基于Pytorch的MLP(以垃圾邮件分类为例)
本文是《Pytorch深度学习入门与实战》,中国水利水电出版社一书中的例子
数据集:
链接:https://pan.baidu.com/s/1rODLa65Js4K5rZ1iMDQ2DA
提取码:d8fc
箱线图:

特征还是比较明显的
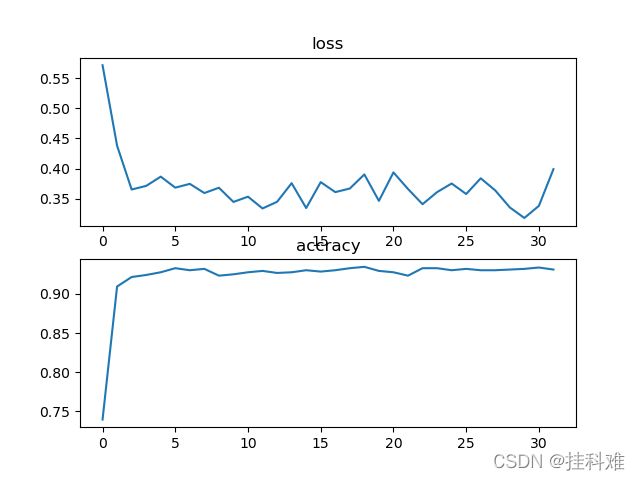
训练效果:
代码
全连接神经网络(Multi-Layer Perception,MLP)或称多层感知机。以下实现了对垃圾邮件的分类
训练代码:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import torch
import torch.nn as nn
from torch.optim import SGD, Adam
import torch.utils.data as Data
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
filename = "G:\data\spambase.csv" # 读取文件位置
spam = pd.read_csv(filename) # (4600,58) 4600个样本,每个样本有58个特征
# print(spam.head())
X = spam.iloc[:, 0:57].values # 去掉最后一列标签列
y = spam.spam.values
# 数据归一化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=123) # 将数据分为训练集和测试集
scales = MinMaxScaler(feature_range=(0, 1)) # 将数据缩放到0,1
X_train_s = scales.fit_transform(X_train) # 对X_train_s 缩放,下同
X_test_s = scales.transform(X_test) #
# 使用箱线图对比邮件的每个特征分布
# colname = spam.columns.values[:-1]
# plt.figure(figsize=(20, 14))
# for ii in range(len(colname)):
# plt.subplot(7, 9, ii+1)
# sns.boxplot(x=y_train, y=X_train[:,ii])
# plt.title(colname[ii])
# plt.subplots_adjust(hspace=0.4)
# plt.show()
# 搭建MLP网络
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica, self).__init__() #构造方法必须有
# Sequential()表示将括号里的层链接起来,下面nn.Linear表示输入有57个神经元,输出有30个神经元,存在偏置神经元(默认开启)
# 然后将输出结果带入ReLu函数,Linear与Relu合在一起起名为hidden1,上层的输出为下层的输入
self.hidden1 = nn.Sequential(
nn.Linear(
in_features=57,
out_features=30,
bias=True,
),
nn.ReLU()
)
self.hidden2 = nn.Sequential(
nn.Linear(30, 10),
nn.ReLU()
)
self.classifica = nn.Sequential(
nn.Linear(10, 2),
nn.Sigmoid()
)
def forward(self, x): # 定义前向传播函数
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
return fc1, fc2, output
# 数据转为张量
X_train_t = torch.from_numpy(X_train_s.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.int64))
X_test_t = torch.from_numpy(X_test_s.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.int64))
train_data = Data.TensorDataset(X_train_t, y_train_t)
# 定义一个数据加载器,会将数据分批次喂给神经网络,这里定义的一批为64个样本
train_loader = Data.DataLoader(
dataset=train_data, # 数据是什么
batch_size=64, # 每批多少个
shuffle=True, # 是否打乱数据
#num_workers=2
)
# 我们的网络结构是个类,将其实例化一下
mlpc = MLPclassifica()
# 定义优化器,使用Adam优化算法,可自动调节学习率
optimizer = torch.optim.Adam(mlpc.parameters(), lr=0.01)
loss_func = nn.CrossEntropyLoss() # 定义损失函数为二分类损失函数
max_epoch = 15 # 训练轮次
train_loss_list = [] # 定义一个空列表,等下来存储训练的损失
accuracy_list = [] #同上,来存储精度
for epoch in range(max_epoch):
for step,(b_x,b_y) in enumerate(train_loader):
_, _, output = mlpc(b_x) # 将b_x喂给神经网络,得到输出
train_loss = loss_func(output, b_y) # 根据输出计算损失函数
optimizer.zero_grad() # torch中每次求导梯度会叠加,所以我们在反向传播的过程中先将梯度清零再求导
train_loss.backward() # 求导
optimizer.step() # 更新参数
niter = epoch * len(train_loader)+step+1
if niter % 25 == 0:
train_loss_list.append(train_loss.detach().numpy()) # 每经过25次迭代记录一次损失值
_, _, output = mlpc(X_test_t)
_, pre_index = torch.max(output, 1)
test_accuracy = accuracy_score(y_test, pre_index) # 计算精度
accuracy_list.append(test_accuracy)
plt.subplot(2,1,1) #画loss
plt.plot(train_loss_list)
plt.title('loss')
plt.subplot(2,1,2) #画精度表
plt.title('accracy')
plt.plot(accuracy_list)
plt.show()
torch.save(mlpc, "spam_model.pkl") #保存模型的网络结构与参数
#torch.save(mlpc.state_dict(), "spam_state_dict.pkl") # 仅保存所有的参数
分类代码:
import torch
import torch.nn as nn
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.metrics import accuracy_score
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica, self).__init__()
self.hidden1 = nn.Sequential(
nn.Linear(
in_features=57,
out_features=30,
bias=True,
),
nn.ReLU()
)
self.hidden2 = nn.Sequential(
nn.Linear(30, 10),
nn.ReLU()
)
self.classifica = nn.Sequential(
nn.Linear(10,2),
nn.Sigmoid()
)
def forward(self, x):
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
return fc1, fc2, output
filename = "G:\data\spambase.csv"
mlpc = torch.load('spam_model.pkl') # 保存下来的模型和参数不能在没有类定义时直接使用
spam = pd.read_csv(filename) # 直接拿全部数据集进行验证
X = spam.iloc[:, 0:57].values
y = spam.spam.values
scales = MinMaxScaler(feature_range=(0, 1))
X = scales.fit_transform(X)
X = torch.from_numpy(X.astype(np.float32))
y = torch.from_numpy(y.astype(np.int64))
_, _, output = mlpc(X)
_, pre_index = torch.max(output, 1)
accuracy = accuracy_score(y, pre_index)
print(accuracy)
关于改进:
1,由于使用了Relu激活函数,可考虑使用kaiming初始化,保证每一层的数据方差都在一个合理的范围。在我们的网络类中添加方法。
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight.data)
kaiming初始化的本质为:
nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
2,nn.Dropout防止过拟合
随机失活,例如nn.Dropout(p=0.5)表示这一层神经元有50%的概率失活。(不更新参数)
注意一点:假设我让p=0.9,那只有10%的神经元有输出,那我们最后神经元的输出大概也在原维度的10%左右(比如我有10个神经元,与输入相乘再相加之后的值大约在100能够激活神经元,但是我dropout以后只有1个神经元有输出,与输入相乘在相加的值在10左右,肯定不能激活神经元,如果更新梯度使其能够激活显然是不合理的)所有我们要在最后的输出上除(1-p),来保持和dropout之前一样的尺度(数量级)大小。torch中会自动帮你弄好。
使用:加在激活函数后
class Mymodel(nn.module):
def __init__(delf):
super(Mymodel,self).__init__()
self.classifier = nn.Sequtial(
nn.linear(255,100),
nn.Relu(),
nn.Dropout(p=0.5),
........)