实体类的高级定义
假设我们有Student(学生),Classroom(班级)和MasterTeacher(班主任)三个类。他们之间的关系如下:
- 一个班级只有一个班主任
- 一个班级有多名学生
- 一个班主任只管理一个班级
- 一个班主任管理多名学生
- 一个学生只属于一个班级并且只有一个班主任
根据上面的需求,我们进行了如下的定义
联合主键
class Student(db.Entity):
"""学生"""
_table_ = "student"
name = Required(str, max_len=40)
master_teacher = Required("MasterTeacher") # 班主任
classroom = Required("Classroom") # 班级
class Classroom(db.Entity):
"""班级"""
_table_ = "classroom"
name = Required(str, max_len=40)
master_teacher = Optional("MasterTeacher") # 班主任
students = Set(Student) # 学生
class MasterTeacher(db.Entity):
"""班主任"""
_table_ = "master_teacher"
name = Required(str, max_len=40)
classroom = Required(Classroom) # 班级
students = Set(Student) # 学生
定义以后,有了一个新的问题:
有班主任同名的现象,这样单依赖名字就无法区别老师了,(比如三一班和三二班的班主任都叫张三)于是提出用老师的名字+班级 确认老师的唯一性,这个问题就解决了(三一班的张三老师和三二班的张三老师),这时候,我们就要用到联合主键了
不要在意上面的需求是否合理,我们提出上述假设的需求的目的只是为了演示一些pony的高级用法。
修改MasterTeacher类的定义
class MasterTeacher(db.Entity):
"""班主任"""
_table_ = "master_teacher"
name = Required(str, max_len=40)
classroom = Required(Classroom) # 班级
students = Set(Student) # 学生
PrimaryKey(name, classroom) # 定义一个联合主键
执行
db.generate_mapping(create_tables=True) # 生成实体,表和映射关系
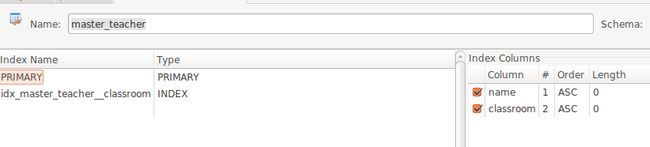
我们会发现数据库中的主键不再是id,而是name和classroom生成的联合主键了。
联合辅助键
如果你需要一个联合辅助键,那么只需要把PrimaryKey换成composite_key即可。
class MasterTeacher(db.Entity):
"""班主任"""
_table_ = "master_teacher"
name = Required(str, max_len=40)
classroom = Required(Classroom) # 班级
students = Set(Student) # 学生
composite_key(name, classroom) # 联合辅助键

观察数据库,你会发现master_teacher的主键依然是id,只是多个一个而是name和classroom生成的联合辅助键
联合索引
composite_index(name, classroom) # 联合索引
联合唯一索引
composite_key(name, classroom) # 联合唯一索引
属性定义
属性定义有很多参数,用于对字段进行约束或者验证。下面介绍一些常用的属性定义,注意,属性定义往往只在特定的字段类型上生效!
- max_len: (int), 字段长度,默认值:255,适用字段类型(str),max_len=40 ⇔ varchar(40)
- unique: (bool)唯一,默认值:False,适用字段类型(任意)
- auto: (bool)唯一,默认值:True,仅可用于PrimaryKey属性。
- autostrip: (bool)去掉字符串头尾的不可见字符,默认值:True,适用字段类型(str)
- column: (str)列名/字段名,默认值:属性名,可用于非Set属性。
- cascade_delete: (bool)级联删除,默认值:None,仅可用于外键属性。
- default: (numeric | str | functio)联默认值,没有默认值,注意,这个默认值的设置不会写入数据库的列定义中。
- index: (bool | str)允许控制此列的索引创建。index=True-将使用默认名称创建索引。index='index_name'-用指定名称创建索引。index=False–跳过索引创建,适用字段类型(任意)
- lazy: (bool)懒加载,默认值:True,适用字段类型(任意).加载对象时推迟加载属性值。除非您尝试直接访问此属性,否则不会加载该值。
- max: (numeric)最大值,默认值:无,适用字段类型(int,float,Decimal).设置允许的最大值。
- min: (numeric)最小值,默认值:无,适用字段类型(int,float,Decimal).设置允许的最小值。
- reverse: (str)反向引用,默认值:无,仅适用于关系映射字段.设置关系的另一端指定应用于关系的属性名称
- reverse_column: (str)反向引用的列名称,默认值:无,仅适用于多对多关系映射字段.设置中间表指定数据库列的名称。
- nullable: (bool)允许空值?,默认值:False,适用字段类型(任意).改字段是否允许为空?您很可能不需要指定此选项,因为Pony默认将其设置为最合适的值。
- unsigned: (bool)无符号?,默认值:False,适用字段类型(int,float,Decimal).字段是否有符号?是否区分正负,这影响字段的大小范围
- sql_type: (str)数据库类型,默认值:无,适用字段类型(任意)。设置列的特定SQL类型。
- table: (str)中间表的名称,默认值:pony默认,仅适用于多对多关系。指定中间表的名称。
- size: (int)反向引用,默认值:32,仅适用于int类型,指定应在数据库中使用的整数类型的大小。此参数接收应用于表示数据库中整数的位数。允许值为8、16、24、32和64,对于mysql:
- size=8 ⇔ TINYINT(4)
- size=16 ⇔ SMALLINT(6)
- size=24 ⇔ MEDIUMINT(9)
- size=32 ⇔ INT(11)
- size=64 ⇔ BIGINT(20)
连接查询
我们按照连接方式分为自然连接,左连接和右连接,我们分别就这3种连接进行示范和说明。
定义2个实体类,Boy和Girl,分别代表男孩和女孩。
- Tom和John是男孩
- Abby和Anna是女孩
- Tom和Abby是情侣
- John和Anna是单身
实体类代码如下:
class Girl(db.Entity):
name = Required(str, max_len=40) # 名字
lover = Optional("Boy", column="boy_id", nullable=True, default=None, reverse="lover") # 爱人
class Boy(db.Entity):
name = Required(str, max_len=40) # 名字
lover = Optional(Girl, nullable=True, default=None, reverse="lover") # 爱人
自然连接
把不是单身的小两口的名字打印出来。
with db_session(sql_debug=True):
query = select((x.name, x.lover.name) for x in Boy)
for x in query:
print(x)
sql_debug 你很容易发现多了一个参数,这个参数的目的就是为了在操作数据库时,把生成的语句打印出来,这样做的目的是: 一旦发现查询结果不对,我们可以参照打印出来的sql语句来判断自己的表达式是否拼写错误。
执行的结果是这样的
SELECT DISTINCT `x`.`name`, `girl`.`name`
FROM `boy` `x`, `girl` `girl`
WHERE `x`.`id` = `girl`.`boy_id`
('Tom', 'Abby')
COMMIT
RELEASE CONNECTION
Process finished with exit code 0
- SELECT DISTINCT
x.name,girl.nameFROMboyx,girlgirlWHEREx.id=girl.boy_id就是打印出来的sql语句。注意DISTINCT这个关键字,表示结果去重了。 - ('Tom', 'Abby') 查询结果,这个没什么好说的。
左连接
把所有的男孩子包括他们的情侣的名字打印出来。
with db_session(sql_debug=True):
query = left_join((x.name, x.lover.name) for x in Boy)
for x in query:
print(x)
执行的结果是这样的
GET NEW CONNECTION
SELECT DISTINCT `x`.`name`, `girl`.`name`
FROM `boy` `x`
LEFT JOIN `girl` `girl`
ON `x`.`id` = `girl`.`boy_id`
('Tom', 'Abby')
('John', None)
COMMIT
RELEASE CONNECTION
Process finished with exit code 0
- 注意语句中的左连接动词**LEFT JOIN **
- 查询结果中,没有女朋友的人的名字也打印出来了。
右连接
pony中没有提供右连接方法,如果需要类似的功能,你需要把查询的对象反过来即可。
把所有的女孩子包括他们的情侣的名字打印出来。
with db_session(sql_debug=True):
query = left_join((x.name, x.lover.name) for x in Girl)
for x in query:
print(x)
查询结果
GET NEW CONNECTION
SELECT DISTINCT `x`.`name`, `boy`.`name`
FROM `girl` `x`
LEFT JOIN `boy` `boy`
ON `x`.`boy_id` = `boy`.`id`
('Abby', 'Tom')
('Anna', None)
COMMIT
RELEASE CONNECTION
Process finished with exit code 0
查询实例
下面我们使用例子来说明一些常用的查询函数的使用方法
实体类Worker的定义如下:
from decimal import Decimal
class Worker(db.Entity):
"""工人"""
name = Required(str, max_len=40) # 名字
sex = Required(str, max_len=16) # 性别
age = Required(int, size=8) # 年龄
salary = Required(Decimal) # 月薪
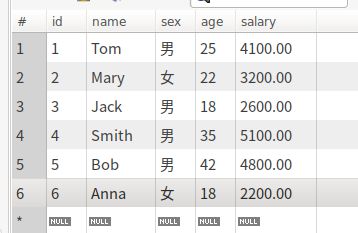
表中有如下数据
条件查询
- 查询年龄大于等于22小于等于35的男性工人。
with db_session:
query = select(x for x in Worker if between(x.age, 22, 35) and x.sex == "男")
for x in query:
print(x.to_dict())
- 查询年龄大于30岁的工人的平均工资。
with db_session:
query = avg(x.salary for x in Worker if x.age > 30)
print(query)
- 查询年龄大于30岁的工人的最高/最低工资。
max(x.salary for x in Worker if x.age > 30)
min(x.salary for x in Worker if x.age > 30)
- 统计年龄大于30岁的工人的人数
count(x for x in Worker if x.age > 30)
或者
select(x.salary for x in Worker if x.age > 30).count()
- 以年龄大小正/倒序查询工人信息
select(x for x in Worker).order_by(lambda x: x.age)
select(x for x in Worker).order_by(lambda x: desc(x.age))
或者
select(x for x in Worker).order_by(Worker.age)
select(x for x in Worker).order_by(desc(Worker.age))
或者
select(x for x in Worker).order_by("x.age")
select(x for x in Worker).order_by(desc("x.age"))
- 先以年龄倒序排列,如果年龄相同,就以月薪倒序排列,也就是我们平时说的多重排序
select(x for x in Worker).order_by(desc(Worker.age)).order_by(desc(Worker.salary))
- 分页查询
select(x for x in Worker).page(pagenum=1, pagesize=2)
- 根据年龄正序排列,限制输出前3个。
select(x for x in Worker).order_by(desc(Worker.age)).limit(3)
或者
select(x for x in Worker).order_by(desc(Worker.age))[:3]
不要以为第二种方法是先查询出来全部数据再对结果进行切片的,pony明白操作者的意图,会对sql语句进行优化。实际上两种方式生成的sql语句是一模一样的
SELECTx.id,x.name,x.sex,x.age,x.salary
FROMworkerx
ORDER BYx.ageDESC LIMIT 3
- 统计所有工人的工资之和
sum(x.salary for x in Worker)
- 计算平均工资
avg(x.salary for x in Worker)
或者
select(x.salary for x in Worker).avg()
- 查询名字以T开头的工人
select(x for x in Worker).where(lambda x: x.name.startswith("T"))
- 查询名字以a结束的工人
select(x for x in Worker).where(lambda x: x.name.endswith("a"))
- 查询名字中有m这个字母的工人
select(x for x in Worker).where(lambda x: "m" in x.name)
- 使用原生语句查询
select(x for x in Worker).where(lambda x: raw_sql("x.name = 'Tom'"))
- Python的魔法ORM --《PonyORM教程》 1.连接,声明和查询
- Python的魔法ORM --《PonyORM教程》 2 实体关系
- Python的魔法ORM --《PonyORM教程》 3 实体继承
- Python的魔法ORM --《PonyORM教程》 4 高级定义和连接查询