上海交大:基于近似随机Dropout的LSTM训练加速
机器之心发布
作者:宋卓然、王儒、茹栋宇、彭正皓、蒋力
上海交通大学
在这篇文章中,作者利用 Dropout 方法在神经网络训练过程中产生大量的稀疏性进行神经网络的训练加速。该论文已经被 Design Automation and Test in Europe Conference 2019 接收。
论文:Approximate Random Dropout for DNN training acceleration in GPGPU

论文链接:https://arxiv.org/abs/1805.08939
1. 简介
目前,有大量关于深度神经网络压缩的方法,利用神经网络的稀疏性通过如剪枝、正则化等方式使网络中的神经突触权值为零。
以剪枝(Pruning)[1] 为例,那些零权值经过编码后存在片上存储器中,由于零的位置很随机,需要在神经网络加速器中加入特殊的解码器来跳过那些涉及零操作数的运算。因此剪枝类方法仅使用 ASIC/FPGA 等平台;而且由于编码器解码器设计过于复杂,很少有加速器采用。
一些结构化稀疏性 [2] 的方法通过删除 CNN 中过滤器和通道来获得加速,比上述方法更加容易实现。然而,至今为止,很少有方法能利用神经网络的稀疏性来加速深度神经网络的训练过程。即使在分布式训练场景下,通过梯度压缩等方式可以减少通信带宽,但单 GPU 卡上的训练过程仍然难以有效加速。其主要原因是神经网络的训练过程涉及对权重的更新,不存在大规模的稀疏性。
本文利用了 Dropout 方法在神经网络训练过程中产生大量的稀疏性进行神经网络的训练加速。
Dropout 技术在网络训练中被用来防止过拟合。它会在每轮的训练过程中随机地临时删除部分神经元(30%-70%)及其相关连接。理论上来说,我们理应跳过(省去)Dropout 中被临时删除的神经元和神经突触的相关计算,从而加速训练过程。
然而,所有的训练框架(如 Caffe,Tensorflow,Pytortch 等)不约而同地忽视了这一点,保留了 Dropout 带来的冗余计算,仅仅在训练结果中掩盖(Mask)了被删除的神经元的结果。其主要原因是 Dropout 带来的冗余计算(删除的神经元和突触)的位置完全随机,GPU 这种单指令多线程架构(Single Instruction Multiple Thread)难以进行如此细粒度的控制。
因此,本文提出一种方法,在训练过程中在线产生有规律的结构化的 Dropout pattern,使 GPU 在其控制粒度上可以灵活地跳过 Dropout 带来的冗余计算。进一步,我们提出了一种 Dropout Pattern 的在线生成(搜索)算法,来补偿 Dropout 过程中随机性的损失。
我们在 MLP 及 LSTM 的训练任务中测试了我们的方法,在仅有细微精确度下降的情况下,取得了很高的加速比。具体而言,在 Dropout Rate 为 0.3 至 0.7 的情况下,MLP 训练过程加速了 30% 至 120%,LSTM 训练过程加速了 20% 至 60%。
2. Dropout 原理
目前应用最广泛的 Dropout 技术主要分为两种:Hinton et al. [3] 提出的单元 Dropout 和 Wan et al. [4] 提出的权值 Dropout。
单元 Dropout 会在每轮训练过程中随机删除神经元,因此它能降低单元之间的相互依赖关系,从而防止过拟合。权值 Dropout 在每一次更新中都会随机删除权值矩阵中的权值。
对于全连接层,假设输入向量为 I、权值矩阵为 W、输出向量为 Y、Mask 掩码 M 服从伯努利分布,那么可以定义上述两种方法分别为:
单元 Dropout:

权值 Dropout:
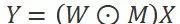
以单元 Dropout 为例,在每轮训练中每个神经元以一定概率被忽略,其实现方式为在矩阵上逐元素地与一个服从 Bernoulli 分布的 0-1 掩码矩阵相乘(如图 1(a)所示)。
如果想真正地跳过 Dropout 引入的冗余运算,就需要额外的 if-else 条件判断细粒度控制 GPU。然而,由于 GPU 的 SIMT(单指令多线程)特性,GPU 中的一些处理单元会处于空闲,GPU 的运算资源无法得到充分利用。
如图 1(b)所示,一条指令将同时控制 32 个线程的数据流,里面可能有判断为真的线程,也有判断为假的线程。一旦 GPU 沿着判断为真的指令流执行,那么所有的线程都会执行乘加运算。那些判断为假的线程的运算结果会被掩盖(masked)而不提交;GPU 会重新执行判断为假的指令流,那么所有线程会执行跳过计算。那些判断为真的线程结果被掩盖。两次执行结果最终通过 Mask 合并,提交给存储器。
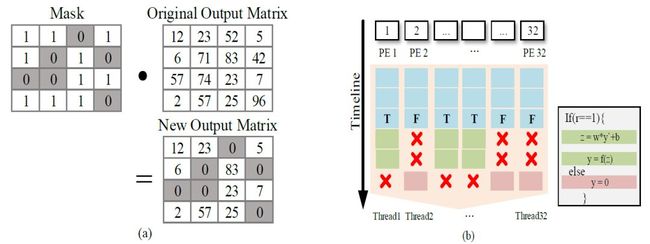
图 1(a)单元 Dropout 的实现过程;(b)直接避免单元 Dropout 带来的冗余计算时,GPU 出现 divergence 问题
这种现象在 SIMT 架构中被称为 Divergence,会带来额外性能的损失。正因为 SIMT 架构处理分支时的低效率,在主流的深度学习框架中都不对冗余计算进行跳过运算的处理。
3. 方法
本文定义了 Dropout Pattern 的概念。Dropout Pattern 为人为设计的有规律的和结构化的 Mask。若在计算时让 GPU 提前知晓哪些神经元或连接将会被 Drop,在实际计算过程中,我们通过告知 GPU 已经决定好的 Dropout Patten,让其不读取和计算被 Drop 的有关数据。以此来跳过冗余计算而不引起 Divergence。
下面我们先在 3.1 和 3.2 节介绍两类 Dropout Pattern。结构稀疏性必然导致 Dropout 的随机性受损,为此我们在 3.3 节介绍了一种产生关于 Dropout Pattern 的概率分布的算法,以此来保证随机性。在 3.4 节,我们证明了我们提出的近似随机 Dropout 与传统的随机 Dropout 在统计学意义上是等价的。
3.1 基于行的 Dropout Pattern——Row-based Dropout (RBD)
RDB 是近似传统的 Dropout 的一种 Pattern。它有规律的 drop 掉某些神经元,并以行为单位对权值矩阵进行有规律地删除,从而减小参与运算的矩阵大小。
我们定义两个结构参数 dp 和offset 来有规律地进行 Dropout。
dp 表示每隔 dp 行保留一行权值(每隔 dp 个神经元保留一个,其余的 drop 掉)。offset 表示当选定了 dp 后,从第 offset 行开始,按照每隔 dp 行保留一行的规律,执行删除权值的操作。
如图 2 所示,dp=3,offset=1,所以该矩阵从第一行开始每隔三行保留一行。在 DRAM 中保存了完整的权值矩阵,片上共享存储(shared memory)可以通过指定取数的规律将未被删除的行被取入,之后运算单元(PE)对取入的数据进行运算,达到加速的目的。从 GPU 的角度,基于行的 dropout pattern 有利于 GPU 索引数据,便于加速优化。值得注意的是,dp 和 offset 在每轮训练时都会变化,详见 3.3 节。
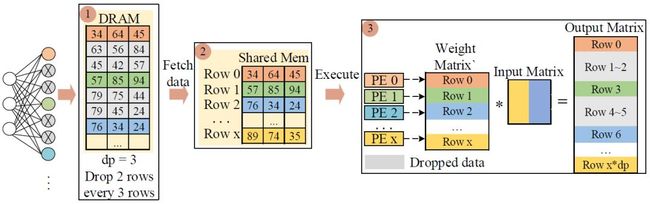
图 2 基于行的 dropout pattern
3.2 基于块的 dropout pattern——Tile-based Dropout (TBD)
TBD 以块为单位对权值矩阵进行删除,对应的神经元间的连接被忽略掉。类似 RBD,我们仍然定义两个结构参数 dp 和 offset。如图 3 所示,dp=4,offset=1,该矩阵从第一个块开始每隔三个块保留一个块。基于块的 dropout pattern 保证了数据的规律性,有助于对 GPU 进行优化加速。
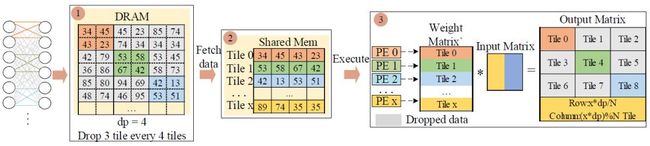
图 3 基于块的 dropout pattern
3.3 基于 SGD 的 Dropout Pattern 查找算法
首先,我们定义了 Global Dropout Rate,它在本文中指的是在一个训练迭代中有多少比例的神经元被 drop 了。其与在随机 Dropout 中指代每个神经元被 drop 的伯努利分布的概率有一些不同,但是我们证明了在我们的方法中 Global Dropout Rate 等价于每个神经元的 Dropout Rate。
其次,我们定义了一个向量,其中第 i 个元素为结构参数 dp=i 的 Dropout Pattern 中,被 drop 的神经元的比例,即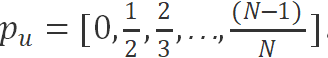 。因为在 Dropout Pattern 中每隔 dp 个神经元(或权重矩阵行向量/权重矩阵的块)保留一个,因此向量 p_u 的第 i 个元素为 (i-1) / i。
。因为在 Dropout Pattern 中每隔 dp 个神经元(或权重矩阵行向量/权重矩阵的块)保留一个,因此向量 p_u 的第 i 个元素为 (i-1) / i。
为了弥补引入 Dropout Pattern 后对 Dropout 随机性的损失,我们希望每次训练迭代中采用不同的结构参数(dp 和 offset)来产生更多的随机性,并尽可能地使每个神经元/突触被 drop 的概率等于原本随机 Dropout 时的概率。
为此,本文采用 SGD 梯度下降进行局部搜索来获取关于结构参数(dp)的概率密度函数。是一个向量,第 i 个元素表示 dp=i 的 Dropout Pattern 被选中的概率。
因此,为了使得 Global Dropout Rate 逼近随机 dropout 的 Dropout Rate:p,我们设置的 SGD 算法的一个 loss 函数为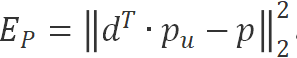 。式中 p 为算法的传入参数,表示我们希望的 Global Dropout Rate 是多少。
。式中 p 为算法的传入参数,表示我们希望的 Global Dropout Rate 是多少。
其次,为了使结构参数组合尽可能多元化,SGD 算法的另一个优化目标为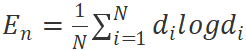 ,即概率分布的负信息熵。
,即概率分布的负信息熵。
为了同时实现上述两个优化目标,我们定义 SGD 的最终损失函数为![]() 。其中λ平衡因子。
。其中λ平衡因子。
3.4 统计学意义上的等价性
为了证明近似随机 Dropout 与传统的随机 Dropout 是从统计学的角度上等价的,我们给出了如下证明。
下式是使用近似随机 dropout 方案时,任意神经元被 Drop 的概率(即传统意义上的 Dropout Rate)。给定一个 Dropout Pattern,一个神经元被选中的概率为该 Dropout Pattern 被选中的概率与该神经元在该 Dropout Pattern 下被 Drop 的概率的乘积。根据全概率公式,对于所有的 Dropout Pattern 求和,得到每个神经元被 Drop 的概率:
![]()
另一方面,从全体上看被 Drop 的神经元所占的比例(即 Global Dropout Rate)为每个 Dropout Pattern(由结构参数 dp 决定)被选中的概率与该 Dropout Pattern 下被 Drop 的神经元的比例的乘积。由于 Dropout Pattern 分布概率的搜索算法会令,那么有 Global Dropout Rate:
![]()
可以看出,Global Dropout Rate 与单个神经元的 Dropout Rate 相等,且均等于我们 Dropout Pattern 概率分布生成算法的输入参数 p。因此,我们说我们的 Dropout 机制在整个训练过程中,在统计学意义上和随机 Dropout 机制是等价的。
4. 实验
我们将此方法运用在一个四层 MLP 网络的训练中,使用 MNIST 数据集测试该方法的性能。表 1 为实验结果,随着网络尺寸的增大,加速比逐渐提高。与传统方法相比,最高的加速比可达到 2.2X 左右。所有的准确率损失都保持在 0.5% 之内。
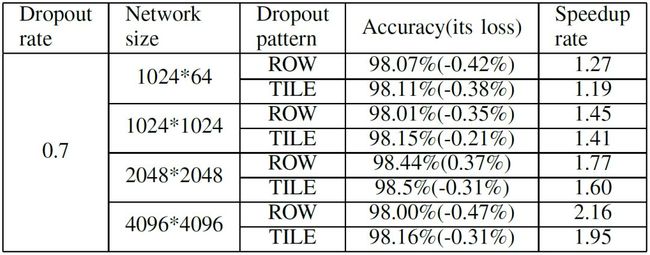
表 1 不同网络的准确率及加速比
我们还将此方法运用在 LSTM 的训练中,使用 Penn Treebank 数据集训练语言模型。图 4 为使用三层 LSTM+MLP 的实验结果。在 dropout rate 为 0.7 的情况下,RBD 下的 test perplexity 只增加了 0.04,训练速度加速了 1.6 倍,极大地降低了训练所消耗的时间。
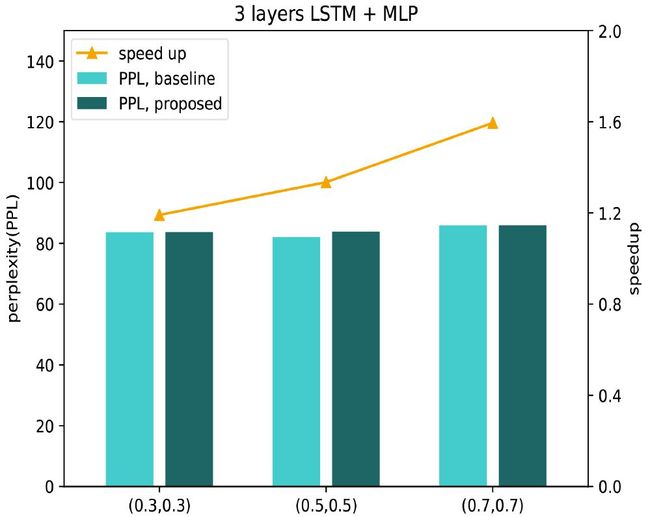
图 4 基于 PTB 数据集,LSTM 网络的准确率及加速比
5. 结语
我们提出了近似随机 Dropout 以替代传统的随机 Dropout。通过减小 DNN 训练中实际参与运算的参数与输入矩阵的尺寸,减少了 GPU 的运算量和数据搬移,从而达到加速 DNN 训练过程的目的。同时我们提出了基于 SGD 的 Dropout Pattern 搜索算法,使每个神经元的 dropout rate 近似的等于预设值,从而保证了准确率和收敛性。![]()
Reference
Han S, Mao H, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv:1510.00149, 2015.
Wen W, Wu C, Wang Y, et al. Learning structured sparsity in deep neural networks[C]. Advances in Neural Information Processing Systems. 2016: 2074-2082.
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhut- dinov,「Dropout: a simple way to prevent neural networks from overfit- ting,」Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929– 1958, 2014.
L. Wan, M. D. Zeiler, S. Zhang, Y. Lecun, and R. Fergus,「Regulariza- tion of neural networks using dropconnect,」in International Conference on Machine Learning, pp. 1058–1066, 2013.
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]