机器翻译技术发展了80多年,巴别塔的传说已经成为过去,上天是不可能上天的了,但是让你优雅地和全世界讨论世界杯,不再手舞足蹈、鸡同鸭讲,这一点机器翻译还是可以做到的!
01机器翻译和巴别塔的传说
《圣经》中记载了这样一个故事:
人类曾经联合起来兴建能通往天堂的高塔——巴别塔,为了阻止人类的计划,上帝让人类说不同的语言,使人类相互之间不能沟通,计划因此失败,人类自此各散东西。
实现不同语种之间的无障碍沟通,一直都是人类终极梦想之一。

在认识到不眠不休穷尽人类一生的力量,也只能掌握几十种语言时,很多科学家开始思考,如何用机器来帮助人们去解决沟通问题,于是机器翻译应运而生。
机器翻译其实是利用计算机把一种自然语言翻译成另一种自然语言的过程,基本流程大概分为三块:预处理、核心翻译、后处理。
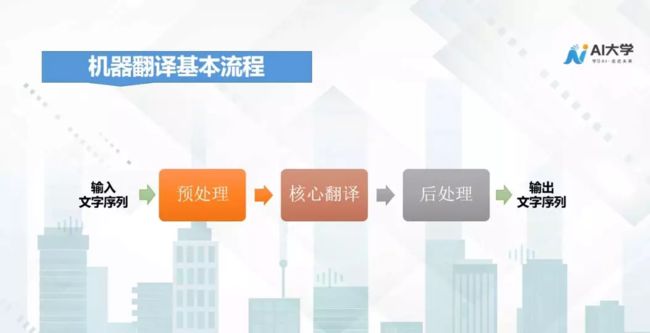
预处理是对语言文字进行规整,把过长的句子通过标点符号分成几个短句子,过滤一些语气词和与意思无关的文字,将一些数字和表达不规范的地方,归整成符合规范的句子。
核心翻译模块是将输入的字符单元、序列翻译成目标语言序列的过程,这是机器翻译中最关键最核心的地方。
后处理模块是将翻译结果进行大小写的转化、建模单元进行拼接,特殊符号进行处理,使得翻译结果更加符合人们的阅读习惯。
02曲折中前行的机器翻译
机器翻译的故事始于1933年,从最开始的只是科学家脑海中一个大胆设想,到现在大规模的开始应用,机器翻译技术的发展道路大概有6个阶段。

起源阶段:
机器翻译起源于1933年,由法国工程师G.B.阿尔楚尼提出机器翻译设想,并获得一项翻译机专利;
萌芽时期:
1954年,美国乔治敦大学在IBM公司协同下用IBM-701计算机首次完成了英俄机器翻译试验,拉开了机器翻译研究的序幕;
沉寂阶段:
美国科学院成立了语言自动处理咨询委员会(ALPAC)于1966年公布了一份名为《语言与机器》的报告,该研究否认机器翻译可行性,机器翻译研究进入萧条期;
复苏阶段:
1976年,加拿大蒙特利尔大学与加拿大联邦政府翻译局联合开发的TAUM-METEO系统,标志着机器翻译的全面复苏;
发展阶段:
1993年,IBM的Brown等提出基于词对齐的统计翻译模型,基于语料库的方法开始盛行;
2003年,爱丁堡大学的Koehn提出短语翻译模型,使机器翻译效果显著提升,推动了工业应用;
2005年,David Chang进一步提出了层次短语模型,同时基于语法树的翻译模型方面研究也取得了长足的进步;
繁荣阶段:
2013年和14年,牛津大学、谷歌、蒙特利尔大学研究人员提出端到端的神经机器翻译,开创了深度学习翻译新时代;
2015年,蒙特利尔大学引入Attention机制,神经机器翻译达到实用阶段;
2016年,谷歌GNMT发布,讯飞上线NMT系统,神经翻译开始大规模应用。
03机器翻译的技术原理
在讲机器翻译的技术原理之前,我们先来看一张机器翻译技术发展历史图:
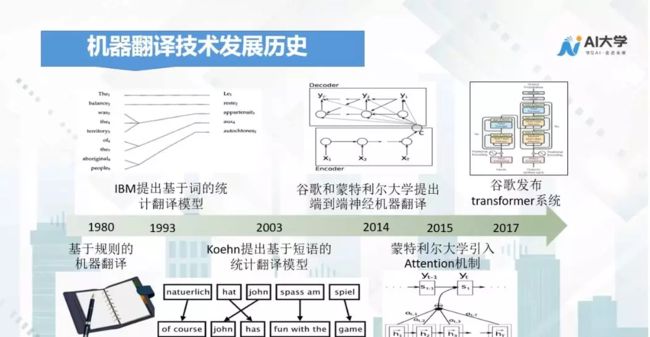
20世纪80年代基于规则的机器翻译开始走向应用,这是第一代机器翻译技术。随着机器翻译的应用领域越来越复杂,基于规则的机器翻译的局限性开始显现,应用场景越多,需要的规则也越来越多,规则之间的冲突也逐渐出现。
于是很多科研学家开始思考,是否能让机器自动从数据库里学习相应的规则,1993年IBM提出基于词的统计翻译模型标志着第二代机器翻译技术的兴起。
2014年谷歌和蒙特利尔大学提出的第三代机器翻译技术,也就是基于端到端的神经机器翻译,标志着第三代机器翻译技术的到来。
看完了机器翻译技术的迭代发展,我们来了解下三代机器翻译的核心技术:规则机器翻译、统计机器翻译、神经机器翻译。
规则机器翻译
基于规则的机器翻译大概有三种技术路线,第一种是直接翻译的方法,对源语言做完分词之后,将源语言的每个词翻译成目标语言的相关词语,然后拼接起来得出翻译结果。
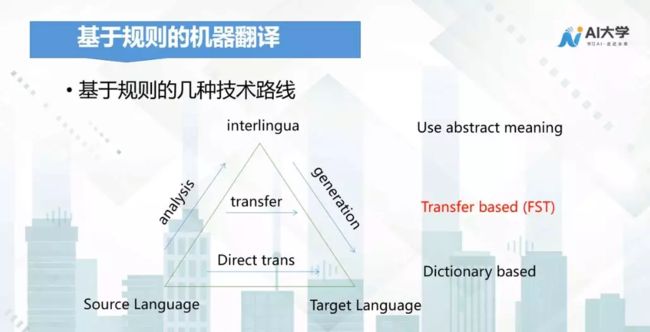
由于源语言和目标语言并不在同一体系下,句法顺序有很大程度上的出入,直接拼接起来的翻译结果,效果往往并不理想。
于是科研人员提出了第二个规则机器翻译的方法,引用语言学的相关知识,对源语言的句子进行句法的分析,由于应用了相关句法语言学的知识,因此构建出来的目标译文是比较准确的。
但这里依然存在着另外一个问题,只有当语言的规则性比较强,机器能够做法分析的时候,这套方法才比较有效。
因此在此基础之上,还有科研人员提出,能否借助于人的大脑翻译来实现基于规则的机器翻译?
这里面涉及到中间语言,首先将源语言用中间语言进行描述,然后借助于中间语言翻译成我们的目标语言。
但由于语言的复杂性,其实很难借助于一个中间语言来实现源语言和目标语言的精确描述。
讲完了基于规则的机器翻译的三种技术路线,我们用一张图来总结下它的优缺点:

统计机器翻译
机器翻译的第二代技术路线,是基于统计的机器翻译,其核心在于设计概率模型对翻译过程建模。
比如我们用x来表示原句子,用y来表示目标语言的句子,任务就是找到一个翻译模型
θ 。
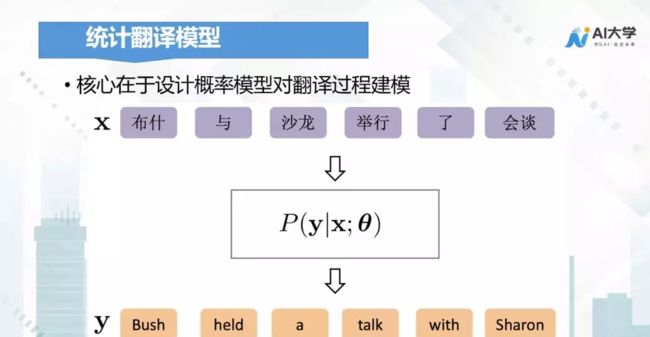
最早应用于统计翻译的模型是信源信道模型,在这个模型下假设我们看到的源语言文本 x是由一段目标语言文本 y 经过某种奇怪的编码得到的,那么翻译的目标就是要将 y 还原成 x,这也就是一个解码的过程。
所以我们的翻译目标函数可以设计成最大化Pr(│),通过贝叶斯公式,我们可以把Pr(│)分成两项,Pr() 的语言模型,Pr(|)的翻译模型

如果将这个目标函数两边同取log,我们就可以得到对数线性模型,这也是我们在工程中实际采用的模型。
对数线性模型不仅包括了翻译模型、语言模型,还包括了调序模型,扭曲模型和词数惩罚模型,通过这些模型共同约束来实现源语言到目标语言的翻译。
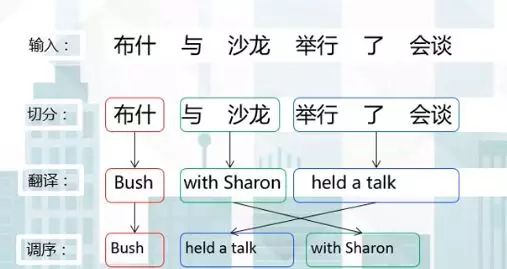
讲完了统计机器翻译的相关知识,我们来看下基于短语的统计翻译模型的三个基本步骤:
1、源短语切分:把源语言句子切分成若干短语
2、源短语翻译:翻译每一个源短语
3、目标短语调序:按某顺序把目标短语组合成句子
最后,我们依旧用一张图来总结下基于统计机器翻译的优缺点:

神经机器翻译
讲完了基于规则的机器翻译和基于统计的机器翻译,接下来我们来看下基于端到端的神经机器翻译。
神经机器翻译基本的建模框架是端到端序列生成模型,是将输入序列变换到输出序列的一种框架和方法。
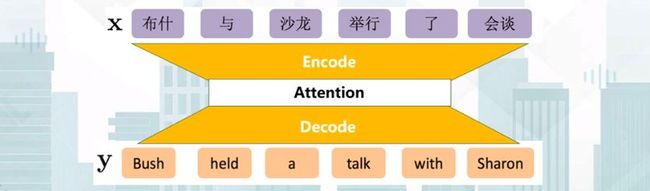
其核心部分有两点,一是如何表征输入序列(编码),二是如何获得输出序列(解码)。
对于机器翻译而言不仅包括了编码和解码两个部分,还引入了额外的机制——注意力机制,来帮助我们进行调序。
下面我们用一张示意图来看一下,基于RNN的神经机器翻译的流程:
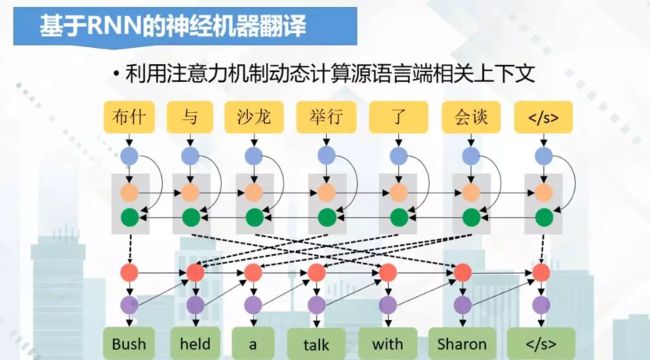
首先我们通过分词得到输入源语言词序列,接下来每个词都用一个词向量进行表示,得到相应的词向量序列,然后用前向的RNN神经网络得到它的正向编码表示。
再用一个反向的RNN,得到它的反向编码表示,最后将正向和反向的编码表示进行拼接,然后用注意力机制来预测哪个时刻需要翻译哪个词,通过不断地预测和翻译,就可以得到目标语言的译文。
04机器翻译的基本应用
机器翻译的基本应用可分为三大场景:信息获取为目的场景、信息发布为目的的场景、信息交流为目的场景。
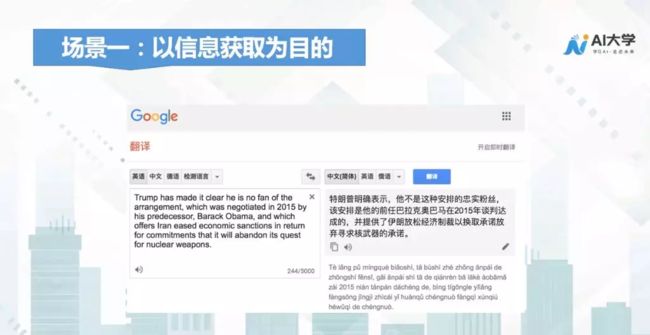
以信息获取为目的的应用场景,可能大家都比较熟悉,比如说翻译或是海外购物,遇到一些生僻的词就可以借助机器翻译技术,来了解它的真正意思。
在信息发布为目的的场景中,典型的应用是辅助笔译。
大家应该都还记得本科毕业论文需要用英文写个摘要。不少同学都是利用谷歌的翻译,将中文摘要翻译成英文摘要,然后再做一些简单的调序,得出最终的英文摘要,其实这就是一个简单的辅助笔译的过程。
第三大场景就是以信息交流为目的场景,主要解决人与人之间的语言沟通问题。
作者:AI研究所
链接:https://www.jianshu.com/p/4fc3fa8cdfe0
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。