转自https://www.cnblogs.com/cobbliu/archive/2013/03/02/2940074.html
从protobuf如何将特定结构体序列化为二进制流的角度,看看为什么Protobuf如此之快;
一、示例
从例子入手是学习一门新工具的最佳方法。下面我们通过一个简单的例子看看我们如何用protobuf的C++接口序列化反序列化一个结构体。
1.编辑将要序列化的结构体描述文件Hello.proto
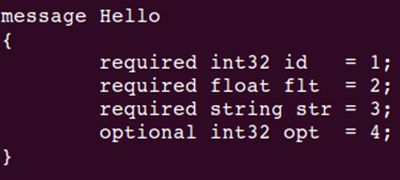
每个结构体必须用message来描述,其中的每个字段的修饰符有required, repeated和optional三种,required表示该字段是必须的,repeated表示该字段可以重复出现,它描述的字段可以看做C语言中的数组,optional表示该字段可有可无。
同时,必须人为地为每个字段赋予一个标号field_number,如上图中的1,2,3,4所示。更详细的proto文件的编写规则见这里。
2.用protoc工具“编译”Hello.proto
protoc工具使用的一般格式是:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto
其中SRC_DIR是proto文件所在的目录,DST_DIR是编译proto文件后生成的结构体处理文件的目录
之后会生成对结构体Hello.proto中描述的各字段做序列化反序列化的类
3.编写序列化进程write.cc
Hello msg;
msg.set_id(101);
msg.set_flt(13.14);
msg.set_str("hello");
fstream output("./log",ios::out | ios::trunc | ios::binary);
if(!msg.SerializeToOstream(&output)){
cerr<<"Failed to write msg."<我们用set方法为结构体中的每个成员赋值,然后调用SerializeToOstream将结构体序列化到文件log中。
并编译它:
4,编写反序列化进程reader.cc
void listMsg(const Hello& msg)
{
cout<用ParseFromIstream将文件中的内容序列化到类Hello的对象msg中。
并编译它:
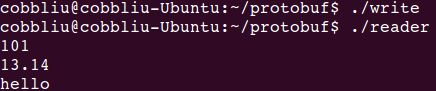
5.做序列化和反序列化操作
二、protocol buffer的数据类型
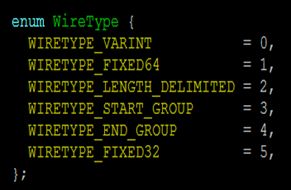
从第一节中的例子可以看出,用Protocol buffer时需要用户自定义自己的结构体,而且结构体中的定义规则要符合google制定的规则。结构体中每个字段都需要一个数据类型,protocol buffer支持的数据类型在源代码wire_format_lite.h中定义:
其中:
VARINT类数据表示要用variant编码对所传入的数据做压缩存储,variant编码细节见下一节。
FIXED32和FIXED64类数据不对用户传入的数据做variant压缩存储,只存储原始数据。
LENGTH_DELIMITED类数据主要针对string类型、repeated类型和嵌套类型,对这些类型编码时 ++ 需要存储他们的长度信息 ++ 。
START_GROUP是一个组(该组可以是嵌套类型,也可以是repeated类型)的开始标志。
END_GROUP是一个组(该组可以是嵌套类型,也可以是repeated类型)的结束标志。
每类数据包含的具体数据类型如下表所示:
| WireType | 表示类型 |
|---|---|
| VARINT | int32,int64,uint32,uint64,sint32,sint64,bool,enum |
| FIXED64 | fixed64,sfixed64,double |
| LENGTH_DELIMITED | string,bytes,embedded messages, packed repeadted field |
| START_GROUP | group的开始标志 |
| END_GROUP | group的结束标志 |
| FIXED32 | fixed32,sfixed32,float |
三、protocol buffer的编码
ProtocolBuffer的编码是尽其所能地将字段的元信息和字段的值压缩存储,并且字段的元信息中含有对这个字段描述的所有信息。
整个结构体序列化后抽象地看起来像下图这样:

可以看到,整个消息是以二进制流的方式存储,在这个二进制流中,逐个字段以定义的顺序仅仅相邻。每个字段中由元信息tag和字段的值value组成。
其中tag是这样编码的:
field_number << 3 | wire_tye- 对上面得到的无符号类型整数做variant编码
其中field_number第一节中提到的每个字段的标号,wire_type是第二节中提到的该字段的数据类型。
1. virant编码
variant编码是一种紧凑型数字编码,将元数据跟数字保存在一起,如下图所示是数字131415的variant编码:
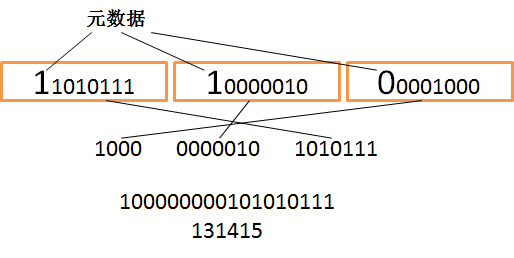
其中第一个字节的高位msb(Most Significant Bit)为1表示下一个字节还有有效数据,msb为0表示该字节中的后7位是最后一组有效数字。剃掉最高位的有效位组成真正的数字。
从上面可以看出,variant编码存储比较小的整数时很节省空间,小于等于127的数字可以用一个字节存储。但缺点是对于大于268,435,455(0xfffffff)的整数需要5个字节来存储。
对一个整数的variant编码的代码位于./src/google/protobuf/io/coded_stream.cc:WriteVarint32FallbackToArrayInline()函数中,摘录如下:
inline uint8* CodedOutputStream::WriteVarint32FallbackToArrayInline(
uint32 value, uint8* target) {
target[0] = static_cast(value | 0x80);
if (value >= (1 << 7)) {
target[1] = static_cast((value >> 7) | 0x80);
if (value >= (1 << 14)) {
target[2] = static_cast((value >> 14) | 0x80);
if (value >= (1 << 21)) {
target[3] = static_cast((value >> 21) | 0x80);
if (value >= (1 << 28)) {
target[4] = static_cast(value >> 28);
return target + 5;
} else {
target[3] &= 0x7F;
return target + 4;
}
} else {
target[2] &= 0x7F;
return target + 3;
}
} else {
target[1] &= 0x7F;
return target + 2;
}
} else {
target[0] &= 0x7F;
return target + 1;
}
}
整个结构体的序列化过程如下:
a. 调用Hello类的ByteSize()计算出序列化后的长度,分配该长度的空间,以备以后将每个字段填充到该空间中,示例中的长度计算公式是:
1+int32Size()+1+4+1+StringSize()
b. 调用Hello类的SerializeWithCachedSizes()对每个元素序列化
下面是对每一类元素的序列化编码详解:
2. int32/int64/uint32/uint64类型的编码
a. 计算长度 1+int32size(值);
b. 调用WireFormatLite::WriteInt32(...)将该字段的元信息和字段值写入到新空间中:

例如用户为int32传入值123,则该字段的存储如下:
第一个字节variant(1<<3|0)第二个字节variant(123)
3.String类型的编码
a. 计算长度 1 + variant(stringLength)+stringLength
b. 调用WireFormatLite::WriteString(…)将该字段的元信息、长度和值写入到新空间中

4. float类型的编码
a. 计算长度1+4
b. 调用WireFormatLite::WriteFloat(...)将该字段的元信息和值写入到新空间中

其中写float内存拷贝的代码非常精炼:
inline float WireFormatLite::DecodeFloat(uint32 value) {
union {float f; uint32 i;};
i = value;
return f;
}
5. 嵌套结构体编码
a. 计算长度 1+variant32(embedded长度)+embedded的长度
b. 调用WireFormatLite::WriteMessageMaybeToArray(…)将该字段的元信息、长度和值写入到新空间中

6. repeated类型字段编码
a. 计算长度 1*repeated个数 + variant32(repeated长度)+repeated长度
b. 调用WireFormatLite::WriteMessageMaybeToArray(…)将下图所示编码的值写入到新空间中

7. sint32,sint64类型字段编码
从int32编码中可以看出,当int32传入-1时所消耗的空间很大,所以结构体定义中引入了sint32和sint64类型的数据,这种数据采用一种叫zigzag的编码方式,使绝对值比较小的整数也占用比较小的字节。
zigzag编码的映射关系图如下:

它将原始类型为int32的数用uint32的数表示,当一个数的绝对值比较小时,将其用uint32表示,再采用variant编码存储就会比较节省空间。
对一个整数的zigzag编码也很巧妙:
inline uint32 WireFormatLite::ZigZagEncode32(int32 n) {
// Note: the right-shift must be arithmetic
return (n << 1) ^ (n >> 31);
}
总结
从上面的编码可以看出, protocol buffer压榨每一个没有真正用到的字节,使之序列化后的字节尽量少,清晰的数据编码和诸多的位操作使之变得很轻便简洁高效。同时它提供了很多编程语言的接口,可以广泛应用于RPC系统中。
但是,由于它将元信息编码到二进制位中,使得序列化后的数据可读性非常差(其实是没有可读性)。