", color = "orange")
plt.imshow(img_marked[..., : : -1])
五. 大图训练与预测
当输入尺寸一般大, 硬件能支撑的话, 可以直接进行训练, 但是像 2596 * 1944 这样的大图的话, 一般硬件是吃不消的, 肿么办? 不要慌, 我们不是还有 Generator 吗, 我可以在其中将大图裁切成能训练的小图, 在 Generator 中增加如下代码, 增加的位置你自己想一下吧
# 按 std_shape 裁切
for r in range(max_rows // std_shape[0]):
for c in range(max_cols // std_shape[1]):
top = r * std_shape[0]
left = c * std_shape[1]
img_sub = big_x[top: top + std_shape[0], left: left + std_shape[1]]
train.append(img_sub)
img_sub = big_y[top: top + std_shape[0], left: left + std_shape[1]]
label.append(img_sub)
if len(train) == batch_size:
yield (np.array(train), np.array(label))
train = []
label = []
训练的时候用小图, 但是预测的时候不需要那么好的配置了, 可以直接用大图预测
上一篇: 语义分割之 加载训练数据
下一篇: Keras 实现 FCN 语义分割并训练自己的数据之 FCN-16s、FCN-8s