本文章转自:优极限
文章主要讲解:Zookeeper
获取更多Java资料请百度搜索:优极限官网

数据存储历史背景
- 所有的的计算任务都由一台计算机完成,数据的存储也由一台计算机完成
单节点计算
- 单点故障
性能瓶颈
- IO的瓶颈
- 内存
磁盘阵列
Raid简介
- Redundant Arrays of Independent Disks
- 将数据存放在多块磁盘肯定能解决IO瓶颈的问题
磁盘阵列是由很多块独立的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。 磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任意一个硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中。
条带化
问题
- 大多数磁盘系统都对访问次数(每秒的 I/O 操作,IOPS)和数据传输率(每秒传输的数据量,TPS)有限制。
- 当达到这些限制时,后面需要访问磁盘的进程就需要等待,这时就是所谓的磁盘冲突。
解决方案
- 条带化技术就是将一块连续的数据分成很多小部分并把他们分别存储到不同磁盘上去。
- 这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突
- 在对这种数据进行顺序访问的时候可以获得最大程度上的 I/O 并行能力,从而获得非常好的性能。

Raid0
- RAID0 具有低成本、高读写性能、 100% 的高存储空间利用率等优点,但是它不提供数据冗余保护,一旦数据损坏,将无法恢复。
- RAID0 一般适用于对性能要求严格但对数据安全性和可靠性不高的应用,如视频、音频存储、临时数据缓存空间等。

Raid1
- RAID1 称为镜像,它将数据完全一致地分别写到工作磁盘和镜像 磁盘,它的磁盘空间利用率为 50%
- RAID1 在数据写入时,响应时间会有所影响,但是读数据的时候没有影响
- RAID1 提供了最佳的数据保护,一旦工作磁盘发生故障,系统自动从镜像磁盘读取数据,不会影响用户工作

Raid2
- RAID2 称为纠错海明码磁盘阵列,其设计思想是利用海明码实现数据校验冗余。
- 海明码是一种在原始数据中加入若干校验码来进行错误检测和纠正的编码技术,其中第 2n 位( 1, 2, 4, 8, … )是校验码,其他位置是数据码
海明码宽度和校验码计算
- 如果是 4 位数据宽度需要 4 块数据磁盘和 3 块校验磁盘
- 如果是 64 位数据宽度需要 64 块 数据磁盘和 7 块校验磁盘。
- 海明码的数据冗余开销太大,而且 RAID2 的数据输出性能受阵列中最慢磁盘驱动器的限制。再者,海明码是按位运算, RAID2 数据重建非常耗时。

Raid3
- RAID3 是使用专用校验盘的并行访问阵列,它采用一个专用的磁盘作为校验盘,其余磁盘作为数据盘,数据按位可字节的方式交叉存储到各个数据盘中
- RAID3 至少需要三块磁盘,不同磁盘上同一带区的数据作 XOR 校验,校验值写入校验盘中
- RAID3 完好时读性能与 RAID0 完全一致,并行从多个磁盘条带读取数据,性能非常高,同时还提供了数据容错能力。
- RAID3 写入数据时,必须计算与所有同条带的校验值,并将新校验值写入校验盘中。
- 一次写操作包含了写数据块、读取同条带的数据块、计算校验值、写入校验值等多个操作,系统开销非常大,性能较低。
- 如果 RAID3 中某一磁盘出现故障,不会影响数据读取,可以借助校验数据和其他完好数据来重建数据。

Raid4
- RAID4 与 RAID3 的原理大致相同,区别在于条带化的方式不同。
- RAID4 按照块的方式来组织数据,写操作只涉及当前数据盘和校验盘两个盘,多个 I/O 请求可以同时得到处理,提高了系统性能。
- RAID4 按块存储可以保证单块的完整性,可以避免受到其他磁盘上同条带产生的不利影响。
- RAID4 提供了非常好的读性能,但单一的校验盘往往成为系统性能的瓶颈。
数据块
- 数据块也称为存储块,它包含为文件系统分配的其余空间。这些数据块的大小是在创建文件系统时确定的。
- 缺省情况下,为数据块分配以下两种大小:8 KB 的逻辑块大小和 1 KB 的段大小 (fragment size)。

Raid5
- RAID5 应该是目前最常见的 RAID 等级,它的校验数据分布在阵列中的所有磁盘上,而没有采用专门的校验磁盘。
- 对于数据和校验数据,它们的写操作可以同时发生在完全不同的磁盘上。
- RAID5 还具备很好的扩展性。当阵列磁盘 数量增加时,并行操作量的能力也随之增长
- RAID5 当一个数据盘损坏时,系统可以根据同一条带的其他数据块和对应的校验数据来重建损坏的数据
- 重建数据时, RAID5 的性能会受到较大的影响。

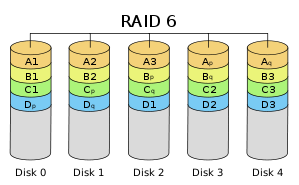
Raid6
- RAID6 引入双重校验的概念,它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。
- RAID6 不仅要支持数据的恢复,还要支持校验数据的恢复,因此实现代价很高,控制器的设计也比其他等级更复杂、更昂贵。
- RAID6 思想最常见的实现方式是采用两个独立的校验算法,假设称为 P 和 Q ,校验数据可以分别存储在两个不同的校验盘上,或者分散存储在所有成员磁盘中。
- RAID6 具有快速的读取性能、更高的容错能力。但是,它的成本要高于 RAID5 许多,写性能也较差,并有设计和实施非常复杂。

CAP原则
定义
- CAP定理是2000年,由 Eric Brewer 提出来的。Brewer认为在分布式的环境下设计和部署系统时,有3个核心的需求,以一种特殊的关系存在。
- 这3个核心的需求是:Consistency,Availability和Partition Tolerance
- CAP定理认为:一个提供数据服务的存储系统无法同时满足数据一致性、数据可用性、分区容忍性

概念
Consistency:
- 一致性,这个和数据库ACID的一致性类似,但这里关注的所有数据节点上的数据一致性和正确性,而数据库的ACID关注的是在在一个事务内,对数据的一些约束。
- 系统在执行过某项操作后仍然处于一致的状态。在分布式系统中,更新操作执行成功后所有的用户都应该读取到最新值。
Availability:
- 可用性,每一个操作总是能够在一定时间内返回结果。需要注意“一定时间”和“返回结果”。
- “一定时间”是指系统结果必须在给定时间内返回。
- “返回结果”是指系统返回操作成功或失败的结果。
Partition Tolerance:
- 分区容忍性,是否可以对数据进行分区。这是考虑到性能和可伸缩性。
推导
- 如果要求对数据进行分区了,就说明了必须节点之间必须进行通信,涉及到通信,就无法确保在有限的时间内完成指定的任务
- 如果要求两个操作之间要完整的进行,因为涉及到通信,肯定存在某一个时刻只完成一部分的业务操作,在通信完成的这一段时间内,数据就是不一致性的。
如果要求保证一致性,那么就必须在通信完成这一段时间内保护数据,使得任何访问这些数据的操作不可用。
结论
- 在大型网站应用中,数据规模总是快速扩张的,因此可伸缩性即分区容忍性必不可少,规模变大以后,机器数量也会变得庞大,这是网络和服务器故障会频繁出现,要想保证应用可用,就必须保证分布式处理系统的高可用性。
在大型网站中,通常会选择强化分布式存储系统的可用性和伸缩性,在某种程度上放弃一致性
数据的一致性
定义
- 一些分布式系统通过复制数据来提高系统的可靠性和容错性,并且将数据的不同的副本存放在不同的机器
在数据有多分副本的情况下,如果网络、服务器或者软件出现故障,会导致部分副本写入成功,部分副本写入失败。这就造成各个副本之间的数据不一致,数据内容冲突。
模型
强一致性
- 要求无论更新操作实在哪一个副本执行,之后所有的读操作都要能获得最新的数据。
弱一致性
- 用户读到某一操作对系统特定数据的更新需要一段时间,我们称这段时间为“不一致性窗口”。
最终一致性
- 是弱一致性的一种特例,保证用户最终能够读取到某操作对系统特定数据的更新。
- 从客户端来看,有可能暂时获取的不是最新的数据,但是最终还是能访问到最新的
- 从服务端来看,数据存储并复制到分布到整个系统超过半数的节点,以保证数据最终一致。
最终一致性
因果一致性(Casual Consistency)
- 如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。
- 与进程A无因果关系的进程C的访问,遵守一般的最终一致性规则。
- 查询微博和评论

读己之所写一致性(read-your-writes)
- 当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
- 读自己的数据都从主服务器去读取,读其他人的数据再从从服务器去读取
- 发表微博与修改微博
会话(Session)一致性
- 这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话。
- 确保会话内访问的都是最新的
单调(Monotonic)读一致性
- 如果进程已经看到过数据对象的某个最新值,那么任何后续访问都不会返回在那个值之前的值。
- 不会读取最旧的数据
单调写一致性
- 系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。
- 按照顺序完成数据的书写


Paxos算法

简介
- Paxos算法是Leslie Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。
- Paxos在1990年提出,被广泛应用于分布式计算中,Google的Chubby,Apache的Zookeeper都是基于它的理论来实现的
- Paxos算法解决的问题是分布式一致性问题,即一个分布式系统中的各个进程如何就某个值(决议)达成一致。
传统节点间通信存在着两种通讯模型:共享内存(Shared memory)、消息传递(Messages passing),Paxos是一个基于消息传递的一致性算法。
算法描述
Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效。每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。 现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。 现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
Paxos推断
- 小岛(Island) 服务器集群
- 议员(Senator) 单台服务器
- 议员的总数(Senator Count)是确定的
- 提议(Proposal) 每一次对集群中的数据进行修改
- 每个提议都有一个编号(PID),这个编号是一直增长的
- 每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效
- 每个议员只会同意大于当前编号的提议
- 每个议员在自己记事本上面记录的编号,他不断更新这个编号
- 整个议会不能保证所有议员记事本上的编号总是相同的
- 议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
- 前期投票(>1/2),后期广播(all)
Paxos算法
- 数据的全量备份
- 弱一致性 -——》最终一致性
算法模型延伸
如果Paxos岛上的议员人人平等,在某种情况下会由于提议的冲突而产生一个“活锁”(所谓活锁我的理解是大家都没有死,都在动,但是一直解决不了冲突问题)。Paxos的作者在所有议员中设立一个总统,只有总统有权发出提议,如果议员有自己的提议,必须发给总统并由总统来提出。
情况一:屁民甲(Client)到某个议员(ZK Server)那里询问(Get)某条法令的情况(ZNode的数据),议员毫不犹豫的拿出他的记事本(local storage),查阅法令并告诉他结果,同时声明:我的数据不一定是最新的。你想要最新的数据?没问题,等着,等我找总统Sync一下再告诉你。
情况二:屁民乙(Client)到某个议员(ZK Server)那里要求政府归还欠他的一万元钱,议员让他在办公室等着,自己将问题反映给了总统,总统询问所有议员的意见,多数议员表示欠屁民的钱一定要还,于是总统发表声明,从国库中拿出一万元还债,国库总资产由100万变成99万。屁民乙拿到钱回去了(Client函数返回)。
情况三:总统突然挂了,议员接二连三的发现联系不上总统,于是各自发表声明,推选新的总统,总统大选期间政府停业,拒绝屁民的请求。无主集群模型
人人都会发送指令,投票
投票人数有可能导致分区(分不同阵营),
- 6个节点 33对立
- 类似于以前党争
事务编号混乱,每个节点都有可能有自己的提议
- 提议的编号不能重复和小于
有主集群模型
- 只能有一个主发送指令,发送提议
单主会单点故障,肯定有备用的方案
- 重新选举
- 切换到备用节点
- 如果存在多个主就会脑裂
主要集群中节点数目高于1/2+1,集群就可以正常运行

Raft算法
简介
- Raft 适用于一个管理日志一致性的协议,相比于 Paxos 协议 Raft 更易于理解和去实现它。
- Raft 将一致性算法分为了几个部分,包括领导选取(leader selection)、日志复制(log replication)、安全(safety)
- http://thesecretlivesofdata.c...
问题
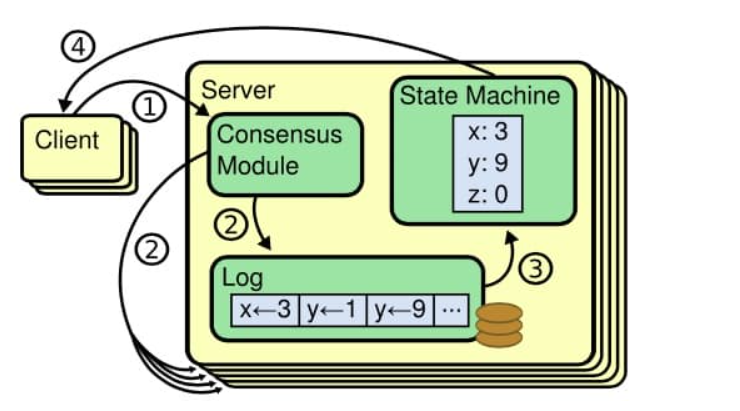
分布式存储系统通过维护多个副本来提高系统的availability,难点在于分布式存储系统的核心问题:
- 维护多个副本的一致性。
Raft协议基于复制状态机(replicated state machine)
- 一组server从相同的初始状态起,按相同的顺序执行相同的命令,最终会达到一致的状态
- 一组server记录相同的操作日志,并以相同的顺序应用到状态机。
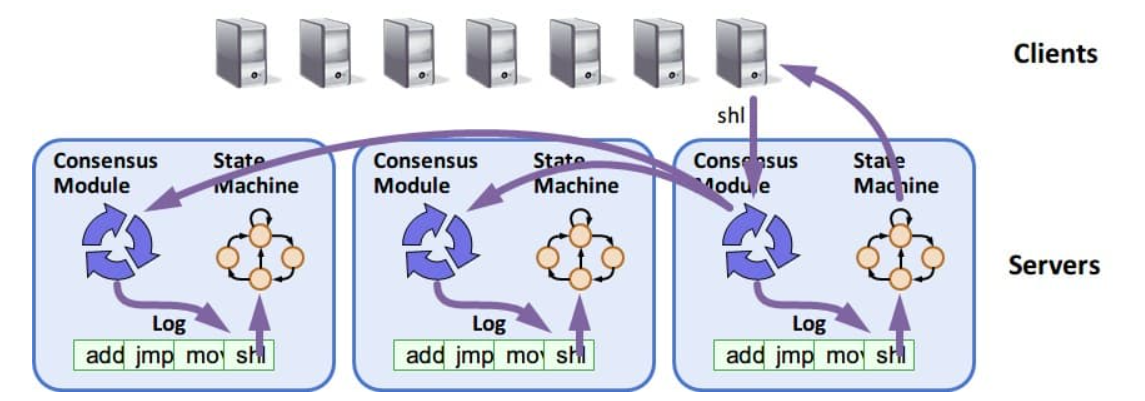
Raft有一个明确的场景,就是管理复制日志的一致性。
- 每台机器保存一份日志,日志来自于客户端的请求,包含一系列的命令,状态机会按顺序执行这些命令。
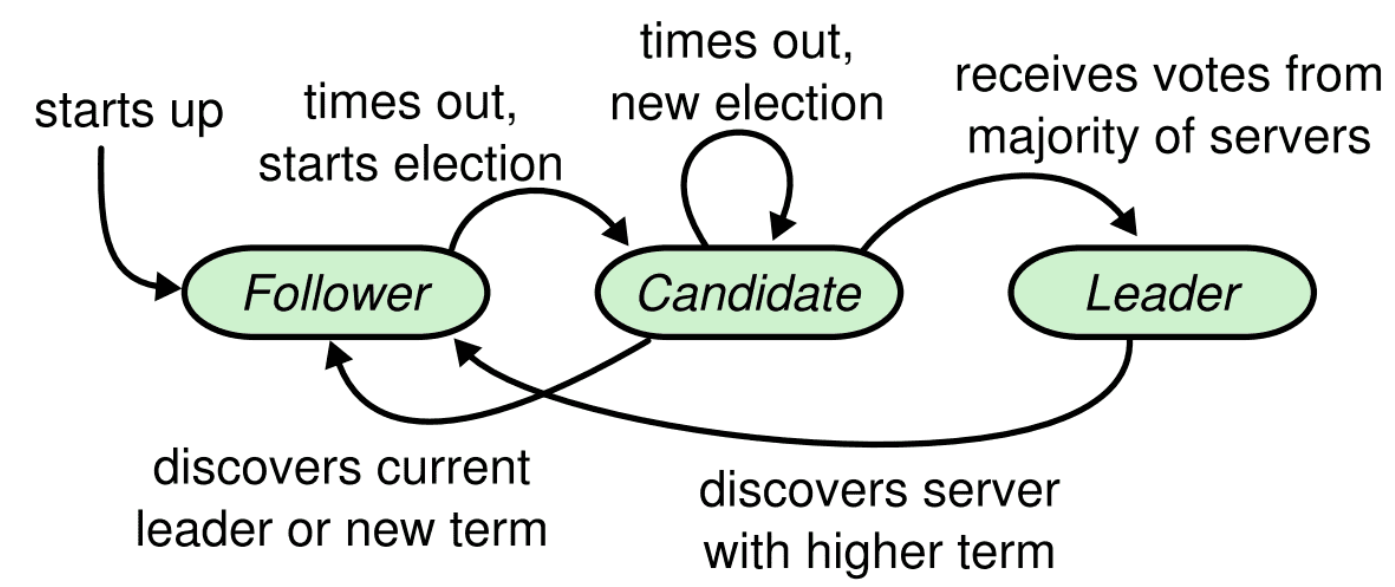
角色分配
Raft算法将Server划分为3种状态,或者也可以称作角色:
Leader
- 负责Client交互和log复制,同一时刻系统中最多存在1个。
Follower
- 被动响应请求RPC,从不主动发起请求RPC。
Candidate
- 一种临时的角色,只存在于leader的选举阶段,某个节点想要变成leader,那么就发起投票请求,同时自己变成candidate
算法流程
Term
- Term的概念类比中国历史上的朝代更替,Raft 算法将时间划分成为任意不同长度的任期(term)。
- 任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最多只有一个领导人
RPC
- Raft 算法中服务器节点之间通信使用远程过程调用(RPCs)
- 基本的一致性算法只需要两种类型的 RPCs,为了在服务器之间传输快照增加了第三种 RPC。
- RequestVote RPC:候选人在选举期间发起
- AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成
- InstallSnapshot RPC: 领导者使用该RPC来发送快照给太落后的追随者
日志复制(Log Replication)
- 主要用于保证节点的一致性,这阶段所做的操作也是为了保证一致性与高可用性。
- 当Leader选举出来后便开始负责客户端的请求,所有事务(更新操作)请求都必须先经过Leader处理
- 日志复制(Log Replication)就是为了保证执行相同的操作序列所做的工作。
- 在Raft中当接收到客户端的日志(事务请求)后先把该日志追加到本地的Log中
- 然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日志后记录日志然后向Leader发送ACK
- 当Leader收到大多数(n/2+1)Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中
- 通知客户端并在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中。
Zookeeper

角色分配
- 小岛——ZK Server Cluster
总统——ZK Server Leader
- 集群中所有修改数据的指令必须由总统发出
- 总统是由议员投票产生的(无主-->有主)
选举条件
- 首先按照事务zxid进行排序
- 如果事务相同按照myid排序
议员(Senator)——ZK Server Learner
接受客户端请求
- 查询直接返回结果(有可能数据不一致)
写入数据,先将数据写入到当前server
- 发送消息给总统,总统将修改数据的命令发送给其他server
- 其他server接受命令后开始修改数据,修改完成后给总统返回成功的消息
- 当总统发现超过半数的人都修改成功,就认为修改成功了
- 并将信息传递给接受请求的zkServer,zkServer将消息返回给客户端,说明数据更新完成
分类Learner
Follower
- 拥有选举权
- 拥有投票权
- 接受客户端的访问
Observer
- 只可以为客户端提供数据的查询和访问
- 如果客户端执行写请求,只是将请求转发给Leader
提议(Proposal)——ZNode Change
- 客户端的提议会被封装成一个节点挂载到一个Zookeeper维护的目录树上面
- 我们可以对数据进行访问(绝对路径)
- 数据量不能超过1M
提议编号(PID)——Zxid
- 会按照数字序列递增,不会减少不会重复
正式法令——所有ZNode及其数据
- 超过半数的服务器更新这个数据,就说明数据已经是正式的了
屁民--Client
- 发送请求(查询请求,修改请求)
搭建Zookeeper
- 首先将三台虚拟机切换到相互免秘钥快照(keysfree)
上传Zookeeper,解压,拷贝
[root@node01 ~]# tar -zxvf zookeeper-3.4.5.tar.gz
修改配置文件
[root@node01 conf]# cd /opt/xxx/zookeeper-3.4.5/conf/ [root@node01 conf]# cp zoo_sample.cfg zoo.cfg [root@node01 conf]# vim zoo.cfg# the directory where the snapshot is stored. dataDir=/var/xxx/zookeeper # the port at which the clients will connect clientPort=2181 # 设置服务器内部通信的地址和zk集群的节点 server.1=node01:2888:3888 server.2=node02:2888:3888 server.3=node03:2888:3888
创建myid
[123]mkdir -p /var/xxx/zookeeper [123]touch /var/xxx/zookeeper/myid [1] echo 1 > /var/xxx/zookeeper/myid [2] echo 2 > /var/xxx/zookeeper/myid
拷贝Zookeeper
[root@node01 xxx]scp -r zookeeper-3.4.5 root@node02:/opt/xxx/
设置环境变量
- vim /etc/profile
export ZOOKEEPER_HOME=/opt/xxx/zookeeper-3.4.5
- [1]scp /etc/profile root@node02:/etc/profile - [1]scp /etc/profile root@node03:/etc/profile - [123] source /etc/profile开启集群
- [123] zkServer.sh start
- [123] zkServer.sh status
- [123] zkServer.sh stop
关机拍摄快照
- shutdown -h now
Zookeeper存储模型
存储结构
- zookeeper是一个树状结构,维护一个小型的数据节点znode
- 数据以keyvalue的方式存在,目录是数据的key
- 所有的数据访问都必须以绝对路径的方式呈现
[zk: localhost:2181(CONNECTED) 10] get /xxx 666 当前节点的值 cZxid = 0xf00000013 创建这个节点的事务id ctime = Mon Dec 09 17:33:06 CST 2019 创建时间 mZxid = 0xf00000013 最后一次修改节点数据的事务ID mtime = Mon Dec 09 17:33:06 CST 2019 修改时间 pZxid = 0xf00000014 子节点的最新事务ID cversion = 1 对此znode的子节点进行的更改次数 dataVersion = 对此znode的数据所作的修改次数 aclVersion = 对此znode的acl更改次数 ephemeralOwner = 0x0 (持久化节点)0x16ee9fc0feb0001(临时节点) dataLength = 3 数据的长度 numChildren = 1 子节点的数目节点的分类
持久化节点(PERSISTENT)
- 默认创建的就是持久化节点
临时节点(Ephemral)
- 只在创建节点的会话有效时,创建节点会话失效之后就会失效
- 可以被所有的客户端所查看
- create -e
序列化节点(Sequential)
- 在名字的后面添加一个序列号(有序)
- create -s
ZKServer的命令
- 启动ZK服务: bin/zkServer.sh start
- 查看ZK服务状态: bin/zkServer.sh status
- 停止ZK服务: bin/zkServer.sh stop
- 重启ZK服务: bin/zkServer.sh restart
- 连接服务器: zkCli.sh -server 127.0.0.1:2181
二、连接zk
Linux环境下:
eg、zkCli.sh -server 127.0.0.1:2181
三、zk客户端命令
1.ls -- 查看某个目录包含的所有文件,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /
ls /path
2.ls2 -- 查看某个目录包含的所有文件,与ls不同的是它查看到time、version等信息,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] ls2 /
3.create -- 创建znode,并设置初始内容,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] create /test "test"
Created /test
创建一个新的 znode节点“ test ”以及与它关联的字符串
create /path data 默认创建持久节点
create -s /path data 创建顺序节点
create -e /path data 创建临时节点
create /parent/sub/path /data
4.get -- 获取znode的数据,如下:
[zk: 127.0.0.1:2181(CONNECTED) 1] get /test
get /path
get /path0000000018 访问顺序节点必须输入完整路径
5.set -- 修改znode内容,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] set /test "ricky"
set /path /data
6.delete -- 删除znode,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] delete /test
delete /path 删除没有子节点的节点
rmr /path 移除节点并且递归移除所有子节点
7.quit -- 退出客户端
8.help -- 帮助命令
## ZKServer的监听机制
- 官方说明
- 一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
- 机制特点
- 一次性触发 数据发生改变时,一个watcher event会被发送到client,但是client只会收到一次这样的信息。
- watcher event异步发送
- 数据监视
- Zookeeper有数据监视和子数据监视 getdata() and exists() 设置数据监视,getchildren()设置了子节点监视
- ```
//watch监听有不同的类型,有监听状态的stat ,内容的get,目录结构的ls。
get /path [watch] NodeDataChanged
stat /path [watch] NodeDeleted
ls /path [watch] NodeChildrenChanged父节点Watcher事件类型:
- 创建父节点触发: NodeCreated
- 修改父节点数据触发: NodeDataChanged
- 删除父节点触发: NodeDeleted
子节点Watcher事件类型:
- 使用ls命令为父节点设置watcher,子节点被创建时触发:NodeChildrenChanged
使用ls命令为父节点设置watcher,子节点被删除时触发:NodeChildrenChanged
- 使用ls命令为父节点设置watcher,子节点被修改时,不触发事件
ACL权限控制(了解)
ACL权限控制
ZK的节点有5种操作权限:CREATE、READ、WRITE、DELETE、ADMIN 也就是 增、删、改、查、管理权限,这5种权限简写为crwda,这5种权限中,delete是指对子节点的删除权限,其它4种权限指对自身节点的操作权限
身份的认证有4种方式:
- world:默认方式,相当于全世界都能访问
- auth:代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户)
- digest:即用户名:密码这种方式认证,这也是业务系统中最常用的
- ip:使用Ip地址认证
schema
world:只有一个用户anyone,代表所有人(默认)
ip:使用IP地址认证
auth:使用已添加认证的用户认证
digest:使用用户名:密码 方式认证
id
world:只有一个id,anyone
ip:通常是一个ip地址或者地址段
auth:用户名
digest:自定义
权限
create 简写为c,可以创建子节点
delete 简写为d 可以删除子节点
read 简写为r 可以读取节点数据及显示子节点列表
write 简写为w 可以设置节点数据
admin 简写为a 可以设置管理权限
查看ACL
getAcl /parent
设置ACL
setAcl /parent world:anyone:wa
添加用户
addauth digest zhangsan:123456
设置权限
setAcl /parent auth:zhangsan:123456:rcwda四字命令(了解)
安装nc
- yum install nc -y
- 如果出现下图的错误,请重新清空和重构cache

四字命令
ZooKeeper 支持某些特定的四字命令(The Four Letter Words)与其进行交互。
使用方式,在shell终端输入:echo 四字命令| nc node01 2181
| ZooKeeper四字命令 | 功能描述 |
|---|---|
| conf | 打印出服务相关配置的详细信息。 |
| cons | 列出所有连接到这台服务器的客户端全部连接/会话详细信息。 |
| crst | 重置所有连接的连接和会话统计信息。 |
| dump | 列出那些比较重要的会话和临时节点。这个命令只能在leader节点上有用。 |
| envi | 打印出服务环境的详细信息。 |
| reqs | 列出未经处理的请求 |
| ruok | 测试服务是否处于正确状态。如果确实如此,那么服务返回"imok",否则不做任何相应。 |
| stat | 输出关于性能和连接的客户端的列表。 |
| srst | 重置服务器的统计。 |
| srvr | 列出连接服务器的详细信息 |
| wchs | 列出服务器watch的详细信息。 |
| wchc | 通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表。 |
| wchp | 通过路径列出服务器watch的详细信息。它输出一个与session相关的路径。 |
| mntr | 输出可用于检测集群健康状态的变量列表 |
Zookeeper环境搭建(了解)
- 基于Observer的环境搭建
- Zookeeper的热部署
感谢大家的认同与支持,小编会持续转发《优极限》优质文章