(pytorch-深度学习系列)pytorch卷积层与池化层输出的尺寸的计算公式详解
pytorch卷积层与池化层输出的尺寸的计算公式详解
注:这篇blog写的不够完善,在后面的CNN网络分析padding和stride详细讲了公式,感兴趣的可以移步这里:卷积神经网络中的填充(padding)和步幅(stride)
要设计卷积神经网络的结构,必须匹配层与层之间的输入与输出的尺寸,这就需要较好的计算输出尺寸
先列出公式:
卷积后,池化后尺寸计算公式:
(图像尺寸-卷积核尺寸 + 2*填充值)/步长+1
(图像尺寸-池化窗尺寸 + 2*填充值)/步长+1
即:
卷积神将网络的计算公式为:
N=(W-F+2P)/S+1
其中
N:输出大小
W:输入大小
F:卷积核大小
P:填充值的大小
S:步长大小
例Conv2d(后面给出实例来讲解计算方法):
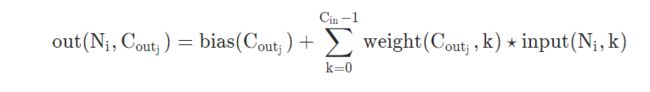
`

class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
卷积一层的几个参数:
in_channels=3:表示的是输入的通道数,RGB型的通道数是3.
out_channels:表示的是输出的通道数,设定输出通道数(这个是可以根据自己的需要来设置的)
kernel_size=12:表示卷积核的大小是12x12的,也就是上面的 F=12
stride=4:表示的是步长为4,也就是上面的S=4
padding=2:表示的是填充值的大小为2,也就是上面的P=2
实例:
cove1d:用于文本数据,只对宽度进行卷积,对高度不进行卷积
cove2d:用于图像数据,对宽度和高度都进行卷积
import torch
from torch.autograd import Variable
#torch.autograd提供了类和函数用来对任意标量函数进行求导。
import torch.nn as nn
import torch.nn.functional as F
class MNISTConvNet(nn.Module):
def __init__(self):
super(MNISTConvNet, self).__init__()
'''
这是对继承自父类的属性进行初始化。而且是用父类的初始化方法来初始化继承的属性。
也就是说,子类继承了父类的所有属性和方法,父类属性自然会用父类方法来进行初始化。
'''
#定义网络结构
self.conv1 = nn.Conv2d(1, 10, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(10, 20, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, input):
x = self.pool1(F.relu(self.conv1(input)))
x = self.pool2(F.relu(self.conv2(x))).view(320)
x = self.fc2(self.fc1(x))
return x
net = MNISTConvNet()
print(net)
input = Variable(torch.randn(1, 1, 28, 28))
out = net(input)
print(out.size())
我们在这个实例中抽出网络结构部分:
self.conv1 = nn.Conv2d(1, 10, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(10, 20, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, input):
x = self.pool1(F.relu(self.conv1(input)))
x = self.pool2(F.relu(self.conv2(x))).view(320)
x = self.fc2(self.fc1(x))
网络结构为:
conv2d--maxpool2d--conv2d--maxpool2d--fullyconnect--fullyconnect
输入图片大小为:input = Variable(torch.randn(1, 1, 28, 28))
即28*28的单通道图片,即:1*28*28
接下来,我们分层解析每一层网络的输入和输出:
(1)conv2d(1,10,5)
N:输出大小
W:输入大小 28*28
F:卷积核大小 5*5
P:填充值的大小 0默认值
S:步长大小 1默认值
N=(W-F+2P)/S+1=(28-5 + 2*0)/1 + 1 = 24
输出为:10*24*24
Conv2d(输入通道数, 输出通道数, kernel_size(长和宽)),当卷积核为方形时,只写一个就可以,卷积核不是方形时,长和宽都要写,如下:
self.conv1 = nn.Conv2d(2, 4, (5,2))
(2)MaxPool2d(2, 2)
MaxPool 最大池化层,池化层在卷积神经网络中的作用在于特征融合和降维。池化也是一种类似的卷积操作,只是池化层的所有参数都是超参数,是学习不到的。maxpooling有局部不变性而且可以提取显著特征的同时降低模型的参数,从而降低模型的过拟合。只提取了显著特征,而舍弃了不显著的信息,是的模型的参数减少了,从而一定程度上可以缓解过拟合的产生。
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
N:输出大小
W:输入大小 24*24
F:卷积核大小 5*5
P:填充值的大小 0默认值
S:步长大小 1默认值
N=(W-F+2P)/S+1=(24-2 + 2*0)/2 + 1 = 12
输出为:10*12*12
(3)conv2d(10,20,5)
N:输出大小
W:输入大小 12*12
F:卷积核大小 5*5
P:填充值的大小 0默认值
S:步长大小 1默认值
N=(W-F+2P)/S+1=(12-5 + 2*0)/1 + 1 = 8
输出为:20*8*8
(4)MaxPool2d(2, 2)
N:输出大小
W:输入大小 8*8
F:卷积核大小 5*5
P:填充值的大小 0默认值
S:步长大小 1默认值
N=(W-F+2P)/S+1=(8-2 + 2*0)/2 + 1 = 4
输出为:20*4*4
(5)fully-connect Linear(320, 50)
输入:20*4*4=320
输出:50
(6)fully-connect Linear(50, 10)
输入:50
输出:10
所以,整个实例的训练过程数据流动为:
def forward(self, input):
x = self.pool1(F.relu(self.conv1(input)))
x = self.pool2(F.relu(self.conv2(x))).view(320)
x = self.fc2(self.fc1(x))
激活函数Relu,在神经网络中的作用是:通过加权的输入进行非线性组合产生非线性决策边界
简单的来说就是增加非线性作用。
在深层卷积神经网络中使用激活函数同样也是增加非线性,主要是为了解决sigmoid函数带来的梯度消失问题。