电商日志分析大数据实训项目
电商日志分析大数据实训项目
-
- 项目介绍
-
- 1. 项目介绍
- 2. 项目数据流程
- 准备工作:
-
- 1. 虚拟机的安装
- 2. 虚拟机的创建及CentOS7安装
- 组件搭建
-
- 一、CentOS7下MySQL-5.7使用yum方式安装:
- 二、CentOS7下Nginx的安装:
- 三、部署前端网站到nginx下
- 四、Tomcat的安装
- 五、电商后台系统部署到Linux服务器上
- 六、AB压测(httpd)安装
- 七、Hadoop安装与配置
- 八、Flume的安装与配置
- 九、MapReduce工程代码
- 十、SQOOP安装配置
- 十一、集成调试
- 十二、源码
项目介绍
1. 项目介绍
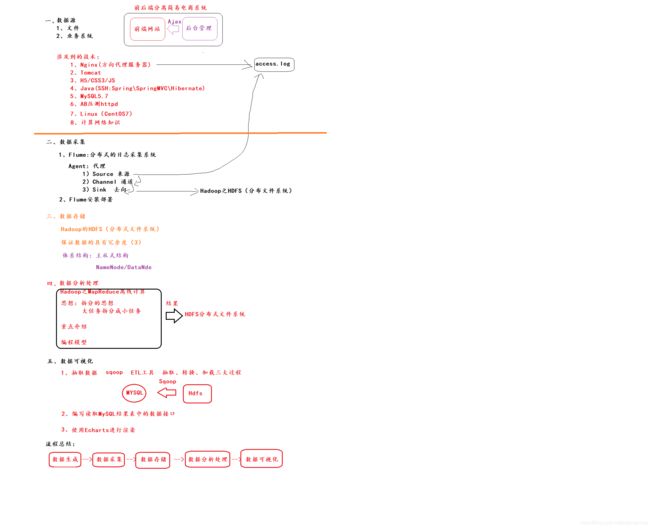
本次实训,要求使用Hadoop及其生态圈相关的组件来实现企业级大数据开发的整套流程,即数据的采集、数据的存储、数据的分析处理及数据的可视化。其中数据的采集部分会介绍两种方式,一种介绍网络爬虫及其Java代码实现步骤,另外一种是利用学生所掌握的spring mvc技术来构建一个简易的电商平台,采取压测的方式模拟海量日志的产生,通过使用Nginx和tomcat实现动静资源分开部署的方式,采取flume日志采集组件来实现日志的采集,相比网络爬虫,这部分是实训所推荐的一种数据采集的方式;数据的存储部分,将采用MySQL和HDFS来分别存储关系型数据和非关系型数据,其中将会使用到sqoop组件作为MySQL和HDFS之间数据的转换桥梁和通道;数据分析处理部分,采用MapReduce程序实现数据的清洗和分析;数据可视化部分,采用echarts图表来展现。最终的效果是通过压测产生电商系统日志、flume采集日志、MapReduce分析处理日志、sqoop将分析后的结果导入到MySQL中、spring mvc项目前端对分析结果进行可视化,即展现商品的topN信息。
2. 项目数据流程
准备工作:
1. 虚拟机的安装
虚拟机版本:
VMware-workstation-full-15.5.1-15018445.exe网上自行找资源下载
安装步骤,请参考:
https://blog.csdn.net/sujiangming/article/details/87991536
2. 虚拟机的创建及CentOS7安装
操作系统及版本:CentOS-7-x86_64-DVD-1511.iso
安装步骤,请参考我另外一篇博文:
https://blog.csdn.net/sujiangming/article/details/87992373
组件搭建
一、CentOS7下MySQL-5.7使用yum方式安装:
1、安装MySQL YUM源到本地
yum localinstall https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
2、检查 mysql 源是否安装成功
yum repolist enabled | grep "mysql.*-community.*"
安装成功后会看到如下:
!mysql-connectors-community/x86_64 MySQL Connectors Community 153
!mysql-tools-community/x86_64 MySQL Tools Community 110
!mysql57-community/x86_64 MySQL 5.7 Community Server 424
3、使用 yum install 命令安装
yum -y install mysql-community-server
4、安装完毕后,启动MySQL数据库
systemctl start mysqld
5、查看MySQL的启动状态
systemctl status mysqld
6、设置开机自启动
systemctl enable mysqld
7、重载所有修改过的配置文件
systemctl daemon-reload
8、修改root账户默认密码
mysql 安装完成之后,生成的默认密码在 /var/log/mysqld.log 文件中。使用 grep 命令找到日志中的密码。
执行:
grep 'temporary password' /var/log/mysqld.log
比如:
A temporary password is generated for root@localhost: WMYu.#o8o#30
9、修改密码
使用mysql -uroot -p 回车, 注意密码改为:Sjm@!_123456 输入:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Sjm@!_123456';
10、配置root用户远程登录及添加远程登录用户
默认只允许root帐户在本地登录,如果要在其它机器上连接mysql,两种方式:
1)设置root用户允许远程登录:
执行:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'Sjm@!_123456' WITH GRANT OPTION;
flush privileges;
2)可以添加一个允许远程连接的普通帐户
执行:
GRANT ALL PRIVILEGES ON *.* TO 'suben'@'%' IDENTIFIED BY 'Sjm@!_123456' WITH GRANT OPTION;
flush privileges;
12、设置默认编码为 utf8
mysql 安装后默认不支持中文,需要修改编码。
修改 /etc/my.cnf 配置文件,在相关节点(没有则自行添加)下添加编码配置,如下:
执行:vi /etc/my.cnf
在文件的末尾添加如下信息:
[mysqld]
character-set-server=utf8
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
CentOS7下MySQL-5.7使用yum方式卸载:
1、停止MySQL
命令:systemctl stop mysqld
2、查看已安装的mysql
命令:rpm -qa | grep -i mysql
3、卸载mysql,依次卸载第2步骤所列出的有关MySQL的安装包,如
命令:yum remove -y mysql-community-server-5.6.36-2.el7.x86_64
4、删除mysql相关目录
1)使用命令查看mysql相关的文件目录:find / -name mysql
2)依次删除所查到的目录,命令:rm -rf /xxx/xxx/mysql
二、CentOS7下Nginx的安装:
1、编写安装脚本:nginx_install.sh,添加如下内容:
#!/bin/bash
yum install -y gcc
#install pcre
yum install -y pcre-static.x86_64
#install nginx
tar -zvxf /tools/nginx-1.15.12.tar.gz -C /training/
cd /training/nginx-1.15.12
./configure --prefix=/training/nginx --without-http_gzip_module
make && make install
#set .bash_profile
echo '#nginx' >> ~/.bash_profile
echo 'export PATH=$PATH:/training/nginx/sbin' >> ~/.bash_profile
# source .bash_profile
source ~/.bash_profile
2、赋予nginx_intall.sh执行权限:
chmod +x nginx_install.sh
3、安装nginx,进入到nginx_intall.sh脚本所在目录,执行:
./nginx_intall.sh
4、编写启动nginx的脚本nginx_start.sh,执行 vi nginx_start.sh添加如下内容:
#!/bin/bash
cd /training/nginx/sbin
./nginx
5、启动nginx,执行
./nginx_start.sh
6、验证nginx是否启动成功:
netstat -anop|grep nginx 或者 netstat -anop|grep 80
成功信息:
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 59717/nginx: master off (0.00/0/0)
7、编写停止nginx脚本,执行vi nginx_stop.sh ,添加如下内容:
#!/bin/bash
cd /training/nginx/sbin
./nginx -s stop
8、停止nginx,执行
./nginx_stop.sh
9、编写热加载nginx脚本,执行vi nginx_reload.sh ,添加如下内容:
#!/bin/bash
cd /training/nginx/sbin
./nginx -s reload
10、重新加载nginx,执行:
./nginx_reload.sh
三、部署前端网站到nginx下
1、上传电商网站OnlineShop文件夹到/training/nginx/html/目录下,
将OnlineShop文件夹重命名为shop
mv OnlineShop shop
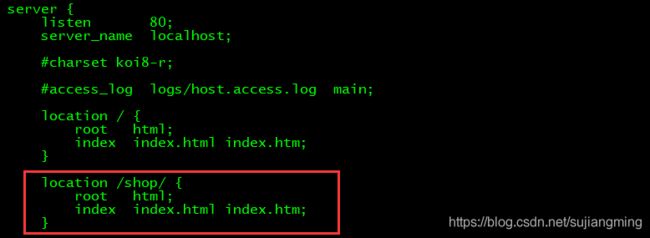
2、修改nginx配置文件nginx.conf,执行:
vi /training/nginx/conf/nginx.conf
添加如下内容:
# add shop
location /shop/ {
root html;
index index.html index.htm;
}
3、重新记载nginx,执行:
./nginx_reload.sh
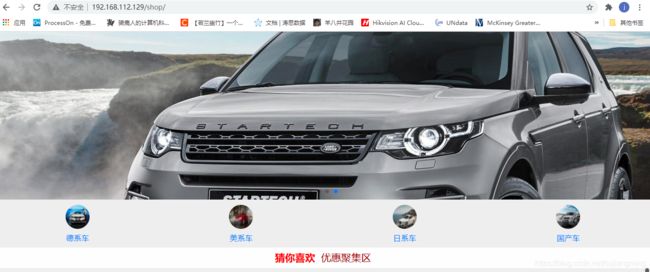
4、验证:在浏览器中验证下是否可以访问到网站,输入:
http://虚拟机ip地址/shop/
5、效果如下:
四、Tomcat的安装
0、前提条件:JDK1.8的安装
- 上传jdk-8u171-linux-x64.tar.gz到tools目录下,然后执行下面的命令进行解压安装
tar -zvxf jdk-8u171-linux-x64.tar.gz -C /training/ - 配置环境变量:
在.bash_profile文件中添加如下信息:vi ~/.bash_profileexport JAVA_HOME=/training/jdk1.8.0_171 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin; - 让环境变量生效
source ~/.bash_profile - 验证jdk是否安装成功
java -version
1、下载tomcat-8.5.40,到官网上下
2、安装tomcat
-
上传tomcat到/tools目录下
-
解压安装:
tar -zvxf apache-tomcat-8.5.61.tar.gz -C /training/ -
配置环境变量 vi ~/.bash_profile
#tomcat export PATH=$PATH:/training/apache-tomcat-8.5.61/bin -
生效:
source ~/.bash_profile -
启动
startup.sh -
验证,在浏览器输入: http://192.168.215.131:8080/或者在命令行里面输入:netstat -anop|grep 8080

五、电商后台系统部署到Linux服务器上
-
将代码导入到eclipse或者idea中
-
将代码中的接口地址、数据库链接地址等修改成服务器地址,具体需要修改的代码如下:
GoodsController.java:- 修改上传图片地址为服务器地址 - 将代码中的localhost或者IP地址改成服务器IP地址RemoteExecuteCommand.java,将如下改成你自己虚拟机的相关信息
private RemoteExecuteCommand() { this.ip = "192.168.112.128"; // 需要修改 this.userName = "root"; // 如不是这个用户名,则需要修改 this.userPwd = "123456"; // 需要修改 }UploadUtils.java:
- 将代码中的localhost或者IP地址改成服务器IP地址hibernate.properties:
- 修改数据库名及地址为服务器的数据库名及地址 - 修改数据库用户明、密码为服务器的用户密码修改webapp目录下的所有html及jsp页面
- 将代码中的localhost或者IP地址改成服务器IP地址 -
选择export->war
-
上传war至Linux服务器的Tomcat安装目录下
-
启动或重启Tomcat
-
配置Tomcat支持UTF-8字符集
由于后台项目页面部分采用了html和jsp结合嵌套的方式,即在jsp中嵌套了html代码段,会存在html代码段显示中文乱码的问题,故需要做配置
1)修改tomcat/conf目录下的server.xml,添加URIEncoding=“UTF-8”配置项,配置位置如下:<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8" /> <Connector protocol="AJP/1.3" address="::1" port="8009" redirectPort="8443" URIEncoding="UTF-8" />2)修改tomcat/conf/web.xml,在 节点中添加如下内容:
<init-param> <param-name>fileEncodingparam-name> <param-value>UTF-8param-value> init-param>3)先删除tomcat下的webapp/项目/所有html页面,再重新新建并添加对应的内容
4)启动Tomcat
6、打开浏览器进行验证:

六、AB压测(httpd)安装
- 安装httpd
yum install -y httpd - 配置httpd,修改端口号为81,配置如下:
修改内容如下:vi /etc/httpd/conf/httpd.conf#Listen 80 Listen 81 - 启动服务
systemctl enable httpd # 开机自启动 systemctl start httpd # 启动httpd - 查看启动状态
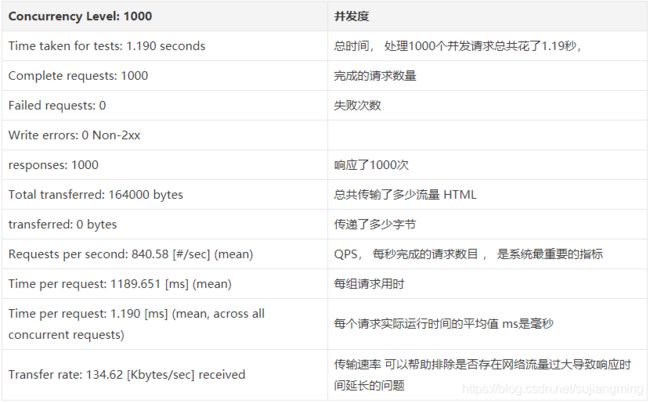
systemctl status httpd - 编写压测脚本ab_test.sh,内容可自行修改,如下:
#!/bin/bash n=`cat url.txt | wc -l` for ((i=1;i<=$n;i++)) do echo $i url=`shuf -n1 url.txt` r=`shuf -i 6-100 -n 1` c=`shuf -i 1-5 -n 1` echo $url echo $r echo $c ##将测试的结果写入到test_ab.log >> results.log & ab -n $r -c $c $url >> results.log & done - 测试结果说明
七、Hadoop安装与配置
-
上传hadoop-2.7.3.tar.gz到tools目录下,然后执行下面的命令进行解压安装
tar -zvxf hadoop-2.7.3.tar.gz -C /training/ -
配置环境变量:
vi ~/.bash_profile添加如下信息:
export HADOOP_HOME=/training/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
让环境变量生效:
source ~/.bash_profile -
验证是否生效:
执行:hdfs 或者hadopo 有相关信息出现即可 -
配置伪分布式环境:
- 配置免密登录
ssh-keygen -t rsa (直接回车3次) cd ~/.ssh/ ssh-copy-id -i id_rsa.pub root@bigdata (主机名可以自行修改成你自己的主机名) - 创建用于存储hadoop格式化后数据的目录
mkdir /training/hadoop-2.7.3/tmp - 修改hadoop-env.sh文件,配置jdk路径
执行如下命令打开文件进行编辑:
在打开的文件中,修改jdk路径为虚拟机安装的路径vi hadoop-env.shexport JAVA_HOME=/training/jdk1.8.0_171 - 修改hdfs-site.xml,配置如下:
注意:下面的配置信息需要在configuration节点中间添加哈<property> <name>dfs.replicationname> <value>1value> property> <property> <name>dfs.permissionsname> <value>falsevalue> property> - 修改core-site.xml,配置如下:
注意:下面的配置信息需要在configuration节点中间添加哈<property> <name>fs.defaultFSname> <value>hdfs://bigdata:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/training/hadoop-2.7.3/tmpvalue> property> - 创建并修改mapred-site.xml,如下:
创建mapred-site.xml,执行如下命令:
配置mapred-site.xml,配置如下:cp /training/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template /training/hadoop-2.7.3/etc/hadoop/mapred-site.xml
注意:下面的配置信息需要在configuration节点中间添加哈<property> <name>mapreduce.framework.namename> <value>yarnvalue> property> - 配置yarn-site.xml文件,配置如下:
注意:下面的配置信息需要在configuration节点中间添加哈<property> <name>yarn.resourcemanager.hostnamename> <value>niit04value> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> - 格式化:HDFS(NameNode)
查看是否格式化成功,成功的信息提示如下:hdfs namenode -formatcommon.Storage: Storage directory /training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted. - 启动Hadoop(完全启动)
命令行验证,执行:jps 命令start-all.sh
看看有没有如下五个进程:
web界面进行验证:NameNode DataNode ReourceManager NodeManager SecondaryNameNode
HDFS分布式文件系统界面:
Yarn容器运行界面:http://bigdata:50070 #bigdata指虚拟机名称http://bigdata:8088 #bigdata指虚拟机名称 - 停止Hadoop,可以执行如下命令:
stop-all.sh - 注意事项
1)若想在windows浏览器中通过输入主机名称+端口号的形式访问界面,则需要设置主机名与ip地址的映射关系(针对虚拟机而言)
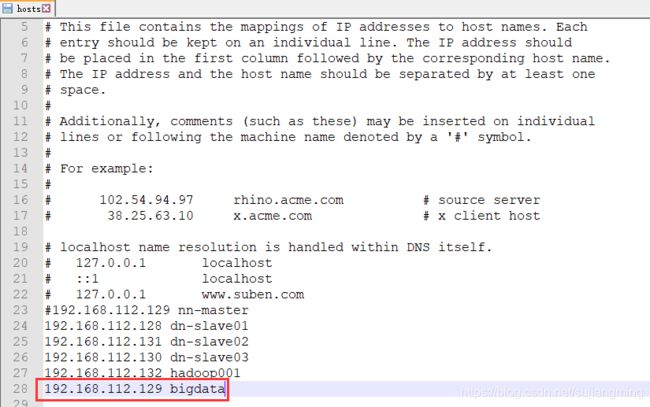
2)如何在windows上设置虚拟机主机名称与IP地址映射关系,如下所示:进入到C:\Windows\System32\drivers\etc 文件夹,找到hosts文件,对它进行编辑:
配置成如下图所示:
- 配置免密登录
八、Flume的安装与配置
-
上传flume到/tools目录下
-
解压安装
tar -zvxf apache-flume-1.9.0-bin.tar.gz -C /training/ -
配置环境变量,并让环境变量生效
export FLUME_HOME=/training/apache-flume-1.9.0-bin export PATH=$PATH:$FLUME_HOME/bin -
将hadoop-2.7.3安装路径下的依赖的jar导入到/apache-flume-1.9.0-bin/lib下:
share/hadoop/common/hadoop-common-2.7.3.jar share/hadoop/common/lib/commons-configuration-1.6.jar share/hadoop/common/lib/hadoop-auth-2.7.3.jar share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar share/hadoop/common/lib/commons-io-2.4.jar可以执行如下命令:
cp /training/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar /training/apache-flume-1.9.0-bin/lib/ cp /training/hadoop-2.7.3/share/hadoop/common/lib/commons-configuration-1.6.jar /training/apache-flume-1.9.0-bin/lib/ cp /training/hadoop-2.7.3/share/hadoop/common/lib/hadoop-auth-2.7.3.jar /training/apache-flume-1.9.0-bin/lib/ cp /training/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar /training/apache-flume-1.9.0-bin/lib/ cp /training/hadoop-2.7.3/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar /training/apache-flume-1.9.0-bin/lib/ cp /training/hadoop-2.7.3/share/hadoop/common/lib/commons-io-2.4.jar /training/apache-flume-1.9.0-bin/lib/ -
验证
bin/flume-ng version -
配置Flume HDFS Sink:
在/training/apache-flume-1.9.0-bin/conf/新建一个flume-hdfs.conf
添加如下内容:# define the agent a1.sources=r1 a1.channels=c1 a1.sinks=k1 # define the source #上传目录类型 a1.sources.r1.type=spooldir a1.sources.r1.spoolDir=/training/nginx/logs/flumeLogs #定义自滚动日志完成后的后缀名 a1.sources.r1.fileSuffix=.FINISHED #根据每行文本内容的大小自定义最大长度4096=4k a1.sources.r1.deserializer.maxLineLength=4096 # define the sink a1.sinks.k1.type = hdfs #上传的文件保存在hdfs的/flumeLogs目录下 a1.sinks.k1.hdfs.path = hdfs://bigdata:9000/flumeLogs/%y-%m-%d/%H/%M/%S a1.sinks.k1.hdfs.filePrefix=access_log a1.sinks.k1.hdfs.fileSufix=.log a1.sinks.k1.hdfs.batchSize=1000 a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.writeFormat= Text # roll 滚动规则:按照数据块128M大小来控制文件的写入,与滚动相关其他的都设置成0 #为了演示,这里设置成500k写入一次 a1.sinks.k1.hdfs.rollSize= 512000 a1.sinks.k1.hdfs.rollCount=0 a1.sinks.k1.hdfs.rollInteval=0 #控制生成目录的规则:一般是一天或者一周或者一个月一次,这里为了演示设置10秒 a1.sinks.k1.hdfs.round=true a1.sinks.k1.hdfs.roundValue=10 a1.sinks.k1.hdfs.roundUnit= second #是否使用本地时间 a1.sinks.k1.hdfs.useLocalTimeStamp=true #define the channel a1.channels.c1.type = memory #自定义event的条数 a1.channels.c1.capacity = 500000 #flume事务控制所需要的缓存容量1000条event a1.channels.c1.transactionCapacity = 1000 #source channel sink cooperation a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1注意:- 需要先在/training/nginx/logs/创建flumeLogs
- 需要在hdfs的根目录/下创建flumeLogs -
修改conf/flume-env.sh(该文件事先是不存在的,需要复制一份)
复制:cp flume-env.template.sh flume-env.sh编辑文件,并设置如下内容:
#设置JAVA_HOME: export JAVA_HOME = /training/jdk1.8.0_171 #修改默认的内存: export JAVA_OPTS="-Xms1024m -Xmx1024m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit" -
启动flume
- 测试数据:把 /training/nginx/logs/access.log 复制到
/training/nginx/logs/flumeLogs/access_201904251200.log - 启动
在/training/apache-flume-1.9.0-bin目录下,执行如下命令进行启动:bin/flume-ng agent --conf ./conf/ -f ./conf/flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console - 到Hadoop的控制台http://bigdata:50070/flumeLogs 查看有没有数据
- 测试数据:把 /training/nginx/logs/access.log 复制到
-
编写Linux脚本rollingLog.sh,实现/training/nginx/logs/access.log日志的自动滚动到flumeLogs目录下
- 在~目录下新建rollingLog.sh,并添加如下内容:
#!/bin/bash #定义日期格式 dataformat=`date +%Y-%m-%d-%H-%M-%S` #复制access.log并重命名 cp /training/nginx/logs/access.log /training/nginx/logs/access_$dataformat.log host=`hostname` sed -i 's/^/'${host}',&/g' /training/nginx/logs/access_$dataformat.log #统计日志文件行数 lines=`wc -l < /training/nginx/logs/access_$dataformat.log` #将格式化的日志移动到flumeLogs目录下 mv /training/nginx/logs/access_$dataformat.log /training/nginx/logs/flumeLogs #清空access.log的内容 sed -i '1,'${lines}'d' /training/nginx/logs/access.log #重启nginx , 否则 log can not roll. kill -USR1 `cat /training/nginx/logs/nginx.pid` ##返回给服务器信息 ls -al /training/nginx/logs/flumeLogs/
- 在~目录下新建rollingLog.sh,并添加如下内容:
-
编写启动Flume脚本 flume_start.sh,启动Flume
#!/bin/bash /training/apache-flume-1.9.0-bin/bin/flume-ng agent -c /training/apache-flume-1.9.0-bin/conf/ -f /training/apache-flume-1.9.0-bin/conf/flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console & -
编写停止Flume脚本 flume_stop.sh,停止Flume
#!/bin/bash JAR="flume" #停止flume函数 echo "begin stop flume process.." num=`ps -ef|grep java|grep $JAR|wc -l` echo "当前已经启动的flume进程数:$num" if [ "$num" != "0" ];then #正常停止flume ps -ef|grep java|grep $JAR|awk '{print $2;}'|xargs kill echo "进程已经关闭..." else echo "服务未启动,无须停止..." fi -
编写重启Flume脚本 flume_to_hdfs.sh,综合了前两个脚本
#!/bin/bash #先停止正在启动的flume ./flume_stop.sh #用法:nohup ./start-dishi.sh >output 2>&1 & nohup ./flume_start.sh > nohup_output.log 2>&1 & echo "启动flume成功……"
九、MapReduce工程代码
- 创建maven工程
- 引入maven依赖
<dependencies> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-commonartifactId> <version>2.7.3version> <scope>providedscope> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-hdfsartifactId> <version>2.7.3version> <scope>providedscope> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-mapreduce-client-commonartifactId> <version>2.7.3version> <scope>providedscope> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-mapreduce-client-coreartifactId> <version>2.7.3version> <scope>providedscope> dependency> dependencies> - 添加log4j.properties文件在资源目录下即resources,文件内容如下
### 配置根 ### log4j.rootLogger = debug,console,fileAppender ## 配置输出到控制台 ### log4j.appender.console = org.apache.log4j.ConsoleAppender log4j.appender.console.Target = System.out log4j.appender.console.layout = org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern = %d{ ABSOLUTE} %5p %c:%L - %m%n ### 配置输出到文件 ### log4j.appender.fileAppender = org.apache.log4j.FileAppender log4j.appender.fileAppender.File = logs/logs.log log4j.appender.fileAppender.Append = false log4j.appender.fileAppender.Threshold = DEBUG,INFO,WARN,ERROR log4j.appender.fileAppender.layout = org.apache.log4j.PatternLayout log4j.appender.fileAppender.layout.ConversionPattern = %-d{ yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n - 编写MR程序之Mapper:LogMapper.java
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; public class LogMapper extends Mapper<LongWritable, Text,Text, IntWritable> { // 按指定模式在字符串查找 String pattern = "\\=[0-9a-z]*"; // 创建 Pattern 对象 Pattern r = Pattern.compile(pattern); protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String data = value.toString(); // 现在创建 matcher 对象 Matcher m = r.matcher(data); if (m.find()) { String idStr = m.group(0); String id = idStr.substring(1); context.write(new Text(id),new IntWritable(1)); } } } - 编写MR程序之Mapper:LogReducer.java
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class LogReducer extends Reducer<Text, IntWritable,Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable v: values) { sum += v.get(); } context.write(key,new IntWritable(sum)); } } - 编写MR程序之Job:LogJob.java
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LogJob { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(LogJob.class); job.setMapperClass(LogMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(LogReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job,new Path("F:\\NIIT\\hadoopOnWindow\\input\\logs\\access2.log")); FileOutputFormat.setOutputPath(job,new Path("F:\\NIIT\\hadoopOnWindow\\output\\logs\\002")); boolean completion = job.waitForCompletion(true); } } - 本地运行代码,测试下结果正确与否
- 本地运行测试结果正确后,需要对Driver类输入输出部分代码进行修改,具体修改如下:
FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); - 打jar包,提交集群运行
- 为方便操作,编写脚本exec_mr.sh来执行MR程序
#!/bin/bash #执行MapReduce程序 dataformat=`date +%Y-%m-%d-%H-%M-%S` /training/hadoop-2.7.3/bin/hadoop jar log.jar $(cat mr_input_path.txt) /output/result/$dataformat /training/hadoop-2.7.3/bin/hdfs dfs -cat /output/result/$dataformat/part-r-00000 > mr_result.txt echo $(cat mr_result.txt)
十、SQOOP安装配置
-
上传sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz到/tools目录下
-
解压安装
tar -zvxf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /training/ -
配置环境变量
#sqoop export SQOOP_HOME=/training/sqoop-1.4.7.bin__hadoop-2.6.0 export PATH=$PATH:$SQOOP_HOME/bin -
配置sqoop文件(两个文件)
- 修改
将出现HCAT_HOME和ACCUMULO_HOME部分内容注释掉.vi /training/sqoop-1.4.7.bin__hadoop-2.6.0/bin/configure-sqoop - 修改sqoop-site.xml和sqoop-env.sh
具体配置如下文件所示:vi /training/sqoop-1.4.7.bin__hadoop-2.6.0/conf/sqoop-site.xml vi /training/sqoop-1.4.7.bin__hadoop-2.6.0/conf/sqoop-env.sh
sqoop-site.xml:
sqoop-env.sh:<configuration> <property> <name>sqoop.metastore.client.enable.autoconnectname> <value>truevalue> <description>If true, Sqoop will connect to a local metastore for job management when no other metastore arguments are provided. description> property> <property> <name>sqoop.metastore.client.autoconnect.urlname> <value>jdbc:hsqldb:file:/tmp/sqoop-meta/meta.db;shutdown=truevalue> <description>The connect string to use when connecting to a job-management metastore. If unspecified, uses ~/.sqoop/. You can specify a different path here. description> property> <property> <name>sqoop.metastore.client.autoconnect.usernamename> <value>SAvalue> <description>The username to bind to the metastore. description> property> <property> <name>sqoop.metastore.client.autoconnect.passwordname> <value>value> <description>The password to bind to the metastore. description> property> <property> <name>sqoop.metastore.client.record.passwordname> <value>truevalue> <description>If true, allow saved passwords in the metastore. description> property> <property> <name>sqoop.metastore.server.locationname> <value>/tmp/sqoop-metastore/shared.dbvalue> <description>Path to the shared metastore database files. If this is not set, it will be placed in ~/.sqoop/. description> property> <property> <name>sqoop.metastore.server.portname> <value>16000value> <description>Port that this metastore should listen on. description> property> configuration>#Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/training/hadoop-2.7.3 #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/training/hadoop-2.7.3
- 修改
-
将MySQL数据库的驱动(使用5.x版本,不要使用高版本的)上传到sqoop安装目录下的lib目录下
-
由于sqoop缺少java-json.jar包进行解析json,也需要上传到sqoop安装目录下的lib目录下
-
验证
sqoop version -
创建数据库表t_mr_result,创建语句:
CREATE TABLE `t_mr_result` ( `goodsId` varchar(150) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '商品ID', `goodsViewCount` int(50) DEFAULT NULL COMMENT '商品浏览总数' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci -
编写sqoop从hadoop导出数据到MySQL的脚本
#!/bin/bash /training/sqoop-1.4.7.bin__hadoop-2.6.0/bin/sqoop export \ --connect jdbc:mysql://192.168.112.129:3306/shop \ --username root \ --password Sjm@!_123456 \ --input-fields-terminated-by '\t' \ --table t_mr_result \ --export-dir $(cat result_path.txt) --class-name UpsertMrResult --update-key goodsId --update-mode allowinsert
10.测试
十一、集成调试
十二、源码
- 前端网站源码
https://gitee.com/sujiangming/online-shop/tree/master - 后台系统源码及相关脚本
https://gitee.com/sujiangming/online-shop-back-system