hadoop搭建和笔记
分布式云平台HADOOP
统一思维
Hadoop介绍
HDFS理论
HDFS集群搭建
CLI使用
API使用
并行:提升速度的关键
分布式运行
计算与数据在一起
存+算(文件切割的规范管理)
计算向数据移动
Net music log、有限电视
分布式
分而治之:并行计算
计算向数据移动
需要管理、规范化操作
Hadoop简介
Hadoop分布式文件系统HDFS
Hadoop分布式计算框架MR
Hadoop体系架构
Hadoop安装
Hadoop shell
Hadoop API
Hadoop的思想之源:Google(第一个遇到大量数据计算问题的公司)
Openstack: NASA
面对的数据和计算难题
大量的网页怎么存储
搜索算法(倒排索引的计算)
带给我们的关键技术和思想(Google 三大理论)
GFS
Map-Reduce
Bigtable
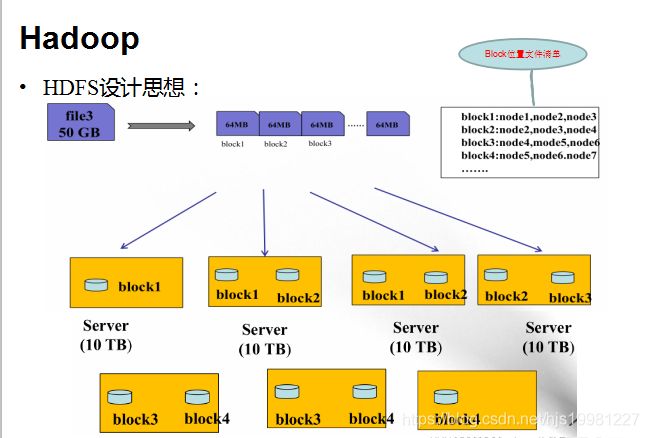
存储模型:字节
文件线性切割成块(Block):偏移量 offset (byte,中文?)
Block分散存储在集群节点中
单一文件Block大小一致,文件与文件可以不一致
Block可以设置副本数,副本无序分散在不同节点中
副本数不要超过节点数量
文件上传可以设置Block大小和副本数(资源不够开辟的进程)
已上传的文件Block副本数可以调整,大小不变
(2.x 128MB 3 blocks)
只支持一次写入多次读取,同一时刻只有一个写入者
可以append追加数据
架构模型:
文件元数据MetaData,文件数据
元数据
数据本身
(主)NameNode节点保存文件元数据:单节点 posix
(从)DataNode节点保存文件Block数据:多节点
DataNode与NameNode保持心跳,提交Block列表
HdfsClient与NameNode交互元数据信息
HdfsClient与DataNode交互文件Block数据(cs)
DataNode 利用服务器本地文件系统存储数据块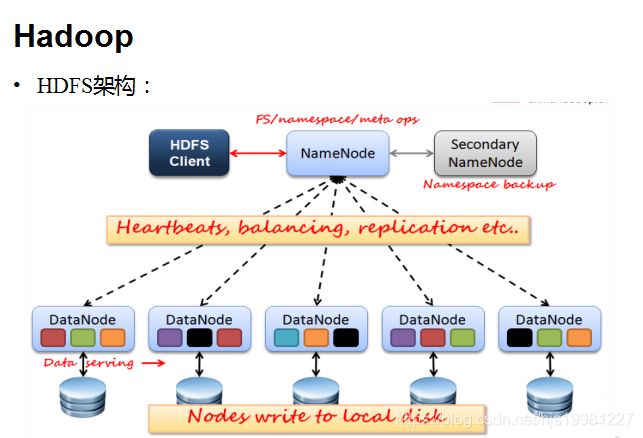
各节点的工作内容
NameNode(NN)
基于内存存储 :不会和磁盘发生交换(双向)
只存在内存中
持久化(单向)
NameNode主要功能:
接受客户端的读写服务
收集DataNode汇报的Block列表信息
NameNode保存metadata信息包括
文件owership和permissions
文件大小,时间
(Block列表:Block偏移量),位置信息(持久化不存)
Block每副本位置(由DataNode上报)
NameNode持久化
NameNode的metadata信息在启动后会加载到内存
metadata存储到磁盘文件名为”fsimage”(时点备份)
Block的位置信息不会保存到fsimage
edits记录对metadata的操作日志…>Redis
二者的产生时间和过程?(format)
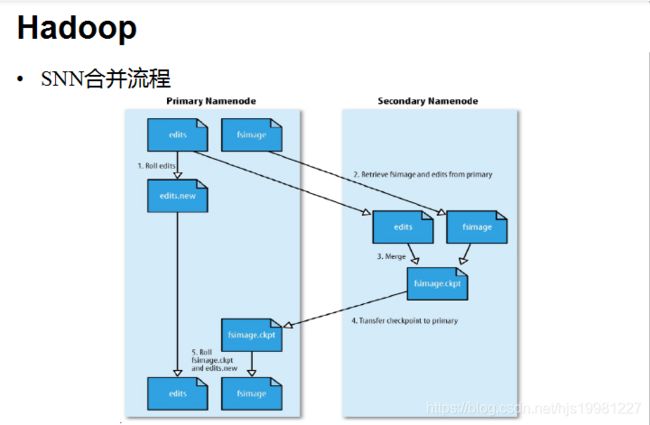
SecondaryNameNode(SNN)
它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
SNN执行合并时机
根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
• 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
DataNode(DN)
本地磁盘目录存储数据(Block),文件形式
同时存储Block的元数据信息文件
启动DN时会向NN汇报block信息
通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的 block到其它DN
HDFS优点:
高容错性
数据自动保存多个副本
副本丢失后,自动恢复
适合批处理
移动计算而非数据
数据位置暴露给计算框架(Block偏移量)
适合大数据处理
GB 、TB 、甚至PB 级数据
百万规模以上的文件数量
10K+ 节点
可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复 机制
HDFS缺点:
低延迟数据访问
比如毫秒级
低延迟与高吞吐率
小文件存取
占用NameNode 大量内存
寻道时间超过读取时间
并发写入、文件随机修改
一个文件只能有一个写者
仅支持append
Block的副本放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
HDFS写流程
Client:
切分文件Block
按Block线性和NN获取DN列表(副本数)
验证DN列表后以更小的单位流式传输数据
各节点,两两通信确定可用
Block传输结束后:
DN向NN汇报Block信息
DN向Client汇报完成
Client向NN汇报完成
获取下一个Block存放的DN列表
。。。。。。
最终Client汇报完成
NN会在写流程更新文件状态
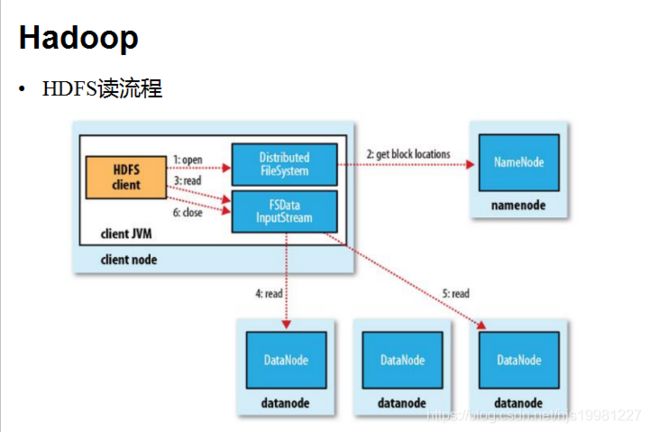
HDFS读流程
Client:
和NN获取一部分Block副本位置列表
线性和DN获取Block,最终合并为一个文件
在Block副本列表中按距离择优选取
MD5验证数据完整性
HDFS文件权限 POSIX标准(可移植操作系统接口)
与Linux文件权限类似
r: read; w:write; x:execute
权限x对于文件忽略,对于文件夹表示是否允许访问其内容
如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS的权限目的:阻止误操作,但不绝对。HDFS相信,你告诉我你是谁,我就认为你是谁。
安全模式
namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一 个空的编辑日志。
此刻namenode运行在安全模式。即namenode的文件系统对于客服端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败,尚未获取动态信息)。
在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的, 在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中。
集群
角色==进程
namenode
数据元数据
内存存储,不会有磁盘交换
持久化(fsimage,edits log)
不会持久化block的位置信息
block:偏移量,因为block不可以调整大小,hdfs,不支持修改文件
偏移量不会改变
datanode
block块
磁盘
面向文件,大小一样,不能调整
副本数,调整,(备份,高可用,容错/可以调整很多个,为了计算向数据移动)
SN
NN&DN
心跳机制
DN向NN汇报block信息
安全模式
client
一,操作系统环境
依赖软件ssh,jdk
环境的配置
java_home
免密钥
时间同步
hosts,hostname
二,hadoop部署
/opt/sxt/
配置文件修改
java_home
角色在哪里启动
Client:
写
线性上传block
先和NN通信,元数据,获取第一个block的节点信息(3副本,选择机制)
和DN通信:pipeline:C和1stDN有socket,1stDN和2edDN有socket。。。。
小片传输:4K,C给1stDN,1stDN同时本机缓存,瞬间放入下游socket中
当block传输完毕:block自身的网络I/O时间,时间线重叠的艺术
DN会向NN汇报自己新增的block
C向NN汇报blockX传输完成给我下一个block节点信息
全部传输完成,NN更新元数据状态可用
读
线性读取block,不会有并发,只有一个网卡
距离:择优选取同机架,同节点
NN每次只给一部分block信息
安装
1,jdk安装,配置环境变量
vi /etc/profile
2,ssh免密钥(本机)
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3,上传hadoop.tar.gz到服务器
解压,mv hadoop-2.6.5 /opt/sxt
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_PREFIX=/opt/sxt/hadoop-2.6.5
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: H A D O O P P R E F I X / b i n : HADOOP_PREFIX/bin: HADOOPPREFIX/bin:HADOOP_PREFIX/sbin
4,/opt/hadoop-2.6.5/etc/hadoop
*-env.sh
JAVA_HOME=/usr/java/jdk1.7.0_67
core-site.xml配置
fs.defaultFS
hdfs://node01:9000
hadoop.tmp.dir
/var/sxt/hadoop/local
hdfs-site.xml配置
dfs.replication
3
dfs.namenode.secondary.http-address
node01:50090
slaves
hdfs namenode -format --格式化
start-dfs.sh --启动
jps --查看进程
28341 SecondaryNameNode
28102 NameNode
28207 DataNode
28480 Jps
hdfs dfs -mkdir /user --在hdfs上创建文件夹
hdfs dfs -ls /user --查看hdfs的/user下的文件
http://192.168.9.11:50070 --浏览器查看hadoop
for i in seq 100000;do echo “hello $i” >> test.txt;done -把hello打印10000遍,并输出到test.xml文件夹上
安装完全分布式

关停集群: stop-dfs.sh
1, 每台服务器要
安装jdk
/etc/hosts (别名,通讯)
调整时钟
配置环境变量
免密钥登陆
控制节点scp自己的id_dsa.pub分发到其他节点
cat ~/node1.pub >> ~/.ssh/authorized_keys
mkdir /opt/sxt
2,取一个节点:
配置Hadoop的配置文件:见第二页
3,分发部署包到其他节点
cd /opt/sxt
scp -r hadoop-2.6.5 node02:pwd
scp -r hadoop-2.6.5 node03:pwd
scp -r hadoop-2.6.5 node04:pwd
core-site.xml配置
fs.defaultFS
hdfs://node01:9000
hadoop.tmp.dir
/var/sxt/hadoop/full
hdfs-site.xml 配置
dfs.replication
3
dfs.namenode.secondary.http-address
node02:50090
slaves配置
node02
node03
node04
4,确认之前的hadoop进程是否停到了
jps
5,hdfs namenode -format (node01)
6,start-dfs.sh
7,每个节点jps验证,node01:50070
eclipse配置hadoop
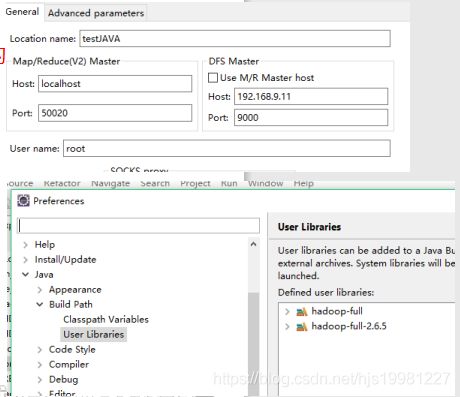
1,解压部署,添加环境变量
2,将tools目录下的bin目录覆盖部署目录
3,备份eclipse,将hadoop的插件放入eclipse的plugins下
4,启动eclipse,添加map/reduce视图
5,创建hdfs连接:
6,整理部署目录内的jar包:
C:\var\sean\hadoop-2.6.5\share\hadoop
hdfs,common,mapreduce,tools,yarn
目录内的jar包全部拷贝一份出来
7,eclipse创建用户库导入刚才的jar包:
8,新建一个java项目
导入hadoop的jar包
创建一个conf目录
从集群下载core-site.xml hdfs-site.xml
平台
GNULinux
模式:
local
pseudo
full
依赖:
java
2次配置(系统环境,脚本再次制定)
ssh
免密钥
下载hadoop
配置:配置文件
1,jdk安装
/etc/profile
~/.bashrc
2,ssh:避免输入密码
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_dsa.pub root@node02:pwd/node01.pub
cat node01.pub >> ~/.ssh/authorized_keys
3,,可以不会
for i in seq 4; do
cat k | sed "s/(node0)1(,192.168.9.1)1(.)/\1KaTeX parse error: Undefined control sequence: \2 at position 2: i\̲2̲i\3/gi" >> known_hosts;
done
4,解压缩:
mkdir /opt/sxt/
tar xf hadoop*.tar.gz
5,hadoop/etc/hadoop
*-env.sh
core-site.xml配置
fs.defaultFS hdfs://node01:9000 hadoop.tmp.dir /var/sxt/hadoop-2.6.5 ##### hdfs-site.xml配置 dfs.replication 1 hdfs dfs namenode -format --格式化节点 start-dfs.sh --启动节点1,格式化hdfs namenode -format
2,启动hdfs
start-dfs.sh
3, hdfs dfs -mkdir -p /user/root 创建多级目录
4,hdfs dfs -D dfs.blocksize=1048576 -put **. 上传文件, 最大大小 指定文件大小
HDFS API
解压hadoop包:不能有中文,空格,特殊字符
创建环境变量,放到PATH
eclipse拷贝一份,备份
将eclipse-hadoop的插件放入eclipse
eclipse:设置:hadoop mr设置:配置你解压的hadoop路径
操作系统:计算机管理:本地用户和族:用户:重命名你登陆的账户为:root
Configuration
true/false
FileSystem
create/open:
FSDataOutputStream
FSDataInputStream
seek();
思路:计算和数据在一起了,但是不要再从头开始读取数据
getFileStatus: FileStatus
getFileBlockLocations: BlockLocation[]
思路:计算向数据移动的参考
HDFS安装
伪分布式安装
完全分布式安装
下载
解压
检查java和ssh的免密码登陆
修改core-site.xml
修改hdfs-site.xml
修改masters文件和slaves文件
格式化namenode
Start-hdfs.sh启动
注意:
/etc/hosts
每个节点都要配置:IP 主机名
6,配置
Hadoop-env.sh 配置java的绝对路径
core-site.xml配置
fs.defaultFS hdfs://node001:9000 hadoop.tmp.dir /var/sxt/hadoop-2.6/fully注意:hadoop.tmp.dir默认是/tmp/目录,需要手动指定一个持久目录
hdfs-site.xml配置
dfs.replication 3 dfs.namenode.secondary.http-address node002:50090 注意:伪分布式,副本数为1 设置SNN的http-address的节点主机名会让SNN去具体的节点启动 slaves node002 node003 node004 这个配置文件是datanode所在的节点 启动 hdfs namenode –format 去观察hadoop.tmp.dir设置的目录变化 注意,这个目录必须是空的 如果,报错等,想重新格式化,需要先删除 start-dfs.sh 去datanode节点,验证hadoop.tmp.dir目录 注意:HDFS集群有clusterID,datanode启动时会和namenode对比clusterID,如果相同,启动成功,如果不同,自杀进程hadoop2.x 产生背景
Hadoop 1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
HDFS存在的问题(2个)
NameNode单点故障,难以应用于在线场景 HA
NameNode压力过大,且内存受限,影扩展性 F
MapReduce存在的问题响系统
JobTracker访问压力大,影响系统扩展性
难以支持除MapReduce之外的计算框架,比如Spark、Storm等
Hadoop 1.x与Hadoop 2.x
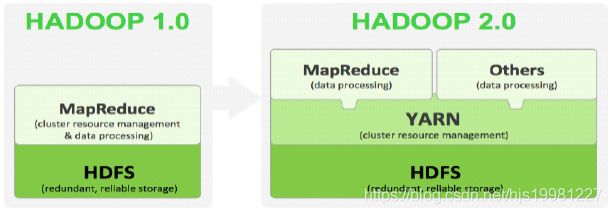
Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成;
HDFS:NN Federation(联邦)、HA;
2.X:只支持2个节点HA,3.0实现了一主多从
MapReduce:运行在YARN上的MR;
离线计算,基于磁盘I/O计算
YARN:资源管理系统
HDFS 2.x
解决HDFS 1.0中单点故障和内存受限问题。
解决单点故障
HDFS HA:通过主备NameNode解决
如果主NameNode发生故障,则切换到备NameNode上
解决内存受限问题
HDFS Federation(联邦)
水平扩展,支持多个NameNode;
(2)每个NameNode分管一部分目录;
(1)所有NameNode共享所有DataNode存储资源
2.x仅是架构上发生了变化,使用方式不变
对HDFS使用者透明
HDFS 1.x中的命令和API仍可以使用
高可用图
HDFS 2.0 HA
主备NameNode
解决单点故障(属性,位置)
主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
所有DataNode同时向两个NameNode汇报数据块信息(位置)
JNN:集群(属性)
standby:备,完成了edits.log文件的合并产生新的image,推送回ANN
两种切换选择
手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
自动切换:基于Zookeeper实现
基于Zookeeper自动切换方案
ZooKeeper Failover Controller:监控NameNode健康状态,
并向Zookeeper注册NameNode
NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
HDFS 2.x Federation
通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器来进行水平扩展。
能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中。
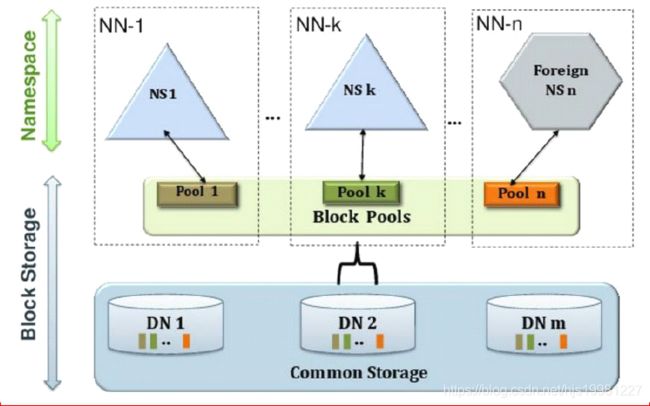
在思考和讨论的时候
一定要确定是HA高可用 还是 Federation 联邦
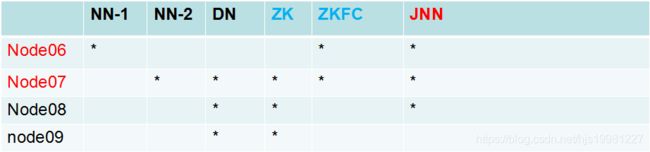
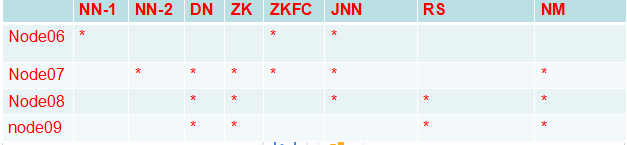
hdfs-site.xml
dfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 node06:8020 dfs.namenode.rpc-address.mycluster.nn2 node07:8020 dfs.namenode.http-address.mycluster.nn1 node06:50070 dfs.namenode.http-address.mycluster.nn2 node07:50070hdfs-site.xml
dfs.namenode.shared.edits.dir qjournal://node06:8485;node07:8485;node08:8485/mycluster dfs.journalnode.edits.dir /var/sxt/hadoop/ha/jn dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_dsa dfs.ha.automatic-failover.enabled true #### core-site.xml 注意:hadoop.tmp.dir的配置要变更:/var/sxt/hadoop-2.6/ha fs.defaultFS hdfs://mycluster ha.zookeeper.quorum node07:2181,node08:2181,node09:2181 客户端开发,保证core,hdfs-site.xml都被客户端加载 1,system:jdk,ssh 2,Hadoop:jdk ha: hdfs: 1,nameservice。。。。 2,jn 3,failover 4,auto 》 true core fs:nameservice zk: zookeeper start 3,jn 4,format,start,另一台:同步 5,formatZK 6,start-dfs.sh ## zookeeper配置 1,zookeeper(配置) conf/zoo.cfg dataDir=/var/sxt/zk server.1=node02:2888:3888 server.2=node03:2888:3888 server.3=node04:2888:3888 /var/sxt/zk echo 1 > myid //数字根据节点规划 配置文件:集群中要同步!!! zookeepr配置 启动zookeeper集群 zkServer.sh start || zkServer.sh status hadoop-daemon.sh start journalnode 第一台NN: hdfs namenode –format hadoop-deamon.sh start namenode 另一台NN: hdfs namenode -bootstrapStandby start-dfs.sh $ZOOKEEPER/bin/zkCli.sh ls / hdfs zkfc -formatZK stop-dfs.sh && start-dfs.sh || hadoop-daemon.sh start zkfceslipse配置hadoop
1,windows上部署hadoop包
部署包
源码包
lib整合
将老师给的bin目录下的文件覆盖到部署目录的bin目录下
hadoop.dll 放到 c:/windows/system32下
2,windows环境变量配置
hadoop的bin目录 HADOOP_HOME
HADOOP_USER_NAME
root
3,eclipse插件
安装插件
配置
Hadoop:MR语义
MapReduce:MapTask & ReduceTask

block > split
1:1
N:1
1:N
split > map
1:1
map > reduce
N:1
N:N
1:1
1:N
group(key)>partition
1:1
N:1
N:N
1:N? >违背了原语 partition > outputfile
计算框架MR(wordcount 单词统计)
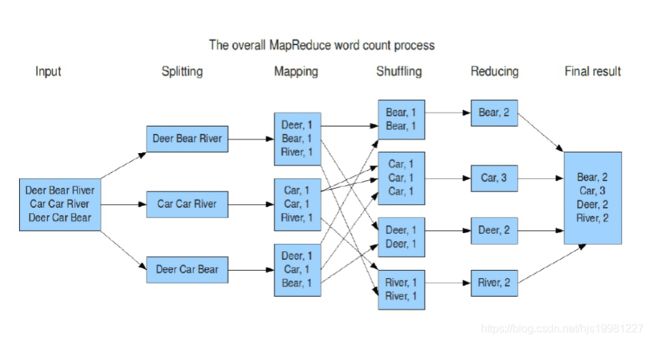
理解:
Map:
读懂数据
映射为KV模型
并行分布式
计算向数据移动
Reduce:
数据全量/分量加工(partition/group)
Reduce中可以包含不同的key
相同的Key汇聚到一个Reduce中
相同的Key调用一次reduce方法
排序实现key的汇聚
K,V使用自定义数据类型
作为参数传递,节省开发成本,提高程序自由度
Writable序列化:使能分布式程序数据交互
Comparable比较器:实现具体排序(字典序,数值序等)
MRv1角色:
JobTracker
核心,主,单点
调度所有的作业
监控整个集群的资源负载
TaskTracker
从,自身节点资源管理
和JobTracker心跳,汇报资源,获取Task
Client
作业为单位
规划作业计算分布
提交作业资源到HDFS
最终提交作业到JobTracker
弊端:
JobTracker:负载过重,单点故障
资源管理与计算调度强耦合,其他计算框架需要重复实现资源管理
不同框架对资源不能全局管理
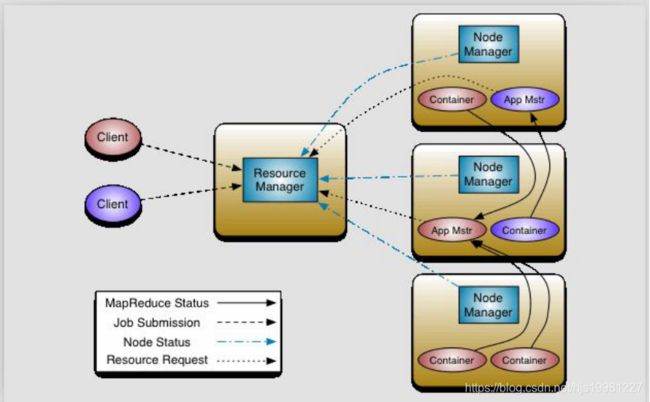
MRv2:On YARN
YARN:解耦资源与计算
ResourceManager
主,核心
集群节点资源管理
NodeManager
与RM汇报资源
管理Container生命周期
计算框架中的角色都以Container表示
Container:【节点NM,CPU,MEM,I/O大小,启动命令】
默认NodeManager启动线程监控Container大小,超出申请资源额度,kill
支持Linux内核的Cgroup
MR :
MR-ApplicationMaster-Container
作业为单位,避免单点故障,负载到不同的节点
创建Task需要和RM申请资源(Container /MR 1024MB)
Task-Container
Client:
RM-Client:请求资源创建AM
AM-Client:与AM交互
YARN
YARN:Yet Another Resource Negotiator;
Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;
核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
YARN的引入,使得多个计算框架可运行在一个集群中
每个应用程序对应一个ApplicationMaster
目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、Storm等
MapReduce On YARN
MapReduce On YARN:MRv2
将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的MRv1系统中
基本功能模块
YARN:负责资源管理和调度
MRAppMaster:负责任务切分、任务调度、任务监控和容错等
MapTask/ReduceTask:任务驱动引擎,与MRv1一致
每个MapRaduce作业对应一个MRAppMaster
MRAppMaster任务调度
YARN将资源分配给MRAppMaster
MRAppMaster进一步将资源分配给内部的任务
MRAppMaster容错
失败后,由YARN重新启动
任务失败后,MRAppMaster重新申请资源
Hadoop MapReduce V2,环境搭建&Examples
集群内运行MR程序
hadoop jar
分析过程:
准备CLASSPATH环境
运行Jar包中类的main方法:激活Client
mapred-site.xml配置
mapreduce.framework.name yarn #### yarn-site.xml配置 yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.ha.enabled true yarn.resourcemanager.cluster-id cluster1 yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 node08 yarn.resourcemanager.hostname.rm2 node09 yarn.resourcemanager.zk-address node07:2181,node08:2181,node09:2181 #### 访问 node04:8088 This is standby RM. Redirecting to the current active RM: http://node03:8088/学习过程
整体框架描述
搭建环境 & hadoop-mapreduce-examples-2.6.5.jar
MR设计理念
手动实现WordCount:粗粒度介绍计算框架
源码分析
天气案例:细粒度介绍计算框架
FOF案例:MR与数据模型
PageRank案例:
TFIDF案例:
ItemCF案例:
思路:
1,客户端干了什么
Job
2,框架干了什么
MapTask
ReduceTask
3,MR语义:
相同的key作为一组调用一次reduce
相同是由排序保证的
具体的比较方法实现产生不同的排序标准
Map:排序比较器的选取顺序:
1,取用户设置的排序比较器
2,取key自带的比较器
Reduce:RawComparator comparator = job.getOutputValueGroupingComparator();
1,取用户设置的分组比较器
2,取用户设置的排序比较器
3,取key自带的比较器
案例
MR-API:天气
1,MR
*保证原语
怎样划分数据,怎样定义一组
2,k:v映射的设计
考虑reduce的计算复杂度
3,能不能多个reduce
倾斜:抽样
集群资源情况
4,自定义数据类型
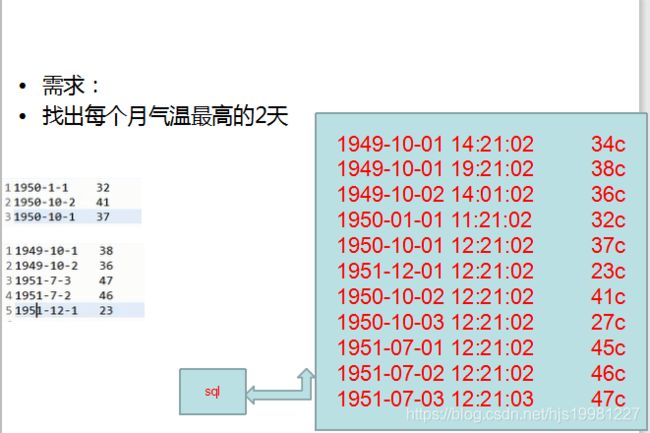
思路:
每年
每个月
最高
2天
1天多条记录?
进一部思考
年月分组
温度升序
key中要包含时间和温度呀!
MR原语:相同的key分到一组
通过GroupCompartor设置分组规则
自定义数据类型Weather
包含时间
包含温度
自定义排序比较规则
自定义分组比较
年月相同被视为相同的key
那么reduce迭代时,相同年月的记录有可能是同一天的
reduce中需要判断是否同一天
注意OOM
数据量很大
全量数据可以切分成最少按一个月份的数据量进行判断
这种业务场景可以设置多个reduce
通过实现partition