Kaggle 决定将他们每月的表格竞赛延续到 2022 年这对于我们来说是非常好的消息。并且也Kaggle 表示他们已经考虑大家的评论,所以我希望这意味着他们将不再使用庞大到使系统崩溃的数据集,这次1月的比赛数据集就不是很大。
在我看来,2022 年 1 月的竞赛问题是对涵盖几年时间的销售额的预测,这可以用机器学习构成一个时间序列。
我在下面的屏幕截图中包含了问题陈述的一部分,其中包含了和这项竞赛问题有关的代码

本篇文章我使用 HistGradientBoostingRegressor 进行测试。
首先要导入运行程序需要的库,numpy,Pandas,matplotlib 和 seaborn:-
然后我使用 Pandas 读取csv 并将它们转换为df

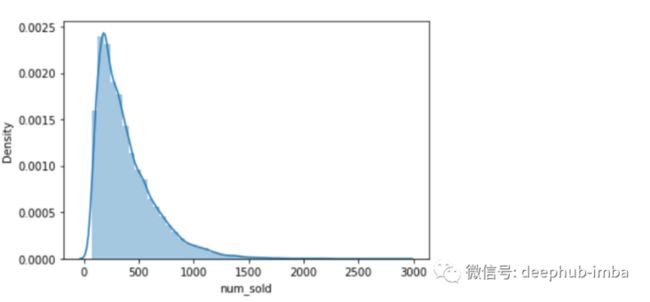
我使用 seaborn 来分析目标,[‘num_sold’]是我们需要预测销售额。当我分析它时,可以看到它是偏斜的,并且有一些异常值:-
然后我决定删除异常值,希望这样预测会有所改善。下面屏幕截图中的代码是我用来删除异常值的代码。虽然在这篇文章中没有记录,但我后来将乘数改为 2.25 而不是 1.5,并发现预测有小幅改进:-

将异常值转换为空值后,我查看了这些空值并且进行了删除:-
我创建了变量 target,它将用于进行预测。
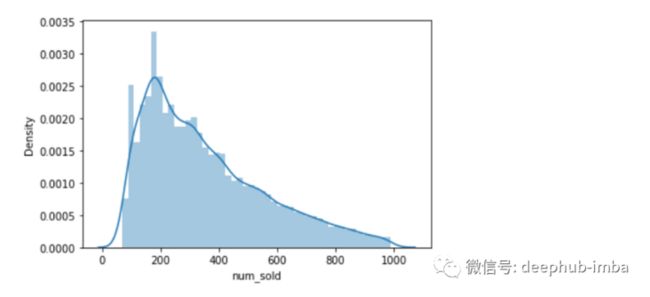
我再次分析了目标,一旦删除了异常值,数据列的形状就大大改善了:-
我创建了一个新的df,这个df包含了train和test的数据:-

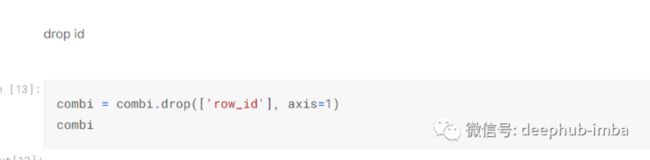
除此以外,我还删除了 id_row 因为它不是必需的:-
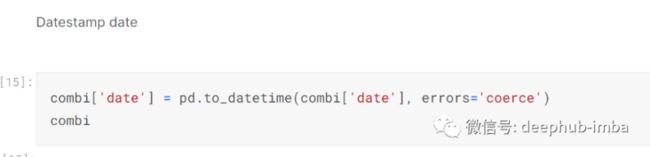
然后使用pandas处理时间特征:-
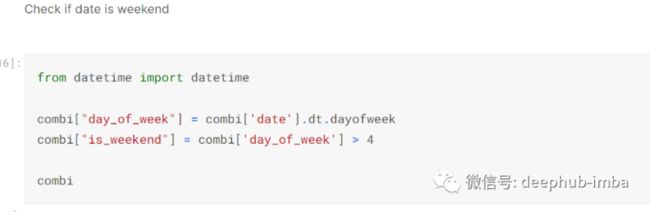
日期列转换成时间戳后,我创建了一个新列 [‘day_of_week’] 并使用 datetime 来确定这一天属于一周中的哪一天。
然后我创建了另一列。['Is_weekend'] 确定当天是否在周末:-
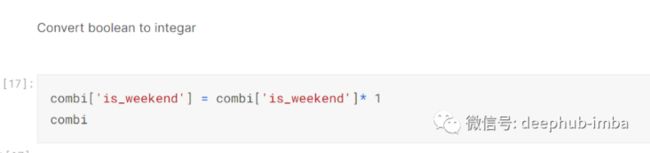
然后我将列 [‘is_weekend’] 乘以 1 将其转换为整数:-
我使用 datetime 库创建了三个新列,[‘year’]、[‘month’] 和 [‘day’]:-
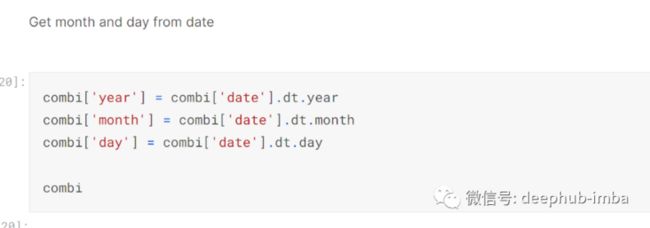
一旦确定了年月日,我就可以检查哪些天是假期。我做的第一件事是确定这一天是否落在 12 月 25 日,并将这些数据放入布尔列 [‘xmas1’],然后将其转换为整数:-
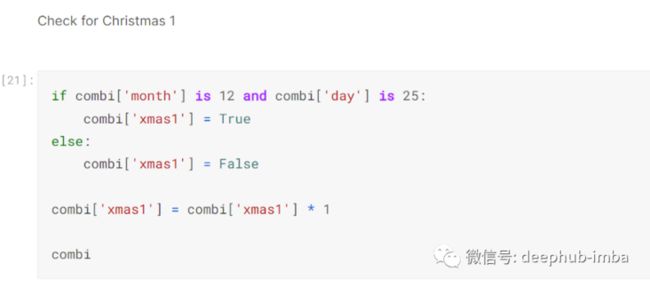
然后我按照上面使用的相同格式查看相关日期是否为 12 月 26 日,并将该信息放入新创建的列 [‘xmas2’]。
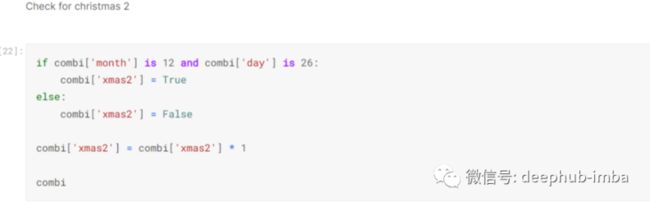
我还检查了一天是否在新年并将此信息放在创建的列中,[‘new_year’]:-
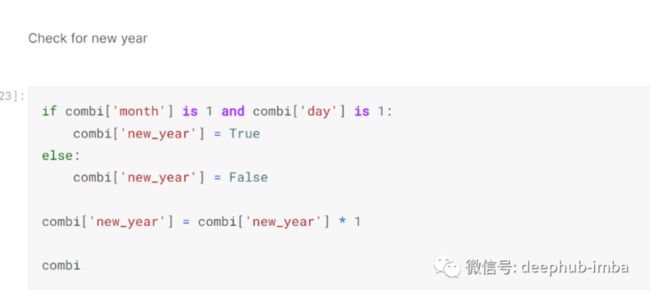
找出一天是否是复活节有点棘手,因为复活节并不是固定的日期:-
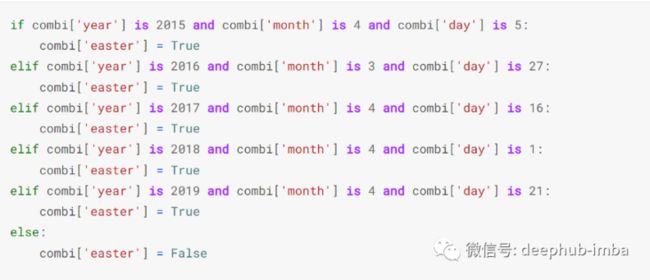
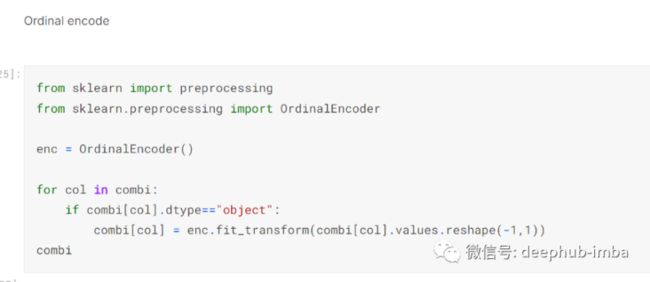
一旦假期被放在适当的列中,我使用 sklearn 并创建了一个 for 循环来对所有属于 dtype 对象的列进行顺序编码:-
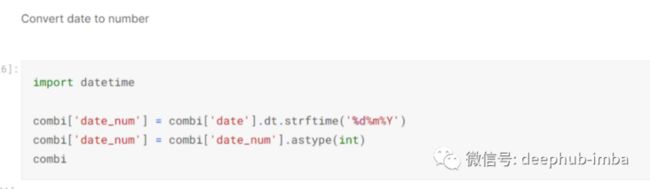
然后我使用 datetime 将日期转换为新创建的列 [‘date_num’] 中的数字,然后将此数字转换为整数:-
然后我删除了 [‘date’] 和 [‘year’] 列,因为它们在进行预测时不会提供任何有价值的信息:-

下面定义 X、y 和 X_test 变量。y 变量是目标,X 变量由combi 到train 的长度组成,X_test 变量由combi 从train 的长度到末尾组成:-

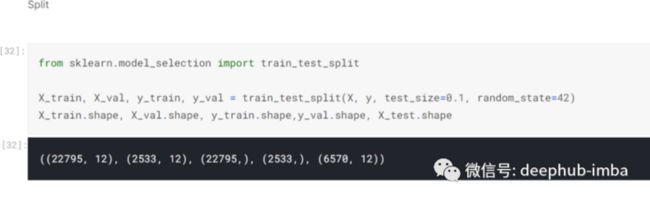
然后我使用 sklearn 的 train_test_split 将 X 和 y 变量分成训练和验证集:-
然后我定义了模型,在这个例子中我决定使用 sklearn 的 HistGradientBoostingRegressor。(只使用了默认值,但如果我也使用了 grid_search_cv,我的分数可能会更高。)
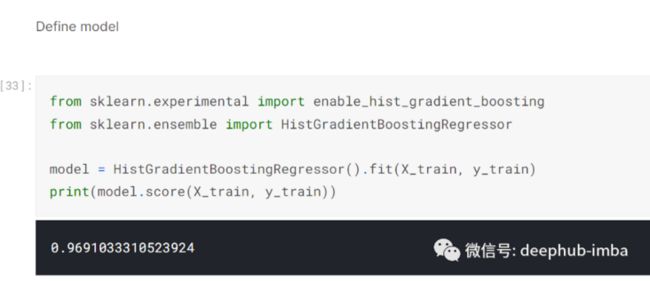
然后我在验证集上预测:-
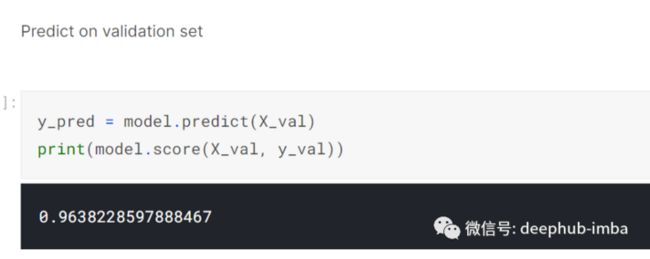
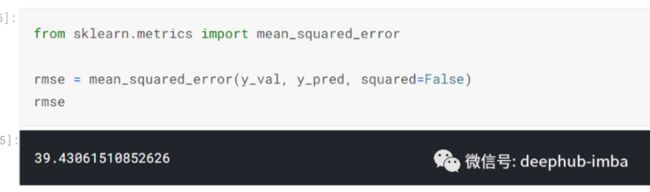
我检查了指标。理想情况下,分数应尽可能低:-
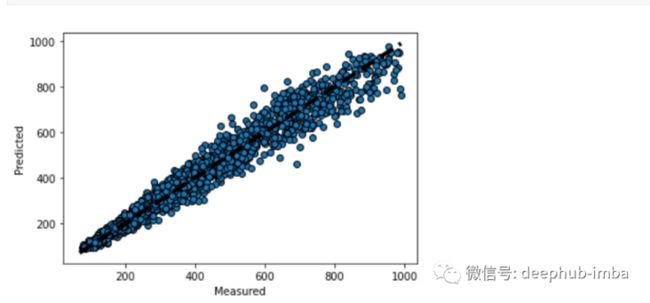
我使用 matplotlib 绘制预测值与真实值的关系图:-
然后我在测试集上预测:-
一旦我对测试集进行了预测,我就可以提交的数据了:-
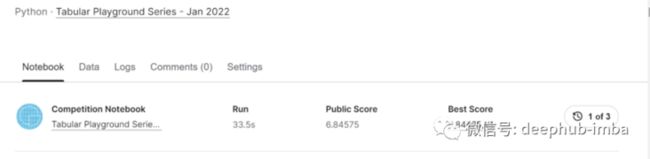
我取得的分数,可以从下面的屏幕截图中看出:-
总而言之,我只是在一天内完成了这个竞赛问题的程序,但是我可以做一些事情来提高我的分数,例如更改我用来删除异常值的公式以及使用 GridSearchCV 来确定要使用的最佳参数。我还可以加入更多节日。
我不得不说,很高兴使用不会使我的计算机崩溃的较小数据集。
这篇文章的代码链接在这里:https://www.overfit.cn/post/1...
本文作者:Tracyrenee
程宏 译