AxonFramework是我们交易系统选择的架构基础, 使用CQRS/EventSource 不拘泥于框架使用,其实不套用任何的框架,自己构建可能有更多的调整和细化的余地, 选用一个框架, 可以加快开发的速度-至少是前期, 但是也有很多框架上面的掣肘, 得失在于自己使用中的权衡,此篇主要讲讲CQRS中基础的domain 中event storage.
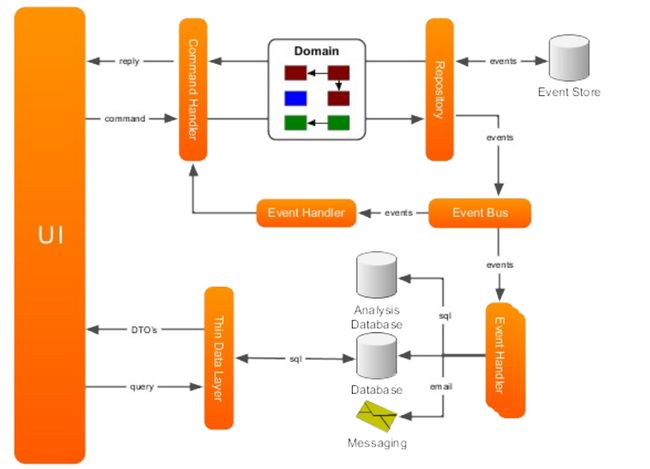
Axonframework, 现在到3.0 版本, 由 Allard Buijze, 作为主要贡献者, 后面有一个商业化咨询团队支持:AxonIQ 的开源项目, 在JAVA 中是历史比较长的开源CQRS项目, 其实不久前有一个 reveno, 在一些存储落地方面采用更激进的方案, 但是现在好像不怎么维护, 既然要上production, 还是选择比较成熟, 社区比较活跃的开源项目。 Allard Buijze 本人也比较热心, 在社区问的问题基本在3天内能够回答, Axon对分布式支持不是太友好, 包括Event storage 的瓶颈, 有次专门写信给他们团队, 他们还是特意安排了个gotomeeting, 讲解了半个小时,非常热心, 对次Event source AxonIQ 提出了一个 Beta Programmer 试图使用 AKKA persistent Actors 解决, 最终这个项目没有太多的更新, 但是项目时间不等人, 所以我们改造了比较关键的几个模块, 能够更友好的对缓存和分布式支持。
Event Store 的瓶颈
在我们使用Event source 设计方案的时候,不能不讨论后面的落地方案 Event store; Event source 的本质不是只保存一个对象最新的状态,而是到达这个最新状态所有的历程和经过。这一系列的过程和经历就是一个事件链,当然大家还习惯只在乎现在的状态,现在的状态可以从这系列的事件中得到, 在Event source 习惯称呼这个为projection.
Event source 不是一个新的概念, 由Martin Fowler 十几年前就提出来了。但是这个当时只是一个小众的技术, 现如今变成了主流,大概因为这样的理念更适合当下的几大应用:
- 大数据, 机器学习,人工智能等告诉我们历史数据非常重要, 里面可能隐藏着宝贵的矿藏,有效的分析利用他们,可以揭示很有商业后面的秘密,这些都基于你积累了这些历史数据, 在传统的应用中,我们可能很少或者没有记录这里历史的数据和转变过程。而Event source 架构下, 需要记录所有历史状态,这样可以恢复到过去的任何一个状态。
- 在高分布式系统中, 一事件驱动的微服务设计架构已近变得流行, 如果你需要设计一个一事件驱动的微服务系统,他需要一个落地方案,Event source 是个不错的选择。
- 现在我们的系统需要面临越来越多的监管压力,有些业务需求我们展示系统发生的任何细节,Event source 可以满足这样的需求。
某种意义上来说, event 和其他数据类型没有什么差异,但是作为event source 中的event又有自身的特征。
写
映入我脑海的第一映象, event store应该是一个append-only 的数据库, event 代表过去已经发生的事情,于是他不可以删除和更改,比起CRUD,这样的特征让数据库设计更简单, 这样其实一个复杂成熟的关系数据库有点大材小用,在我们写入event 的时候还是要注意事务, 特别在一系列事件需要在一个事务中处理, 需要保证原子性操作, 还有同一个对象上面的事物, 需要有对象的sequence 序列,保证唯一性; 其实也就是相当于版本号。特别在并发访问的情况下需要保证一致性。
读
读事件同时有他的特点, 事件有时序性, 也就是每个有一个sequence number, 一般会批量的读取, 或者整个读取,比如在做replay的时候, 最近的数据趋向于更高概率被读到, 比如在从snapshot 恢复状态的时候, 这里时序性非常重要不能打破, 也就是某个聚合跟上面发生的事件, 一定是有先后关系的。
如何界定历史事件和当前事件会有点模糊, 事件更像是一个事件流,当一个聚合跟被创建的时候, 从某个点开始的事件被读出来,加上新进来的事件, 形成一个stream,以供消费,这些事件是连贯的,对于下面的聚合跟, 不会区分是历史的还是刚刚发生的。
扩展性和弹性
比较我们传统的仅仅保存一个对象的最后一个状态, event source需要保存更多的信息:他是保存导致状态变化的所有事件,这些数据将会不断的增长,单纯落地到磁盘上不是一个很大的问题, 挑战是要保证很高的读写效率, 在你的业务量增长后, 保证底层的db 的可扩展性非常重要, 多个节点冗余备份数据是个必要的选择。
Event Source 特有需求
一般Event source都要满足这些需求: 对象状态要做snapshot ,也就是特定的时间点对象状态的保存, 这个点的状态由之前发生所有事件得到最后状态, 做snapshot 不是一个必须的选择, 但是有他可以大大节约你恢复状态的时间,你不需要从头第一个事件来得到最后的状态。 同时在一个大型的系统中, 事件也是不同模块之间交互的桥梁, 这些事件有自己的上下文,所以在设计这些事件的时候要注意粒度, 可能需要在发送前进行,切分,聚合或者转换。
事件存储Event storage选择
更具这些特质我们可以对照现下我们的选择, 确实有很多的选择方案,一个传统的关系数据库, 一个简单的event table,可供选择的, 比如Mysql, Oracle, SQL server 等等。
很多公司开始时候趋向于选择他们, 一个是公司本来就在用, 带入成本低,经验比较丰富, 当扩展性渐渐变成瓶颈后,可能大家发现关系数据库和event source 不是最佳搭配,现在的数据库主要为随机的CRUD, 还有很多高级的sql 语法上面的功能, 但是对于event source这些不是必要的,而去有点多余, 他仅仅是为快速的批量读写事件信息,当今的关系数据库集群的代价还是比较大;而比起后起之秀的 MongoDB, 和ElasticSearch等等天然的集群和易扩展性就逊色不少。

MongoDB 是文档型DB, 可以以集群方式工作,很方便横向扩展,很适合做Event source, 每个事件可以做为一个文档, 但是基本弊端: 事务一致性, MongoDB事务是单个文档范围, 对于多个并发的事件不能保证事务一致性, 需要做些工作,而且对于事件源,需要保证读事件的顺序一致性, 而要做到这一点, MongoDB, 需要添加额外的索引来保证这一切,这些都需要额外的开支,在事件增加的情况下, 会带来更多的性能开销。

Kafka, Apache Kafka 是一个高性能、高扩展性在事件驱动领域是比较流行的解决方案, 他既提供消息的pipline, stream, 可提供存储; 但是做为event storage, 还是有点弊端, 一个是消息的存储事件有限制, 默认是168小时, 虽然这个可以该,但是这个不是kafka的本意, 如果滥用这一特征,可能会带来不必要的性能问题, 主要的问题还在, kafka 更是一个消息中间件, 存储消息不是他的本质工作, 而event 需要不定时的读取, 而且这些事件需要关联到某个聚合根(对象),kafka 里面的消息是按照topic 来分, 客户端是按照某个offset来读取,很难按照某个对象来过滤获取这些消息,所以虽然kafka 在存储的量,和事件的吞吐量上面有很多优势,但是还只适合做一个消息的broker, 不能做为一个event source.
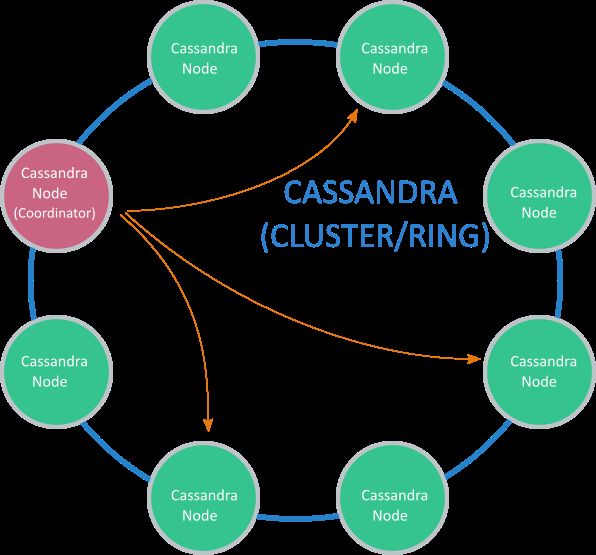
Cassandra 同样是Apache下项目, 是一个分布式高可用的DB, 通过在集群中保存多分复制来保证高可用性, 不需要指定特定的master, 这里Cassandra 可以更具用户的配置,来保证读写的一致性程度,一般使用quorum-based一致性来保证读写一致性, Cassandra, 在某种意义上可以满足我们Event source 中的高可用性, 一致性,事件发生的序列一致性, 需要依赖LWT(light weight transaction), LWT 的实现需要4(!) 4x3x2x1次在集群中协调实现写入操作(具体操作步骤笔者也不是了解太多),参考上面的问题,对事务的支持, 特别对多个管理事件的事务支持也有局限性。
可以看到现在市面上的种种解决方案都不能很好的满足我们的event source需求。现如今的这些通用的方式, 需要做适当的裁剪才能为event source 所用,鉴于上面我们描述的event source 的特质, 顺序的读写(append only),并发量大,基于这些特征, AxonIQ 推出来自己的event store 解决方案以保证高效的 store、 snapshot,、读、写、序列保证,AxonIQ event store, 只不过这个是商业的,做为框架外的独立模块。
方案
上面描述主要是AxonIQ, 选择解决方案的理由和过程, 不过我们没有使用他的产品AxonIQ Event store; 但是他们选择的标准和过程有不错的的参考价值。
对于一个交易系统,性能,高可用性,稳定性都是非常核心的元素, 实现性能也就是读写效率, 最好在内存操作; 高可用性需要做parittion 和replication。
内存中读写需要最终还是要落地,这里我们选择了apache 的ignite(下面会有更多的一篇独立讲解)。 过来事件保持一定的replicate(bakcup 2 ) 到cluster几点, 落地由ignite 批量输入到mysql. snapshot 也是以同样的方式。
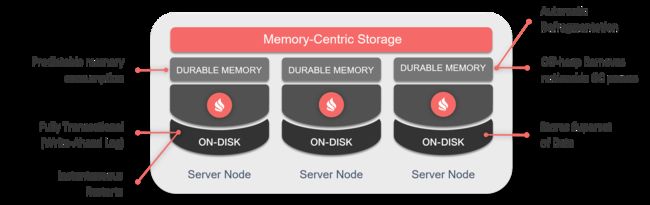
ignite 有自己的落地方案, 不一定需要一个关系数据库, 直接以自己的格式序列化到磁盘中,但是这部分功能缺乏基本的purge,archive,migrate 功能, 需要在商业版中才有, 所以现在只能放到传统的mysql db中。
ignite 天生的良好集群解决方案,可以很好的保证高可用性, 一般设置2~3 replicate指标、可以定制 replicate 策略:比如避免在Neighbors之间保持backup,能很好的保证高可用性; 落地端ignite 可以做update 的collapse, 当然对于event source,这个功能省掉了。
在具体的事件过程中有个比较麻烦的地方, axonframwork, 对于聚合根的状态, 做了个本地的缓存, 这对于性能的提升很有帮助, 但是对于集群节点,一旦集群节点的拓扑图变化掉后, 聚合根可能被shift 到另外一个节点,或者再回来, 这个时候本地的缓存是不可用的, 这个时候其实需要从, 上次snapshot 处,在根据后续事件来恢复, 所以一旦某个聚合根从某个节点shift出去, 必须删除本地的缓存,相当于本地的cache invalidate 掉。
为什么这个聚合根不保存到分布式缓存中呢? 对于更新频繁的聚合根, 比如book, 在每秒有5个左右的报价情况下(mass order 可能50个左右,对应撤单重下单+市场下撤单+上百个产品), 把庞大的聚合根每次更新都写入到分布式缓冲中,不太现实,我们做法是每过1024个版本, 才snapshot 一次(记得LMAX其实是一天做一次),所以仅仅在本地缓存, 是一个很好的权衡,这种情况下,一个聚合根从某个节点 shift出去, 再回来,本地的缓存不一致是比较严重的问题, 那么需要在集群reblance 时候, 根据自身节点partition变动, 清除下本地的缓存, 保证下次回来从event store 中恢复状态。
条条大道通罗马, 任何的技术框架、语言、解决方案等都不会只有一种,他们本质上没有太多的优劣之分, 适合自己的业务场景需要才是最好的, 这里需要权衡团队的接受能力, 学习维护的成本,最重要的还有ROI。
GoXTX 下一代交易平台技术供应商
GoXTX one-stop solution for neXT generation eXchange