

为了让数据挖掘和数据查询能够更加普世化,惠及更多的想使用数据的但缺乏SQL能力的一般数据消费者,各类数据可视化工具应运而生,像Amazon Quicksight就是这样一款产品。目前亚马逊云科技中国区Amazon Quicksight还没有上线,开源界也有不少好用的可视化项目,Apache Superset就是其中之一。
本篇推送会带您一步一步地在亚马逊云科技上部署Apache Superset并在Superset上创建一个展示新冠肺炎情况的Dashboard(示例如下)。新冠肺炎数据存储于Amazon S3上并通过Amazon Athena来直接查询。
Apache Superset基本功能:
- 支持多种图表类型和数据源类型
- 支持通过可视化的方式进行数据探索并一键生成展示看板,并提供数据下载功能
- 支持报表分享和复杂的权限管理
- 支持直接写SQL构建基于原始数据的逻辑虚拟层

准备好我们就开始吧,
以下步骤基于亚马逊云科技宁夏区域!
步骤1 使用docker部署Apache Superset
本步骤阐述了如何在Amazon Linux环境中部署Superset,并且在宁夏区域已经准备好了一个公用的Superset AMI环境。这个AMI中包含了所有下述步骤创建的Superset报表和所需数据,如果直接使用此AMI的话可以跳过步骤1,AMI 名字 为Amazon-Demo-Superset-Covid19,可以在宁夏区Amazon EC2 公有映像中找到。登录的用户名密码默认都是admin,默认的Web端口是8088。
注意:此AMI仅供本博客教学演示使用,非官方认证AMI请勿直接用于生产环境。
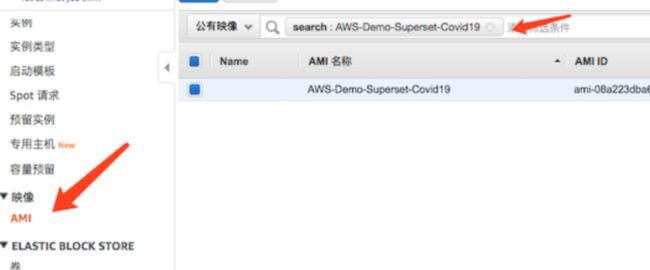
1.1 启动一台Amazon Linux EC2并安装启动docker环境,需要机型为t.xlarge及以上,EBS盘20GB以上。
sudo yum update -y
# install python3 gcc
sudo yum install -y python3 libpq-dev python3-dev
sudo yum install -y gcc gcc-c++
# add following into ~/.bashrc
echo "export PATH=/usr/local/bin:$PATH" >> ~/.bashrc
echo "alias python=python3" >> ~/.bashrc
echo "alias pip=pip3" >> ~/.bashrc
source ~/.bashrc
python --version
# install docker
sudo yum -y install docker
sudo usermod -a -G docker ec2-user
sudo systemctl start docker
sudo systemctl status docker
sudo systemctl enable docker
sudo chmod 666 /var/run/docker.sock
docker ps
# install docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
docker-compose --version1.2 下载Superset Docker文件
sudo yum install -y git curl
git clone https://github.com/apache/incubator-superset/1.3 修改Dockerfile安装PyAthena插件以支持Athena数据源
`cd incubator-superset
vi Dockerfile`
加入连接Athena需要的依赖
RUN pip install PyAthenaJDBC \
&& pip install PyAthena \
&& pip install psycopg2重新build和启动Superset
`docker-compose build
docker-compose up`
需要配置管理员用户权限,在docker/docker-init.sh中默认创建用户admin(密码也是admin)但权限并没有更新,通过以下命令更新权限
docker-compose exec superset bash
superset init1.4 配置成功后,Superset默认使用8088端口,使用http://

1.5 本实验使用本地存储来保存用户名和密码,如需要配置外部的数据库用来存储登录数据Docker的配置请参考GitHub文档 。
https://github.com/amancevice...
另外Superset也支持LDAP或者OpenID登录,配置文件
https://github.com/apache/sup...
步骤 2 配置新冠数据实时数据源
本实验中的数据来源于约翰霍普金斯大学的实时更新的开放数据集。此S3存储桶在海外账户,如果海外账号可以参照博客,但如果国内区域的话需要同步到国内的S3桶中使用。
2.1 同步海外S3的数据源到宁夏S3
Option 1:可以使用同步工具设置源桶和目标桶来同步数据
https://github.com/aws-sample...
需要同步的S3路径为s3://covid19-lake/enigma-jhu/,每个文件夹里面有json和csv两种类型的数据,选择其一即可。此数据缺乏省市名字到ISO3166-2代码映射表,Superset中的城市地图需要用到。需要使用AMI (Amazon-Demo-Superset-Covid19)中的province_code_mapping数据。
Option 2: 2020-04-22号的静态数据存储在机器AMI(Amazon-Demo-Superset-Covid19)的/home/ec2-user/data/ 可使用以下命令上传到位于宁夏的S3桶中
aws s3 cp /home/ec2-user/data/ s3://<宁夏S3桶名字>/ --recursive2.2 Amazon Glue爬取S3数据生成Athena 表
配置一个Glue的爬网程序,指定宁夏S3桶数据的根目录(包含两张表的数据,爬虫会自动分表),并配置表前缀为covid19_ 数据库为covid19。具体操作参照官方文档。
https://docs.aws.amazon.com/z...

2.3 原始数据存在一些重复值和需要丰富的部分,可以使用Amazon Athena创建view来简单处理。如果想要把处理的结果持久化还是推荐使用Amazon Glue来做定时的ETL。创建语句如下:
CREATE OR REPLACE VIEW "daily_region_stats" AS
SELECT date_trunc('day', CAST(date_parse(last_update, '%Y-%m-%dT%T') AS TIMESTAMP)) AS day,
combined_key as region,province_state,country_region, max(confirmed) as confirmed ,max(deaths) as deaths,max(recovered) as recovered
FROM "covid19"."covid19_enigma_jhu"
group by date_trunc('day', CAST(date_parse(last_update, '%Y-%m-%dT%T') AS TIMESTAMP)),
combined_key,province_state,country_region
CREATE OR REPLACE VIEW region_stats_snapshot AS
WITH
src AS (
SELECT
"province_state"
, "combined_key"
, (CASE "country_region" WHEN 'US' THEN 'United States' ELSE "country_region" END) "country_region"
, "max"("confirmed") "confirmed"
, "max"("deaths") "deaths"
, "max"("recovered") "recovered"
FROM
covid19.covid19_enigma_jhu
GROUP BY "province_state", "country_region", "combined_key"
)
SELECT
src.*
, "iso_code"
FROM
(src
LEFT JOIN covid19_province_code_mapping USING (province_state))
步骤 3 SUPERSET配置ATHENA数据源并创建DASHBOARD
如果使用AMI(Amazon-Demo-Superset-Covid19),图表和Dashboard已经配好,只需要修改步骤3.1中数据库连接中的S3_staging_dir为自己的S3地址即可,另外EC2的IAM角色需要有相应权限。以下步骤仅展示Superset的基本功能,如果想要深入了解细节操作请参照Superset官网。
https://superset.apache.org/d...
3.1 Superset中可以指定不同的数据源,通过 Sources-> Databases添加Athena为数据源。
部署Superset的EC2附加的IAM角色需要有 Athena查询和Glue Catalog的权限,为方便起见可以赋予AthenaFullAccess和GlueFullAccess。但实际情况请按照最小权限原则来保障安全。

Athena连接URL:
awsathena+rest://@athena.cn-northwest-1.amazonaws.com.cn/default?s3_staging_dir=<用来存储查询结果的S3地址>

3.2 要使用表前需要先在Superset中定义表及聚合指标,通过Sources->Tables添加新表(绿色+图标),并设置好需要的聚合指标(Metrics)
修改表中Metrics,Verbose Name是想要显示的指标名字,范例可参照AMI中已有的表格
![]()

3.3 Charts是Superset中的做图功能,可以绘制单一图表并有不同的图表选择。通过选择选择不同的聚合方式生成图表。在表列中点击表名字即可进入如下做图编辑页面。

点击Run Query后会应用所选的值形成SQL查询,并且生成的SQL查询语句和相应的返回结果都可以在线查看

3.4 保存相应的Charts时候可以选择把Charts加入Dashboard。如果使用AMI部署,Dashboard中可以找到已建好的文首所述的新冠肺炎情况看板。

3.5 除了使用Charts的方式编辑查询数据,Superset还为熟悉SQL的用户准备了SQL Lab功能。和Athena类似,此处可以直接查询数据源中的数据。

总结
除了Athena数据源,Superset还支持各种各样的JDBC连接数据库甚至Apache Druid,支持的数据源种类详见官网。现在我们完成了一个简单的新冠肺炎情况看板,此看板还可以添加更多的指标和展示方式比如添加每日新增的趋势,top死亡率列表等等。更多的功能和完善方式等着你来探索!
本篇作者

贺浏璐
亚马逊云科技解决方案架构师
负责亚马逊云科技云计算方案的咨询和架构设计,同时致力于大数据方面的研究和应用。

梁睿
亚马逊云科技解决方案架构师
主要负责企业级客户的上云工作,服务客户涵盖从汽车,传统生产制造,金融,酒店,航空,旅游等,擅长DevOps领域。11 年 IT 专业服务经验,历任程序开发,软件架构师、解决方案架构师。