卷积神经网络(vgg16微调)基于pytorch
数据集下载
百度网盘:链接:https://pan.baidu.com/s/10Mjq7K7hHfPS322_w86gGg
提取码:3hqf
这是kaggle上面的一个数据集,有能力的同学也可以去原网址下载
效果
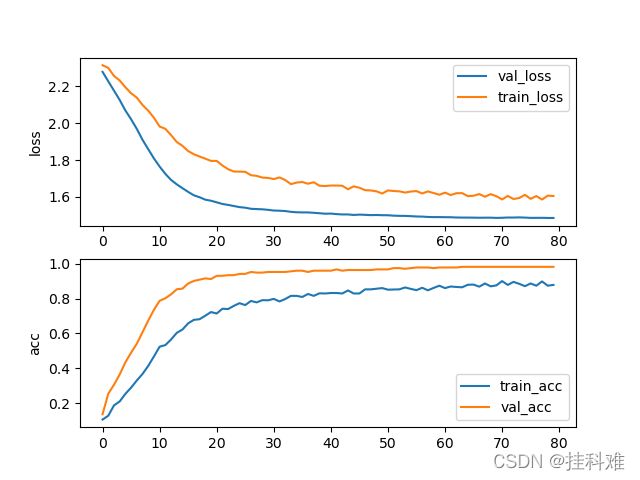
SGD:
其实在20轮左右的时候拟合效果就非常好了,没有必要训练80epoch,这里训练80主要是和Adam作比较。
Adam:
注意:下图loss算错了,所以看起来飘忽不定的,你们就当不存在(写成最后一批的loss了,应该写一轮的)

代码
注意:
1,大部分代码源自《Pytorch深度学习入门与实践一书》,但并未跑出与书本一致的结果,因而修改了部分网络结构与参数,得到了较为理想的模型
train.py
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
import scipy.io as scio
import torch
import torch.nn as nn
from torch.optim import SGD, Adam
import hiddenlayer as hl
import torch.utils.data as Data
from torchvision import models
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import ImageFolder
vgg16 = models.vgg16(pretrained=True)
vgg = vgg16.features #vgg仅有卷积和池化
for param in vgg.parameters():
param.requires_grad_(False)
class MyVggModel(nn.Module):
def __init__(self):
super(MyVggModel, self).__init__()
self.vgg = vgg
self.classifier = nn.Sequential(
nn.Linear(25088, 512),
nn.Tanh(),
nn.Dropout(p=0.3),
nn.Linear(512, 256),
nn.Tanh(),
nn.Dropout(p=0.3),
nn.Linear(256, 10),
nn.Softmax(dim=1)
)
def forward(self, x):
x = self.vgg(x)
x = x.view(x.size(0), -1)
output = self.classifier(x)
return output
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
tanh_gain = nn.init.calculate_gain('tanh')
nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)
# nn.init.kaiming_normal_(m.weight.data)
Myvggc = MyVggModel()
#print(Myvggc)
Myvggc.initialize()
train_data_transforms = transforms.Compose([
transforms.RandomResizedCrop(224), #224
transforms.RandomHorizontalFlip(),# 默认概率0.5
transforms.ToTensor(),
#图像标准化处理
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_data_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
#图像标准化处理
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_data_dir = r"/home/你的路径/training"
train_data = ImageFolder(train_data_dir, transform=train_data_transforms)
#ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字
train_data_loader = Data.DataLoader(
train_data,
batch_size=32,
shuffle=True,
num_workers=4,
)
val_data_dir = r'/home/你的路径/validation'
val_data = ImageFolder(val_data_dir, transform=val_data_transforms)
val_data_loader = Data.DataLoader(val_data, batch_size=32, shuffle=True,num_workers=4)
print("训练集样本:", len(train_data.targets))
print("测试集样本:", len(val_data.targets))
'''#获得一个batch的图像
for step, (b_x,b_y) in enumerate(train_data_loader):
if step > 0:
break
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
plt.figure(figsize=(12, 6))
for ii in np.arange(len(b_y)):
image = b_x[ii,:,:,:].numpy().transpose((1,2,0))
image = std * image + mean
image = np.clip(image, 0, 1)
plt.imshow(image)
plt.title(b_y[ii].data.numpy())
plt.axis("off")
plt.show()
plt.subplots_adjust(hspace=0.3)
'''
optimizer = torch.optim.SGD(Myvggc.parameters(), lr=0.003)
loss_func = nn.CrossEntropyLoss() #交叉熵损失函数,有点难,
train_loss = []
train_c = []
val_loss = []
val_c = []
for epoch in range(25):
train_loss_epoch = 0
val_loss_epoch = 0
train_corrects = 0
val_correct = 0
Myvggc.train()
for step, (b_x,b_y) in enumerate(train_data_loader):
# print('training in program:', (len(b_x)*(step+1)) / (len(train_data.targets)))
output = Myvggc(b_x)
# print('output:',output)
loss = loss_func(output, b_y)
# print('loss:',loss.item())
pre_lab = torch.argmax(output, 1)
print('b_y:',b_y)
print('pre_:',pre_lab)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_epoch += loss.item() * b_x.size(0)
train_corrects += torch.sum(pre_lab == b_y)
print('**'*10,'已完成', epoch+1,'轮')
train_loss.append(train_loss_epoch /len(train_data.targets) )
train_c.append(train_corrects.double() / len(train_data.targets))
print('train_loss:',train_loss)
print('train_accurary:',train_c)
Myvggc.eval()
for step, (val_x, val_y) in enumerate(val_data_loader):
output = Myvggc(val_x)
loss = loss_func(output, val_y)
pre_lab = torch.argmax(output, 1)
val_loss_epoch += loss.item() * val_x.size(0)
val_correct += torch.sum(pre_lab == val_y)
val_loss.append(val_loss_epoch/ len(val_data.targets))
val_c.append(val_correct / len(val_data.targets))
print("val_loss:",val_loss)
print("val_accurary:",val_c)
torch.save(Myvggc,'vgg16_monky.pkl',_use_new_zipfile_serialization=False)
scio.savemat('val_loss.mat',{
'val_loss':val_loss})
scio.savemat('val_c.mat',{
'val_c':val_c})
scio.savemat('train_loss.mat',{
'train_loss':train_loss})
scio.savemat('train_c.mat',{
'train_c':train_c})
可视化:
import scipy.io as scio
import numpy as np
import matplotlib.pyplot as plt
val_loss = scio.loadmat('val_loss.mat')
val_acc = scio.loadmat('val_c.mat')
train_loss = scio.loadmat('train_loss.mat')
train_acc = scio.loadmat('train_c.mat')
val_loss = val_loss['val_loss']
val_acc = val_acc['val_c']
train_loss = train_loss['train_loss']
train_acc = train_acc['train_c']
plt.subplot(2,1,1)
plt.plot(val_loss[0], label='val_loss')
plt.plot(train_loss[0],label='train_loss')
plt.legend()
plt.ylabel('loss')
plt.subplot(2,1,2)
plt.plot(train_acc[0], label='train_acc')
plt.plot(val_acc[0], label='val_acc')
plt.legend()
plt.ylabel('acc')
plt.savefig('vgg16(80_epoch).png')
plt.show()
修改内容,
1,有大量特征是负数,使用nn.ReLU()激活函数会出现大量的0,导致下层神经元直接摆烂,无论输入什么全都预测一个类(只激活一个神经元)。因此选择了nn.Tanh(),如果你想问LeakReLU,PReLU,RReLU行不行呢?恭喜你,不行。我们输入到网络中的数据是归一化后的,本来负数就多,LeakReLU,PReLU,RReLU,都是给负数乘上一个小于1的数,特征就会更小,再到下一层更小了,再到下一层,基本就为0了,结果和ReLU都是一样的。(这里卡了我好几天)
2,初始化从随机该为xvaier初始化,便于模型拟合