几句主题外:开通了专栏,这样我就在干脆把最近整理的乱七八糟的东西都写在这里。
打开方式:先看书或者别的资料,再有选择性的看一些知识点。全文可能很枯燥,也没有一本精心编写的教科书来的丰富有趣。
快速过一遍:跳到keyword,查看有没有不大清楚的词。
keyword: average, median, mode, univariate, bivariate, nominal attribute, ordinal attribute, numeric attribute, quantile, quartile, 五数概括, boxplot, variance, standard deviation, Quantile-Quantile Diagram, Jaccard, Minkowski distance
1.统计学的常用统计概念
中位数median, 理论上是所有出现数值按从小到大顺序排列后最中间的那个数
实际的定义:
当出现次数是奇数,那么中位数是确定且唯一的。
当出现次数是偶数,那么中位数是不确定且不唯一的,中位数的取值范围应该是最中间的两个数 [a, b].
众数mode,出现次数最多的那个数。这个数可能不唯一,导致函数是单峰的unimodal、双峰的bimodal、多峰的multimodal.
注意:不是说众数只有1个,函数就只有这一个极大值了,只能说明函数只有这一个最大值,即函数图像仍有可能有几处凸起。
平均数average, 把该attribute的所有的出现的数值加在一起,除以该attribute所有出现数值的次数
加权平均数weighted average:平均数的广义版本,即在每个数据有不同的权重时,每项系数乘以权重,分母为所有权重之和
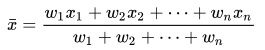
截尾均值trimmed mean: 用于处理离群点比较多的情况,砍掉最小和最大的一小部分,例如各5%,再取均值。
分位数quantile: 即按照数据分布函数,把数据等分为n块“大小”相等的区域。在大多数情况下,我们考虑四分位数(quartile)和百分位数(precentile).
四分位数极差IQR:这个度量可以在某种程度上帮助我们建立对分部情况的大致了解,包括分布是否倾斜等。
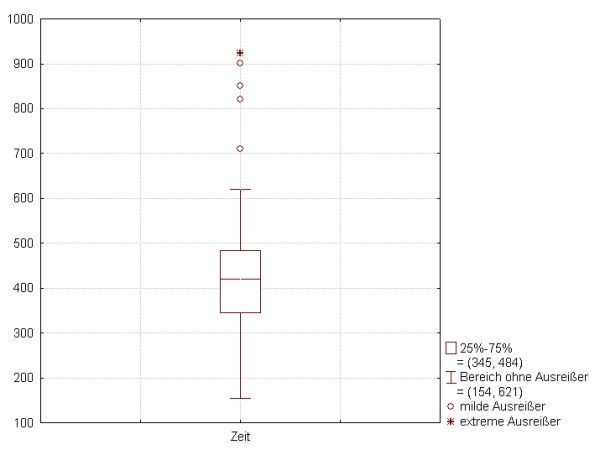
五数概括(five-number summary): 中位数Q2、四分位数Q1,Q3, 最小和最大观测值
盒图boxplot: 五数概括的直观体现
1.盒的端点一般在四分数位Q1, Q3上
2.中位数用盒內实线标记
3.盒外的虚线延伸到最小和最大观测值,但最多向上延伸到1.5倍IQR(如果小于1.5倍IQR的值没有达到1.5倍IQR,延伸到这个值就可以了).
如果有超过1.5倍IQR的值,单独标出
方差variance: 数据稳定性的一个观测标准,即所有值和平均值之差的平方和。
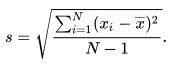
标准差standard deviation: 方差的平方根
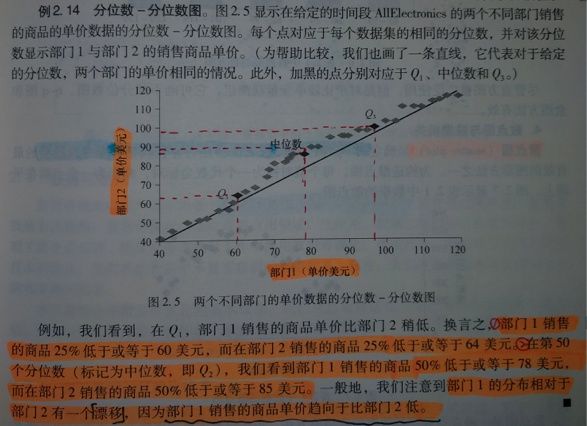
分位数-分位数图(quantile-quantile diagram): 通过可视化图表观察从一个分布到另一个分布是否有漂移。
2.属性attribute
属性,是单个数据条目被视作数据对象的情况下,表示数据对象特征的。
在数据仓库中通常用别名维dimension来表示属性。
在机器学习中通常用特征feature来表示属性。
2-1. 标称属性nomial attribute
标称属性的值是一些符号或事物的名称,它的值不必具有有意义的序(与叙述属性区分开)。
e.g. hair_color 是一个标称属性,它的取值包括black, brown, white等。
2-2. 二元属性
二元属性是一种标称属性,只有两个类别或状态,0或1,二元属性又称布尔属性。
通常,取值0表示该属性不出现,取值1表示该属性出现。
如果两种状态同等价值且携带了相同权重,e.g. 性别 男 女, 呢么他是对称的
如果两种状态是非对称的,其状态的结果不是同样重要的。e.g. HIV的阳性和阴性
2-3 序数属性 ordinal attribute
与标称属性的概念有所区别,叙述属性是可能的值之间有一定有意义的序(order)或秩(rank)组成的。
e.g. 职称 讲师,副教授,教授...
满意度 不满意->非常满意
2-4 数值属性numeric attribute
数值属性是定量的,即他是可度量的量,用整数或实数值表示。
区间标度interval-scaled,能比较数值的绝对差值(e.g.20摄氏度比10摄氏度高10摄氏度)
比率标度ratio-scaled,具有固定零点,因而可以比较比率(e.g.100美元是1美元的100倍)
2-5 属性的连续和离散
值得强调的是,离散数据并不一定是有穷的,可以是无穷多个e.g.整数集
2-6 度量数据的相似性和相异性
相似性similarity和相异性dissimilarity都称为邻近性proximity.
相异性矩阵 dissimilarity matrix: 由d(i, j) 组成的下三角矩阵
其中d(i, j)为数据对象i和j的相异性度量。
对于标称数据, 相似性 sim(i, j) = 1 - d(i, j)
[图片上传失败...(image-87407f-1544357430184)]
d(i, j ) = \frac{p-m}{p}
其中m是match属性的总数,p是#property
上述相异性计算式是一元属性的,接下来讨论二元属性
[图片上传失败...(image-37aa3f-1544357430184)]
d(i, j ) = \frac{r+s}{q+r+s+t}
其中,q为i, j 中都取1的属性个数,r为i中取1, j中取0的属性个数,s为i中取0j中取1的属性个数,t为i, j中都取0的属性个数
负匹配t被认为是不重要的,在计算中常常被忽略,则得到:
[图片上传失败...(image-76e119-1544357430184)]
d(i, j ) = \frac{r+s}{q+r+s}
则此时 [图片上传失败...(image-5a6938-1544357430184)]
sim(i, j) = 1-d(i, j ) = \frac{q}{q+r+s}
这个系数sim(i, j)被称为Jaccard系数
数值数据的相异性:距离
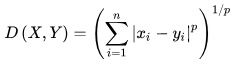

当p=2, 该距离又称为欧几里得距离(Euclidean Distance),即通常我们所说的直线距离
当p=1, 该距离又称为曼哈顿距离(Manhattan Distance), 即沿着坐标轴累积的“街区”距离
在某些文献中,Minkowski Distance又称为Lp norm.
上确界距离(Lmax或切比雪夫距离Chebyshev Distance),h->infinite时的距离,即极限距离。
假设所分析的数据包括属性age, 它在数据源组中的值(以递增序)为13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70.
(a)该数据的均值是多少?中位数是什么?
avg = 809 / 27 = 29.96
median = 25
(b)该数据的众数是什么?讨论数据的模态?
mode=25, 35(都是4个), bimodal
(c)该数据的中列数是什么?
中列数即最大值和最小值两个值的平均值,这个值在数据挖掘中很少使用,因为离群点会造成这个值很大的变动。
midrange = (70+13)/2 = 41.5
(d)你能(粗略的)找出该数据的四分位数Q1和Q3吗?
可以,我们通过第二个四分位数Q2为中位数可得,前半段的中位数大约是Q1,后半段的中位数大约是Q3,这样的估计方法实际上是不准确的。
粗略的, Q1 = 20.5
Q3 = 35
(e)五数概括
max = 70
min = 13
Q1 = 20.5
Q2(median) = 25
Q3 = 35
(f)绘制盒图

两个轴和标度数据略
(g)分位数图和Q-Q图有什么区别?
分位数图只涉及单个分布,可以看出对于单一属性,它的分布情况。
Q-Q图是两个分布的比较,通过比较可以看出属性A到属性B是否有漂移,这是属性间的相对关系。