HDFS 2.0 的 HA 实现
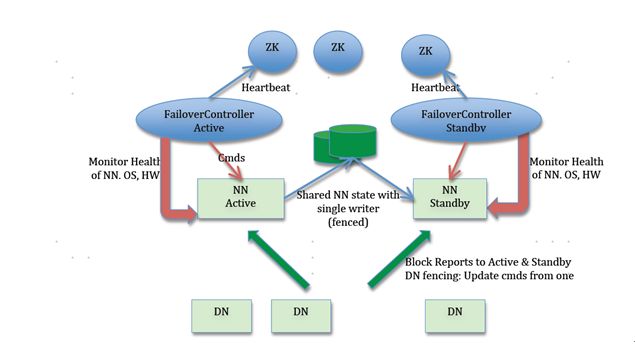
- Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
- 主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
- Zookeeper 集群:为主备切换控制器提供主备选举支持。
- 共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主 NameNode 和备NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
- DataNode 节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
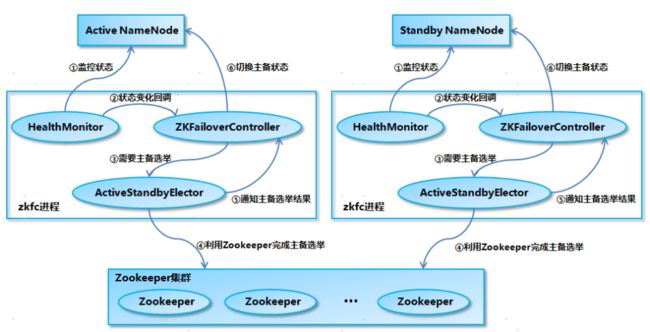
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现:
ZKFailoverController 作为 NameNode 机器上一个独立的进程启动 (在 hdfs 启动脚本之中的进程名为 zkfc),启动的时候会创建 HealthMonitor 和 ActiveStandbyElector 这两个主要的内部组件,ZKFailoverController 在创建 HealthMonitor 和 ActiveStandbyElector 的同时,也会向 HealthMonitor 和 ActiveStandbyElector 注册相应的回调方法。
- HealthMonitor 主要负责检测 NameNode 的健康状态,如果检测到 NameNode 的状态发生变化,会回调 ZKFailoverController 的相应方法进行自动的主备选举。
- ActiveStandbyElector 主要负责完成自动的主备选举,内部封装了 Zookeeper 的处理逻辑,一旦 Zookeeper 主备选举完成,会回调 ZKFailoverController 的相应方法来进行 NameNode 的主备状态切换。
NameNode 实现主备切换有以下几步:
- HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
- HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
- 如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
- ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
- ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
-
ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
 主备切换
主备切换
防止脑裂
Zookeeper 在工程实践的过程中经常会发生的一个现象就是 Zookeeper 客户端“假死”,所谓的“假死”是指如果 Zookeeper 客户端机器负载过高或者正在进行 JVM Full GC,那么可能会导致 Zookeeper 客户端到 Zookeeper 服务端的心跳不能正常发出,一旦这个时间持续较长,超过了配置的 Zookeeper Session Timeout 参数的话,Zookeeper 服务端就会认为客户端的 session 已经过期从而将客户端的 Session 关闭。“假死”有可能引起分布式系统常说的双主或脑裂 (brain-split) 现象。具体到本文所述的 NameNode,假设 NameNode1 当前为 Active 状态,NameNode2 当前为 Standby 状态。如果某一时刻 NameNode1 对应的 ZKFailoverController 进程发生了“假死”现象,那么 Zookeeper 服务端会认为 NameNode1 挂掉了,根据前面的主备切换逻辑,NameNode2 会替代 NameNode1 进入 Active 状态。但是此时 NameNode1 可能仍然处于 Active 状态正常运行,即使随后 NameNode1 对应的 ZKFailoverController 因为负载下降或者 Full GC 结束而恢复了正常,感知到自己和 Zookeeper 的 Session 已经关闭,但是由于网络的延迟以及 CPU 线程调度的不确定性,仍然有可能会在接下来的一段时间窗口内 NameNode1 认为自己还是处于 Active 状态。这样 NameNode1 和 NameNode2 都处于 Active 状态,都可以对外提供服务。这种情况对于 NameNode 这类对数据一致性要求非常高的系统来说是灾难性的,数据会发生错乱且无法恢复。Zookeeper 社区对这种问题的解决方法叫做 fencing,中文翻译为隔离,也就是想办法把旧的 Active NameNode 隔离起来,使它不能正常对外提供服务。
ActiveStandbyElector 为了实现 fencing,会在成功创建 Zookeeper 节点
hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 从而成为 Active NameNode 之后,创建另外一个路径为/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息。Active NameNode 的 ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候 (注意由于/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 是临时节点,也会随之删除),会一起删除节点/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb。但是如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如前述的 Zookeeper 假死),那么由于/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行 fencing。
基于 QJM 的共享存储系统的总体架构
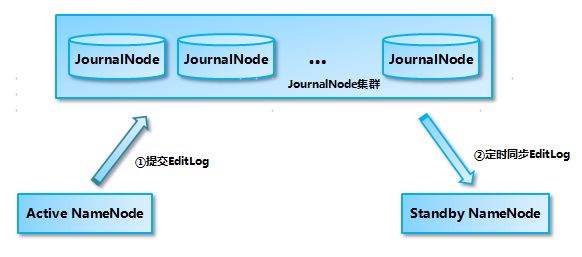
基于 QJM 的共享存储系统主要用于保存 EditLog,并不保存 FSImage 文件。FSImage 文件还是在 NameNode 的本地磁盘上。QJM 共享存储的基本思想来自于 Paxos 算法,采用多个称为 JournalNode 的节点组成的 JournalNode 集群来存储 EditLog。每个 JournalNode 保存同样的 EditLog 副本。每次 NameNode 写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向 JournalNode 集群之中的每一个 JournalNode 发送写请求,只要大多数 (majority) 的 JournalNode 节点返回成功就认为向 JournalNode 集群写入 EditLog 成功。如果有 2N+1 台 JournalNode,那么根据大多数的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
Active NameNode 和 StandbyNameNode 使用 JouranlNode 集群来进行数据同步的过程如图所示,Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog:
数据恢复机制分析
处于 Standby 状态的 NameNode 转换为 Active 状态的时候,有可能上一个 Active NameNode 发生了异常退出,那么 JournalNode 集群中各个 JournalNode 上的 EditLog 就可能会处于不一致的状态,所以首先要做的事情就是让 JournalNode 集群中各个节点上的 EditLog 恢复为一致。另外如前所述,当前处于 Standby 状态的 NameNode 的内存中的文件系统镜像有很大的可能是落后于旧的 Active NameNode 的,所以在 JournalNode 集群中各个节点上的 EditLog 达成一致之后,接下来要做的事情就是从 JournalNode 集群上补齐落后的 EditLog。只有在这两步完成之后,当前新的 Active NameNode 才能安全地对外提供服务。
HDFS 2.0 Federation 实现
在 1.0 中,HDFS 的架构设计有以下缺点:
- namespace 扩展性差:在单一的 NN 情况下,因为所有 namespace 数据都需要加载到内存,所以物理机内存的大小限制了整个 HDFS 能够容纳文件的最大个数(namespace 指的是 HDFS 中树形目录和文件结构以及文件对应的 block 信息);
- 性能可扩展性差:由于所有请求都需要经过 NN,单一 NN 导致所有请求都由一台机器进行处理,很容易达到单台机器的吞吐;
- 隔离性差:多租户的情况下,单一 NN 的架构无法在租户间进行隔离,会造成不可避免的相互影响。
而 Federation 的设计就是为了解决这些问题,采用 Federation 的最主要原因是设计实现简单,而且还能解决问题。
Federation 的核心设计思想
Federation 的核心思想是将一个大的 namespace 划分多个子 namespace,并且每个 namespace 分别由单独的 NameNode 负责,这些 NameNode 之间互相独立,不会影响,不需要做任何协调工作(其实跟拆集群有一些相似),集群的所有 DataNode 会被多个 NameNode 共享。
其中,每个子 namespace 和 DataNode 之间会由数据块管理层作为中介建立映射关系。