论文题目:From Word Embeddings To Document Distances
作者:Matt J. Kusner, Yu Sun, Nicholas I. Kolkin, Kilian Q. Weinberger
文章发表于32届International Conference on Machine Learning.
1. 储备知识
1.1 Earth Mover's Distance
Earth Mover's Distance(EMD)是一种运输问题的优化算法,主要用于计算两个不同维度分布之间的距离。
参考资料如下:
- The Earth Mover's Distance
- 图像检索:EMD距离(Earth Mover's Distance)及纠错
- EMD距离(Earth Mover's Distance)
- The Earth Mover’s Distance as a Metric for Image Retrieval
- A Metric for Distributions with Applications to Image Databases
- Fast and Robust Earth Mover’s Distances
Fast and Robust Earth Mover’s Distances的算法是本文作者所采用的。
1.2 BOW和TF-IDF
1.2.1 Bag-of-words(BOW)
将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个词语都是独立的,例如下面两句话:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
就可以构成一个袋子,用一个字典来建立映射匹配:
{"Jane":1, "wants":2, "to":3, "go":4, "Shenzhen":5, "Bob":6, "Shanghai":7}
那么上面两个例句就可以用以下两个向量表示,对应的下标与映射数组的下标相匹配,其值为该词语出现的次数:
[1,1,2,1,1,0,0]
[0,1,2,1,0,1,1]
这两个词频向量就是词袋模型,可以很明显的看到语序关系已经完全丢失。
参考:词袋模型(BOW,bag of words)和词向量模型(Word Embedding)概念介绍
1.2.2 TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF(Term Frequence):
表示词条在文本中出现的频率:
其中,是该词在文件中出现的次数,分母则是文件中所有词汇出现的次数总和。
IDF(Inverse Document Frequence):
某一词条的IDF,可以由总文件数目除以包含该词语的文件的的数目,再将得到商取对数得到。如果包含该词条的文档越少,IDF越大,说明词条具有很好的类别区分能力。
其中,是语料库中文件的总数。表示包含词条的文件数目。一般分母+1,为了防止该词条不再语料库中而导致分母为0.
TF-IDF:
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF不足之处:
没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的;
按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词;
传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况;
对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
参考:
- TF-IDF算法介绍及实现
- TF-IDF原理及使用
2. 内容概述
在文档检索、新闻分类、多语言文档匹配等领域,精确计算文档距离具有重要的意义。
常用的模型有BOW和TF-IDF,但它们有如下缺点:
- 频率近似正交性(frequence near-orthogonality)( 不太懂,是因为矩阵中含有大量0的元素吗?);
- 不能很好描述个体单词之间的距离。
本文利用word2vec模型,提出了一种度量两个文档距离的方法Word Mover's Distance(WMD)。WMD的优化问题可归结为Earth Mover's Distance(EMD)问题的特例,而EMD问题有很好的现成solver。
同时,文章还讨论了几种下界(Lower bound),并提出了RWMD 下界。相比其他下界,RWMD具有更好的紧致性(tight)。
3. Word2Vec Embedding
Word2Vec是2013年由Mikolov等人提出的一个词向量计算工具。它通过一个浅层神经网络语言模型学得每个词的向量表达。
对于一组给定的单词序列,训练的目标是:
其中,是单词相邻单词集合。
该方法有两点优势:
- 训练高效:因为模型解构简单,同时使用层序softmax可以降低计算复杂度;
- 可以学得复杂词之间的关系。
4. Word Mover's Distance
4.1 WMD算法推导
在给出优化目标函数前,先解释几个定义:
假设用nBOW向量表示文档,, 定义
表示第个单词在文档中出现的频率,显然,是一个稀疏矩阵。
Word travel cost:
单词和单词之间的距离定义为:
Document distance:
这里定义文档距离用的就是Earth Mover's Distance的思想。
设矩阵,表示文档中有多少单词 travel 到 文档单词,明显,下列等式成立:
,
从而,定义文档间距离为:
Transportation problem:
文档和之间的最小转移距离可以表示为如下线性规划问题:
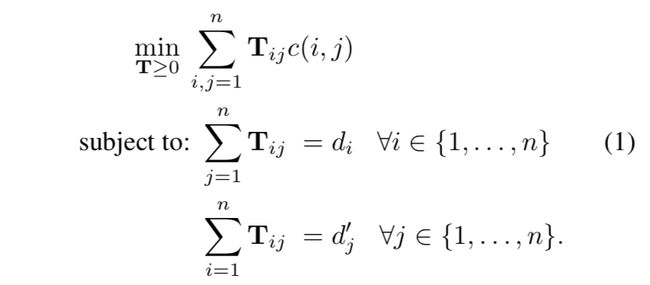
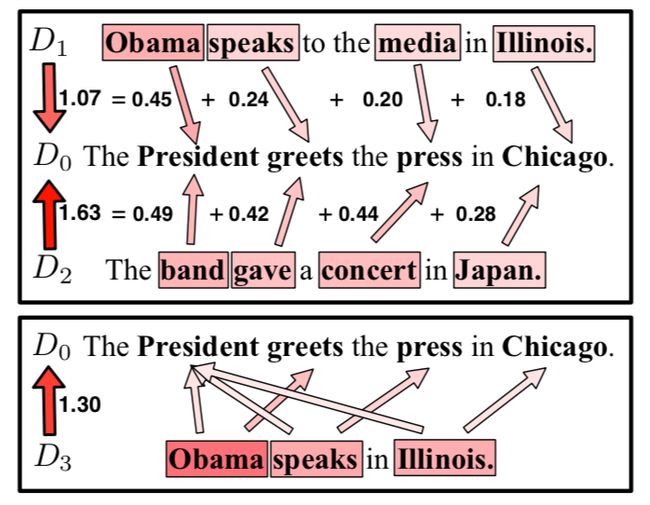
wmd距离示意图:
4.2 加速计算
WMD算法的最佳平均时间复杂度为,对于高维情况和大量文档,计算是非常耗时的。
作者提出了两种时间复杂度低的lower bound,可以初步过滤掉绝大多数不满足的文档,从而避免不必要的WMD距离计算。
Word centroid distance:
wcd下界的推导如下,其时间复杂度为:
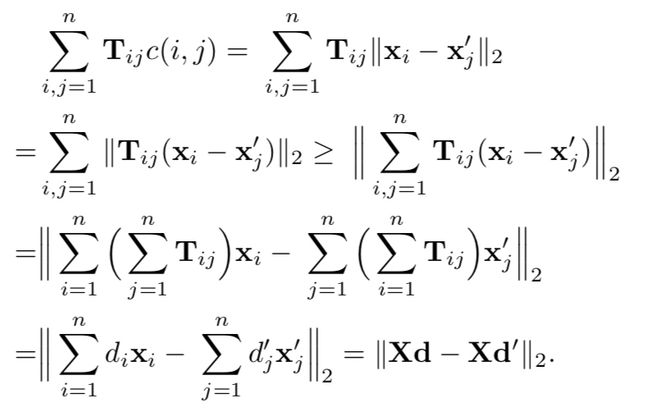
Relaxed word moving distance(RWMD):
wcd虽然计算速度很快,但是不够紧致(tight),作者提出了更加紧致(tighter)的RWMD下界:
就是在原问题的基础上,去掉一个约束条件:
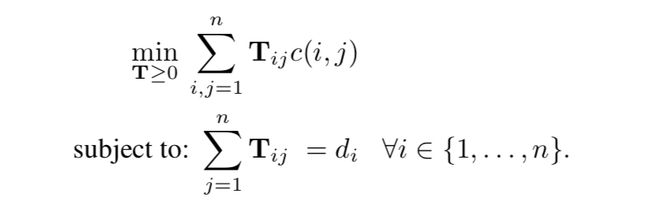
优化技巧是:

从而:
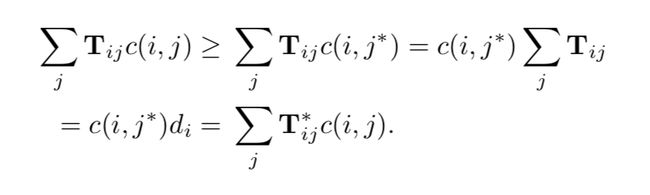
更进一步地,可以去掉另外一个约束,分布计算,取其较大者,作为下界:
4.3 计算工作流
- 利用WCD对文档进行排序,找到最相似的前个文档,这里可用KNN算法;
- 遍历留下的文档,计算RWMD,如果RWMD下界距离超过了当前第个最近文档的距离,则抛弃;否则计算WMD距离并更新;这一步,基本能过滤掉95%的文档;
5. 总结
- WMD错误率低的原因在于很好地利用了word2vec词向量;
- WMD具有很好的可解释性,文档距离可分解为词的距离,具有很好的可视化和解释性;
- WMD可以将文档结构和词距离一并考虑,通过添加罚项。