R语言机器学习项目——客户信用预测(随机森林算法)
信用风险预测
应用背景:银行中可能存在有信用风险的客户,通过以往积累的一些数据(包括贷款情况、家庭信息、工作等信息)描述客户特征,并与客户信用情况建立关联
使用算法:随机决策森林(在对特征信息进行初步分析处理后,用随机森林算法得到最优特征建立模型)
一:分析客户特征
- Utils.R文件中存放函数用于分析以及可视化数值型特征、因子型特征。
Credit_analysis.R分析客户特征:客户信用评级credit_rating: 1为有信用;0为缺乏信用
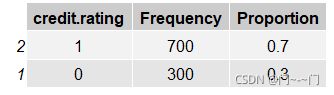
分析特征balance:账户余额
1:没有银行账户
2:账户没有余额
3: 账户余额
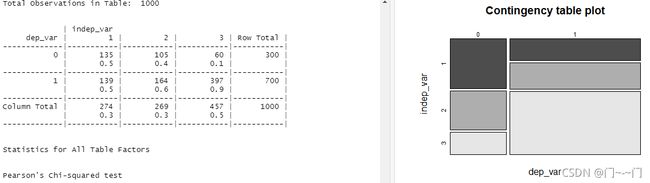
用列联表查看balance与rating的关系并可视化后,发现二者有关联
分析特征months:贷款月数(客户欠款时间的中位数高的,信用更差)

分析特征previous_payment:过去的贷款偿付情况(1表示偿贷有问题)
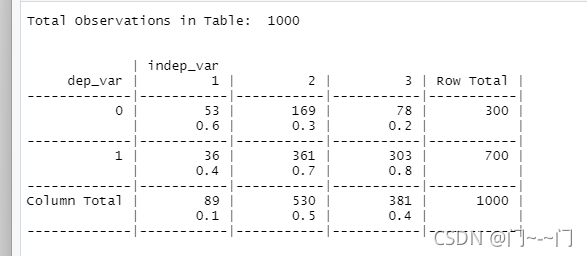
有上面的列联表可以看出偿贷有问题的客户更可能有信用问题
分析特征purpose:贷款用途(1.买新车2.买二手车3.买家庭用品4.其他)
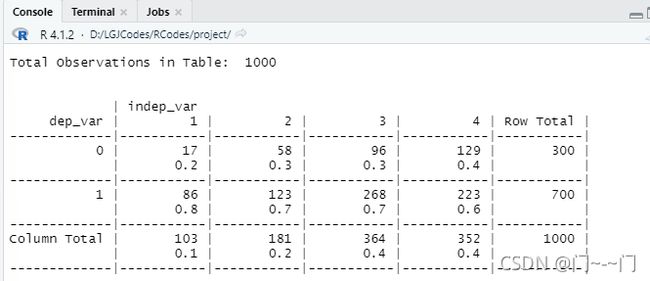
可以看出用于买家庭用品和其他用途的客户信用相对较差,但并不是特别明显
分析特征credit_amount:贷款额
由下图看出信用较差的客户贷款的金额相对更高

分析特征savings:存款(1:没有存款)

从列联表中可以看出没有存款的客户的信用情况更差
……对所有特征分析处理后,将变换后的特征数据集保存为credit_dataset_afterP.csv
二:将处理后的数据集分为训练样例与测试样例
# 按6:4将数据分成训练数据集和测试数据集
indexes <- sample(1:nrow(credit.df), size=0.6*nrow(credit.df))
train.data <- credit.df[indexes,]
test.data <- credit.df[-indexes,]Data_separation.R : 将1000个样例按照6:4拆分,分别用于训练与测试
三:选择特征
feature_selection.R
library(caret)
library(randomForest)
#选择特征
run.feature.selection <- function(num.iters=20, feature.vars, class.var){
set.seed(10)
variable.sizes <- 1:10
control <- rfeControl(functions = rfFuncs, method = "cv",
verbose = FALSE, returnResamp = "all",
number = num.iters)
results.rfe <- rfe(x = feature.vars, y = class.var,
sizes = variable.sizes,
rfeControl = control)
return(results.rfe)
}
rfe.results <- run.feature.selection(feature.vars=train.data[,-1],
class.var=train.data[,1])
rfe.results
用递归特征排除法选择特征,用随机森林算法进行模型评估,结果如下:
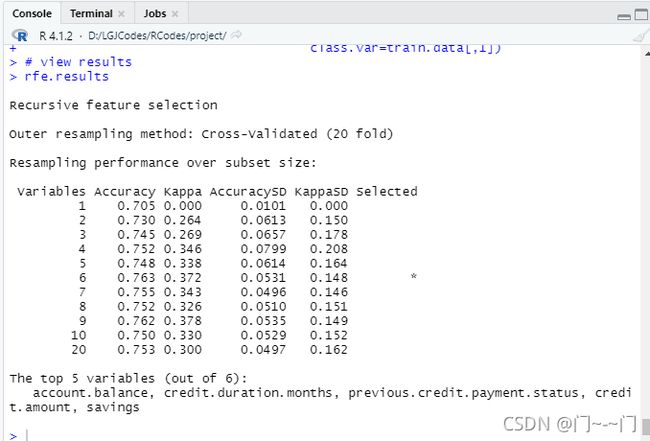
选取出五个特征:account.balance 账户余额,savings银行存款,credit.amount贷款金额,credit.duration.months贷款时长(月数) ,previous.credit.payment.statu(偿贷情况)
四、构建random-forest模型
Random_Forest_Predict.R
使用选取的五个最优特征建模:
## 使用选取的五个特征
formula.new <- "credit.rating ~ account.balance + savings +
credit.amount + credit.duration.months +
previous.credit.payment.status"
formula.new <- as.formula(formula.new)
rf.model.new <- randomForest(formula.new, data = train.data,
importance=T, proximity=T)
## 建模预测
rf.predictions.new <- predict(rf.model.new, test.feature.vars, type="class")
confusionMatrix(data=rf.predictions.new, reference=test.class.var, positive="1")
使用测试数据集对模型进行预测和评估发现:
准确率为74%;特异性为37.4%;灵敏度为90.3%。说明该模型能够较好的预测信用评级差的客户。