1. 概述
该方案写作目的在于描述一个基于Locust实现的压力测试,文中详细地描述了如何利用locustfile.py文件定义期望达成的测试用例,并利用Locust对目标站点进行并发压力测试。
特别说明:
本文档所使用的 Locust 环境一键安装自 Rainbond 开源应用商店中的 Locust 应用。版本为0.14.4,更高版本的特性和语法,烦请参见 Locust 官方文档。
关于Locust这个压力测试工具,其官网与文档,请关注如下链接:
Locust官方网站地址
Locust官方文档
如果不想阅读英文文档,那么强烈建议先读如下链接中的内容:
分布式压力测试工具Locust在Rainbond上的部署
接下来,我将重点讲解不同场景下的 locustfile.py 的写作方法。
首先,我们聊一聊什么是 locustfile.py。
2. 什么是locustfile.py
Locust通过识别 /locustfile.py 来获悉压力测试任务的细节,这个文件的路径当前是默认值。
如果你利用Rainbond应用市场一键安装部署了 Locust 集群,那么你可以在 locust_master 组件的 环境配置 > 配置文件设置 中找到已挂载的该文件,如有必要,只需要修改里面的内容,然后更新整个应用(包括 locust_master 和 locust_slave集群)。
locustfile.py 是一个标准的 python 脚本文件,通过官方指定的方式,你可以在这个文件里定义特定的类 ,通过类实例化之后,就会“孵化”出符合定义的实例,模仿用户对被测试的目标站点“群起而攻之”,就像蝗虫(Locust)一样,这就是 Locust 得名的由来。
3. 写作的要领
locustfile.py文件的写作,核心是规定了两个类(class),它们分别继承由locust导入的 HttpLocust 、TaskSet 两个超类。
-
继承自 HttpLocust 的类,是 Locust 调用的入口。
-
继承自 TaskSet 的类,用于定义虚拟用户要模拟的任务。
简要的写作方式如下面的代码所示:
from locust import HttpLocust, TaskSet, between, task
class MyTaskSet(TaskSet):
@task(1)
def task1(self):
do task1
@task(2)
def task2(self):
do task2
@task(3)
def task3(self):
do task3
@task(4)
def task4(self):
do task4
class Mytest(HttpLocust):
task_set = MyTaskSet
wait_time = between(5.0, 10.0)
在这个 locustfile.py 中,我依次做了这些事:
- 由模块 locust 导入了类:HttpLocust, TaskSet, between, task。
- 定义了一个类,名为 MyTaskSet,该类继承自 TaskSet,具备 TaskSet 所有的方法和属性。这个类中,后续定义的所有新的方法,都可以视作压力测试要执行的任务。
- 依次定义了task1 - task4 四个新的方法,如何让 Locust 知道这些方法是要执行的任务呢?关键在于装饰器
@task,装饰器包装了新定义的方法,告知 Locust 这个方法是一个要执行的任务。圆括号中的数字,用来表示任务执行的权重,即一个虚拟的用户,会执行被包装的方法(即任务)指定的次数,需要指出的是,执行的顺序是随机的,如何定义执行顺序将在后文讲解。 - 定义了一个类,名为 Mytest,该类继承自 HttpLocust,具备 HttpLocust 所有的方法和属性。这个类通过属性
task_set = MyTaskSet定义Locust要执行指定的任务类(就是上一个自定义的类),通过wait_time = between(5.0, 10.0)来定义虚拟用户执行每个任务间隔的时间,当前的写法,是指定间隔时间为5s至10s中的随机值。
一个 locustfile.py 的基本框架即是如此。当然还可以有其它的方式来定义这个文件,但是我认为这种写作方式已经足够,而且明了。
关于 wait_time ,这是一个很必要的属性。Locust 的开发者认为,真正的用户行为,并不会像机器人一样迅速而接连不断地执行所有任务。大家都会有这样的体验,访问到一个页面后,会东瞧瞧,西看看,或者干脆发会儿呆,心满意足之后,再点击下个页面进行下一个流程。所以在这里会定义 wait_time 来明确两个任务间隔时间。
至此,我们基本可以明确,真正的难点在于如何定义任务类。至于 Mytest 这个类,大多数情况下复制上面的代码,就已经足够了。
4. 典型的场景
下面我们来聊一聊,在以下几个典型的场景下,该如何定义任务类:
- get请求
- post请求
- 获取响应
- 猴子测试
- 流程测试
4.1 get请求
这是一种最简单的场景,一般情况下,我们会通过 get 方法,来请求站点的静态页面资源,比如 /index.html 这样的路径。
简要代码如下:
class MyGet(TaskSet):
@task
def index(self):
self.client.get("/index.html")
这就定义了一个简单的压测目标站点 "/index.html" 的get请求。
4.2 post请求
post请求一般用于带着参数访问站点的指定接口,来实现一些特定的功能,比如登陆行为。
简要代码如下:
class MyPost(TaskSet):
@task
def login(self):
self.client.post("/login", {"username":"admin", "password":"mypassword"})
这就定义了一个post请求,用来携带着用户名密码进行一次登陆。
关于 client ,官方的介绍称之为 Locust 实例化过程中,类 HttpSession 生成的一个实例。这个实例支持保存 Cookies,以实现保持 Http 请求之间的 session。个人认为,没必要细究,首先了解如何建立请求,其次需要了解在发起请求之后,如何获取响应(response)的详情。做法在下个小节中讲述。
4.3 获取响应
在一些请求完成后,其响应(response)的内容往往非常关键。在这里最重要的有两点:
- 返回的状态码。这直接标明这次请求大致的结果,默认 2xx、3xx这样的状态码表示请求成功;4xx、5xx反之,但是凭借状态码不一定能够完全判定请求的接口是否真的按照预想的情况工作,详细的内容请见后文断言一节。在这里,我们需要知道状态码是 Locust 判定请求是否成功的默认条件。
- 返回的内容。请求接口返回的内容(一般情况下是个Json),有的时候携带了非常重要的信息,比如后文要描述的对某个 CRM 系统的压力测试实例中,我们需要通过登陆请求后返回内容中的
authKey来定义后续请求,以实现登陆态。
Locust中的所有请求,都可以通过下面的方法获得状态码和返回的内容:
获取返回状态码:
response = self.client.get("/about")
print("Response status code:", response.status_code)
即实例 response.status_code 返回了这次请求的状态码。
获取返回的内容:
response = self.client.get("/about")
print("Response content:", response.text) #返回字符串
print("Response content:", response.json()) #返回Json,可以作为字典处理
4.4 猴子测试
假设一只“猴子”作为用户,它不会按照正常的业务流程去使用业务系统,而是瞎搞一气,还没注册就登陆,没有选择商品就要付钱。这可以帮助我们发现更多在正常业务流程之外的BUG。
我们已经了解到如何定义一些普通的请求方式,来请求我们所有已知的接口,那么我们只需要把这些任务统统放进我们的 TaskSet 类中,随机定义任务被调用的权重即可形成一个猴子测试的任务设定。最终,我们会发现这个猴子测试使用的 locustfile.py 和我在 [写作的要领](#3. 写作的要领) 一节中展示的模版文件大同小异。故此这里就不再赘述了。
4.5 流程测试
在这里我想表达如何进行一次对某一业务流程的顺序测试。和之前的猴子测试不同,我会在这个测试中规划一个正确的流程。如果这个流程可以走得通,并承受住大并发压力的考验,那么就可以认为业务系统通过了测试。
这份 locustfile.py 和之前的模版会有一些不同,主要在于我们想要定义顺序执行,而非随机调用的任务。所以我们生成的任务类不再继承自 TaskSet,而是继承自 TaskSequence 。后者是前者的子类,但是新增了顺序调用的方法,搭配新的装饰器 @seq_task ,这样我们就可以定义所有任务的执行顺序了。
流程测试是这个方案的重点,所以我专门找了一个CRM系统,来作为测试的受体,然后对 登陆 —— 获取用户列表 —— 新增用户 —— 删除用户 —— 登出 这一流程做压力测试。
特意指出,在这里我不仅使用了类似 self.client.get()、self.client.post() 等相对简单明确的方法,还使用了更基础的 self.client.request()方法,这个方法可以通过传递参数来实现和 post 以及 get 一样的效果。了解更多请看看这里。
来看看代码:
from locust import HttpLocust, TaskSequence, between, task, seq_task
import random, string
class MyTaskSet(TaskSequence):
login_header = {}
del_params = {}
@seq_task(1)
def login(self):
to_login = self.client.post("/index.php/admin/base/login", {"username":"184xxxxxx66", "password":"mypassword"})
self.login_header['authKey'] = to_login.json()["data"]["authKey"]
self.login_header['sessionId'] = to_login.json()["data"]["sessionId"]
self.login_header['Cookie'] = 'PHPSESSID=' + to_login.json()["data"]["sessionId"]
print(to_login.json())
@seq_task(2)
def get_customer(self):
to_get = self.client.request(method="post", url="/index.php/crm/customer/index", params={"page":1, "limit":15}, headers=self.login_header)
print(to_get.json())
@seq_task(3)
def add_customer(self):
self.add_params={"level":"A(重点客户)", "industry":"金融业", "source":"促销活动", "deal_status":"未成交", "telephone":"13555555555"}
self.add_params['name'] = ''.join(random.sample(string.ascii_letters + string.digits, 8)) #随机生成客户名
to_add = self.client.request(method="post", url="/index.php/crm/customer/save", params=self.add_params, headers=self.login_header)
self.del_params["id[0]"] = to_add.json()['data']['customer_id']
print(to_add.json())
@seq_task(4)
def del_customer(self):
to_del = self.client.request(method="post", url="/index.php/crm/customer/delete", params=self.del_params, headers=self.login_header)
print(to_del.json())
@seq_task(5)
@task(3)
def index(self):
self.client.get("/index.php/admin/system/index")
@seq_task(6)
def logout(self):
self.client.post("/index.php/admin/base/logout")
class Mytest(HttpLocust):
task_set = MyTaskSet
wait_time = between(5.0, 10.0)
接下来讲解下和最开头的模版不一样的地方:
- 新导入了
TaskSequence、seq_task,前者是TaskSet的替代者,用于实现顺序调用任务,后者是新的装饰器,来定义任务的调用顺序。 - 新导入
random, string模块,来为新增的用户随机生成用户名,CRM系统规定用户名不可以相同。 - 任务类
MyTaskSet继承自TaskSequence。 - 通过
@seq_task()来装饰任务,圆括号中的数字代表执行顺序。 - 为所有任务实例定义新的属性
login_header、del_params,初始值均为空的字典,在任务执行过程中,会将保持登陆态所需要的header信息保存进去以供其他行为调用、保存新增用户的特殊ID,以供删除操作使用。 - 登陆过程完成后,收集请求的响应内容(Json格式),经过操作,更新实例的
login_header属性,将保持登陆态所使用的authKeyCookiesessionId保存起来。 - 打印每个任务的响应内容,这样可以在后台日志中清楚地看到每个任务的执行情况,这对于发现BUG非常有用。
- 有关如何知悉新增用户或者删除用户流程中所传递的参数,将在下一节讲解。
整个流程测试任务的重点,在于明确地规划好整个测试的任务流程。在执行流程测试的时候,一定要保证业务是按照我们预先设计好的流程进行,这样才可以发现在大并发压力下,我们的业务系统是否正常表现。
对于这个例子而言,登陆后的操作如何保持登陆态?新建用户要传递哪些参数?删除用户的凭据是什么?这三个问题是保障整个流程顺利进行的重点,而这三个问题的答案都在于请求时传递哪些参数。
根据官方文档介绍,client实例具备了保存Cookie与Session的功能,但是并非所有的业务系统保持登陆态都依赖于这两个参数。比如例子中的 CRM 系统,保持登陆态还需要获取参数 authKey。所以,无论如何,都需要自行定义保持登陆态的操作。
5. 请求的参数
这里所说的参数,是一个广义的概念,实际上包括了 params、header ,甚至在某些情况下还需要 data 、auth等等数据。
有很多的时候,被测试的业务系统,并不是我们自己设计的,我们并不知道这些 “参数” 究竟包含什么,在这一节,我想要阐述一个方法,可以通过浏览器来帮助我们获取这些“参数”。
对于 B/S 架构程序而言,我们通过浏览器进行的所有操作,都是有迹可循的。打开浏览器的 检查 (一般情况下,默认快捷键 F12),选择 Network 并进行操作,就可以获悉我们通过浏览器到底做了什么。
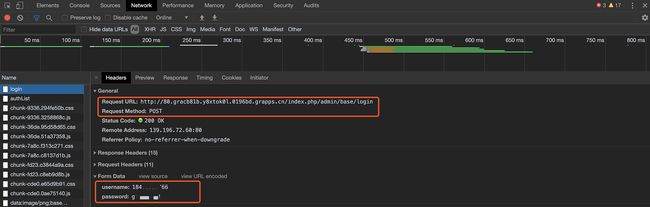
下面是一个例子,模拟了CRM系统在登陆时的行为:
-
通过
Request URL获取所有的路由信息,这个URL由业务系统的域名和接口路径组成。域名在 Locust的WEB-UI中写入,接口路径作为参数 url 传递给任务中的请求。 -
通过
Request Method我们可以知道这是一个 POST 请求。 -
最下面,是通过
params传递登陆参数,这里定义的是用户名和密码。
结合下实际的请求,这会更利于理解:
self.client.post(url="/index.php/admin/base/login", params={"username":"184xxxxxx66", "password":"xxxxxxxx"})
实际上参数名可以省略,用以上参数,就可以获取执行请求的全部参数了。
那么请求成功后,会得到什么返回呢?
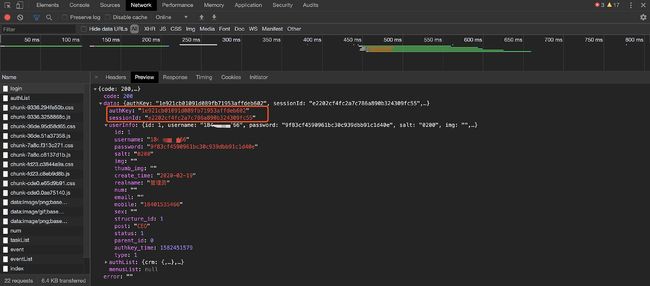
切换到 Preview 或者 Response 页面,可以得到接口的返回,建议看 Preview 。
- 在这里,我们最想要得到的是
authKey和sessionId这两个值,结合与sessionId相关的Cookie就可以获得保持登陆态的所有参数。
接下来,我们来执行列示用户的操作,访问用户管理页面,选择用户,可以得到 getField这个接口的请求信息,这里要重点关注 Request Header 部分,因为我们需要从这里获悉如何保持登陆态。
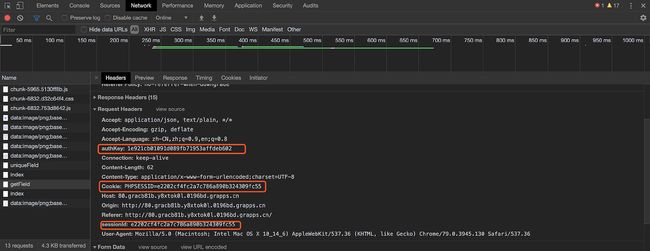
看到这里,我们就明确了,为什么在登陆时会返回 authKey 和 sessionId ,其实是在请求头 (Request Header)加入这些信息来保持登陆态。
通过分析浏览器中的请求信息,我们就可以知道特定的流程中浏览器为我们做了哪些事,接着就可以去定义测试任务了。
6. 断言
前文已经说过,Locust 默认通过请求返回的状态码来判断这次请求是否成功,但是这还不够。我在测试CRM的时候,发现了一个问题。
我没有执行登陆操作,直接去列示了所有用户,这个操作返回给我如下回复:
>>> to_get = l.client.request(method="post", url="/index.php/crm/customer/index", params={"page":1, "limit":15})
>>> to_get.status_code
200
>>> to_get.json()
{'code': 101, 'error': '请先登录'}
状态码返回200,这将导致Locust 认为该请求执行成功。
CRM的处理也是正确的,我没有登陆,却请求了这个端口,CRM非常明确地处理了这个问题,告诉我“请先登录”。
但是从我自定义的业务流程上讲,这是个错误,我并没有获取我预期的所有用户的列表。我希望在Locust的结果分析中,将这种情况视作失败的请求,所以,我需要一个断言。
断言就是分析请求的返回,即使状态码返回2xx、3xx,也可以根据返回内容将任务判定为失败状态,反之亦然。
Locust 中断言的实现,是在请求中设置 catch_response=True 参数来抓获返回,再进行判断。
我们来优化CRM测试任务中有关get_customer方法的代码:
@task
def get_customer(self):
with self.client.request(method="post", url="/index.php/crm/customer/index", params={"page":1, "limit":15}, catch_response=True) as to_get:
if to_get.json() == {'code': 101, 'error': '请先登录'}:
to_get.failure("它告诉我要先登陆")
执行压力测试后,我的目的达到了:
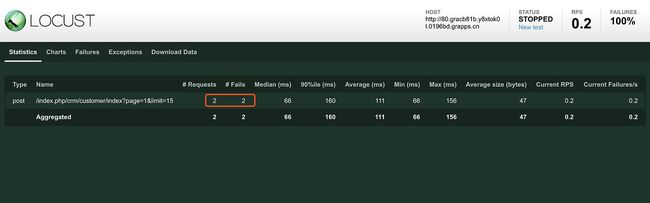
结果分析也抛出了我已经设定好的消息:

7. 压力
使用Locust的一大好处就是它可以模拟很大的压力,这里我不去描述它在实现原理上有何优势,而是想向大家介绍它的分布式特点。Locust支持主从集群模式,主节点(locust_master)负责压力测试任务的调度,从节点(locust_slave)负责具体的用户模拟和测试的执行。其中,从节点支持分布式部署。也就是说,如果需要,就可以使用Rainbond的横向伸缩功能扩展出很多 locust_slave 的实例,能够模拟的压力也就随之增大。
这一节,我们来描述在WEB-UI界面中如何定义压力。
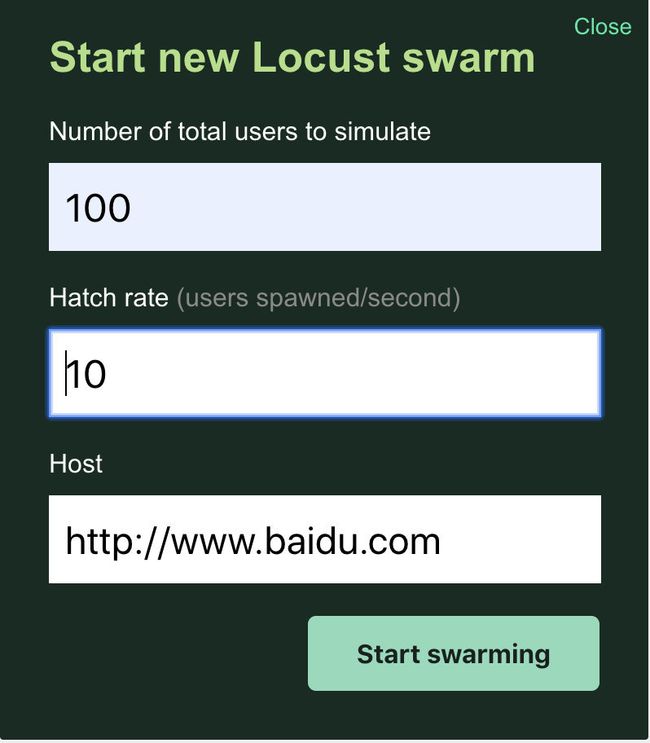
访问 locust_master 服务组件的 8089 端口,会进入到WEB-UI界面,并开始规划一个新的压力并发。
-
第一个值规定了本次测试的最大模拟用户数量,即并发。
-
第二个值规定每秒“孵化”的用户数量,如图中的配置,开始测试后,Locust将在十秒钟内启动100个用户。
-
测试站点的域名,这里有一点要注意,就是一定要带协议头,即 "http://"。
那么,Locust能提供多大压力,是否有个衡量呢?我执行的一个测试显示,3个slave的 Locust可以轻松提供5000并发。

而被压测的CRM已经超出了能接受的压力极限,开始出现大量的错误,使用的内存急剧飙升到了90%以上,Locust 得出的 Failures 页面报告了错误产生的原因。

8. 结果分析
借助Locust提供的WEB-UI界面,我们可以非常方便地分析压力测试结果。
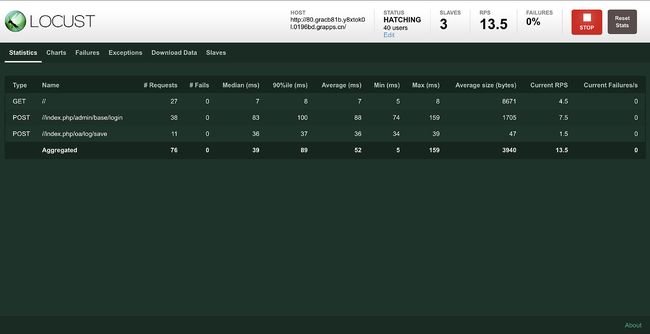
Statistics页面将向我们展示所有被压测接口的汇总报告,结果包括:
请求总数、失败次数、中位数响应时间、90%请求响应时间、平均响应时间、最小响应时间、最大响应时间、请求的平均大小、当前吞吐率、当前错误率。
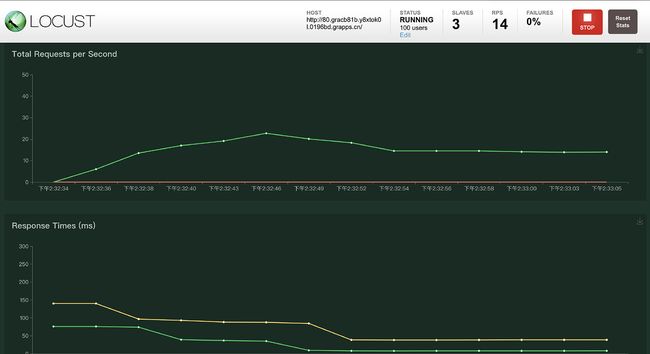
Charts页面将主要结果绘制成为随时间变化的图表,能够在趋势上给予用户指引。
除了这些之外,还有几项值得关注的值会在最上面一排全局展示,包括当前请求的主机域名、当前产生的并发用户数量、slave节点数量、当前所有请求接口的总吞吐率、错误率,以及停止测试的按钮。
其它的几个页面会提供请求失败的接口及失败原因(Failures)、测试中意外的错误以及错误原因(Expections)、csv格式的测试数据下载地址(Download Data)、 所有slave实例的信息(Slaves)。
所有的数据都基于图形展示,十分方便。
9. 写在最后
Locust 是一个相当不错的压力测试工具,可自由定制的东西很多,我写在这个方案中的种种用法还不足以囊括它的所有特性,但是 Good Enough is Best ,这个方案已经可以应付绝大多数场景了。
Rainbond 是一个开源的云原生应用管理平台,使用简单,不需要懂容器和Kubernetes,支持管理多个Kubernetes集群,提供企业级应用的全生命周期管理,功能包括应用开发环境、应用市场、微服务架构、应用持续交付、应用运维、应用级多云管理等。
