1. 简称
论文《Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning》简称DDQ,作者Baolin Peng(Microsoft Research),经典的对话策略学习论文。
2. 摘要
通过强化学习(RL)训练任务完成对话代理代价高昂,因为它需要与真实用户进行许多交互。
一种常见的替代方案是使用用户模拟器。然而,用户模拟器通常缺乏人类对话者的语言复杂性,并且其设计中的偏差可能倾向于降低代理。
为了解决这些问题,我们提出了Deep Dyna-Q,据我们所知,它是第一个深度RL框架,它集成了任务完成对话策略学习的规划。我们将环境模型(称为世界模型)合并到对话代理中,以模拟真实的用户响应并生成模拟体验。
在对话策略学习过程中,世界模型不断使用真实用户体验进行更新,以接近真实用户行为,并且反过来,对话代理使用真实体验和模拟体验进行优化。我们的方法在模拟和人设置下的电影票预订任务上得到了证明。
3. 引言
任务完成对话的学习策略通常被定为强化学习(RL)问题。但是,由于RL学习者需要一个操作环境,因此将RL应用于现实世界的对话系统可能具有挑战性。

在对话设置中,这需要对话代理与真实用户进行交互并进行调整以在线方式执行其策略,如图1(a)所示。
通过这种方式,对话代理可以通过与模拟器而不是真实用户进行交互来学习其策略(图1(b))。从理论上讲,模拟器不会产生任何现实成本,并且可以为强化学习提供无限的模拟体验。然后,可以将使用这种用户模拟器训练的对话代理部署到实际用户,并仅通过少量人机交互来进一步增强对话代理。
在对话策略学习过程中,真实用户体验扮演着两个关键角色:首先,它可以用于通过监督学习来改善世界模型,使其行为更像真实用户。其次,它也可以用于通过RL直接改善对话政策。前者称为世界模型学习,后者称为直接强化学习。可以直接使用实际经验(即直接强化学习)或通过间接世界模型(称为计划或间接强化学习)来改善对话策略。在Dyna-Q框架之后,图1(c)中说明了世界模型学习,直接强化学习和规划之间的相互作用。
我们通过将Dyna-Q与深度学习方法相结合来提出Deep Dyna-Q(DDQ),以通过神经网络(NN)表示状态-动作空间。
为此,我们在这项工作中的主要贡献有两个方面:
- 我们展示了Deep Dyna-Q,据我们所知,这是第一个结合了任务完成对话策略学习计划的深度RL框架。
- 我们证明,通过RL与实际用户进行交互,任务完成对话代理可以有效地动态调整其策略。这样可以显着提高非平凡任务的成功率。
4. 核心
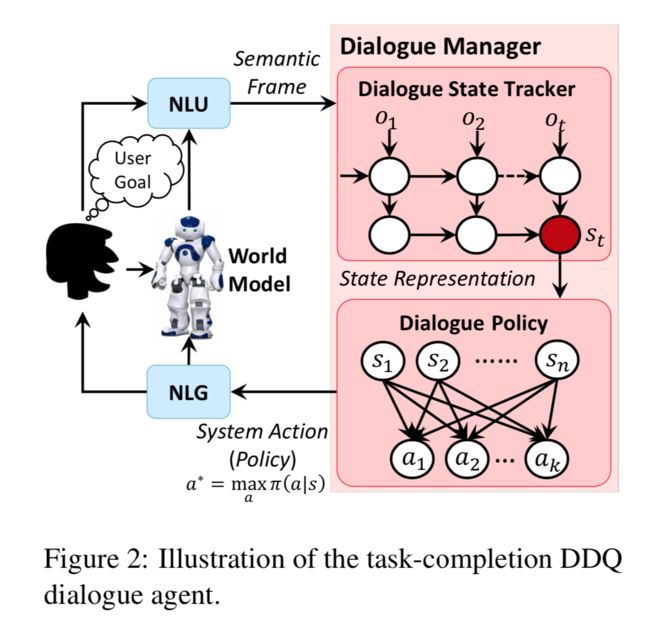
我们的DDQ对话代理如图2所示,由五个模块组成:(1)基于LSTM的自然语言理解(NLU)模块,用于识别用户意图并提取相关的槽;(2)状态跟踪器,用于跟踪对话状态;(3)基于当前状态选择下一个动作的对话策略;(4)用于将对话动作转换为自然语言响应的基于模型的自然语言生成(NLG)模块;以及(5)用于生成模拟用户动作和模拟奖励的世界模型。
如图1(c)所示,从初始对话策略和初始世界模型(都使用预先收集的人类会话数据进行训练)开始,DDQ代理的训练包括三个过程:(1)代理与真实用户互动,收集真实经验并改善对话策略的直接强化学习; (2)世界模型学习,其中使用实际经验来学习和完善世界模型; (3)规划,代理人利用模拟经验改进对话政策。
尽管这三个过程在概念上可以在DDQ代理中同时发生,但是我们实现了迭代训练过程,如算法1所示,我们在其中指定了它们在每次迭代中发生的顺序。接下来,我们将详细描述这些过程。

4.1 Direct Reinforcement Learning
在这个过程中(算法1中的第5-18行),我们使用DQN方法(Mnih等人,2015)来改进基于实际经验的对话策略。我们将任务完成对话视为一个马尔可夫决策过程(MDP),其中代理与用户在一系列操作中相互作用,以实现用户目标。
在每个步骤中,代理观察对话状态,并使用贪婪策略选择概率为的随机动作或否则遵循贪婪策略来选择要执行的动作。是近似值函数,实现为由参数化的多层感知器(MLP)。然后,代理接收奖励(在对话场景中,奖励被定义为衡量对话成功的程度。例如,在我们的实验中,成功对应于80的奖励,失败对应于-40的奖励,并且代理人每回合都会收到-1的奖励,以鼓励较短的对话。),观察下一个用户响应,并将状态更新为。最后,我们将经验存储在重放缓冲区中。循环一直持续到对话终止。
我们通过调整以最小化均方损失函数来改善值函数,定义如下:
其中是折扣因子,并且是仅定期更新的目标值函数(算法1中的第42行)。通过将损失函数相对于进行微分,我们得出以下梯度:
如算法1的第16-17行所示,在每次迭代中,我们使用小批量深度Q学习来提高。
4.2 Planning(规划)
在规划过程中(算法1中的23-41行),采用了世界模型来生成可用于改善对话策略的模拟经验。第24行中的是代理人在直接强化学习的每个步骤中执行的规划步骤数。如果世界模型能够准确地模拟环境,则可以使用大的来加速策略学习。在DDQ中,我们使用两个重放缓冲区,用于存储真实体验,而用于模拟体验。学习和规划是由相同的DQN算法完成的,在中的真实经验用于学习,而在中的模拟经验用于规划。因此,这里我们只描述模拟体验的生成方式。
对于电影票预订对话,约束通常是电影的名称和日期,购买的票数等。请求可以包含这些位置以及剧院的位置,开始时间等。

表3分别显示了由模拟用户和实际用户生成的一些采样的用户目标和对话。第一个用户操作(第27行)可以是请求(request),也可以是通知(inform)对话。
- 一个请求,例如request(theater; moviename = batman),由一个请求槽和多个()约束槽组成,分别从R和C均匀采样。
- 通知仅包含约束槽。用户动作也可以通过NLG转换为自然语言,例如,"which theater will show batman?"。
在每个对话回合中,世界模型将当前对话状态和最后一个代理动作(表示为一个one-hot向量)作为输入,并生成用户响应,奖励和二进制变量,该变量指示是否对话终止(第33行)。使用世界模型完成该生成。一个MLP如图3所示,如下:

4.3 World Model Learning
在此过程中(算法1中的第19-22行),使用重放缓冲区中的实际经验,通过小批量SGD对进行细化。如图3所示,是一个多任务神经网络(Liu等人,2015),分别结合了模拟和的两个经典的分类任务和一个模拟回归任务。较低的层在所有任务之间共享,而顶层则是特定于任务的。
5. 实验与结果
我们在模拟和人为设定的电影票预订任务中评估DDQ方法。
5.1 Dataset

电影票预订场景中的原始会话数据是通过Amazon Mechanic Turk收集的。如表4所示,已根据领域专家定义的模式手动标记了数据集,该模式由11个对话动作和16个插槽组成。数据集总共包含280个带注释的对话,其平均长度约为11轮。
5.2 Dialogue Agents for Comparison(对话代理比较)
为了测试DDQ的性能,我们使用算法1的变体开发了不同版本的任务完成对话代理。
-
DQN代理通过标准DQN学习,在每个时期仅通过直接强化学习(算法1中的5-18行)来实现。
-DDQ(K)代理是通过算法1的DDQ来学习的,其初始世界模型是根据人类对话数据进行预先训练的,如第3.1节所述。 K是计划步骤数。我们用不同的K训练了不同版本的DDQ(K)。 -
DDQ(K,rand-initθM)代理是通过DDQ方法使用随机初始化的世界模型学习的。 - DDQ通过在人类对话数据上预先训练的初始世界模型来学习
DDQ(K,fixed $θ_M$)代理。但此后世界模型不会更新。也就是说,删除了算法1(第19-22行)中的世界模型学习部分。仅在模拟设置中评估DDQ(K,fixed )代理。 -
DQN(K)代理通过DQN学习,但实际经验是DQN代理的K次。DQN(K)仅在模拟设置中求值。它的性能可以被视为其DDQ(K)对应的上界,假设DDQ(K)中的世界模型与实际用户完全匹配。
5.3 Simulated User Evaluation(模拟用户评估)
在此设置中,通过与用户模拟器(而不是真实用户)进行交互来优化对话代理。因此,学习了世界模型来模仿用户模拟器。尽管由于模拟器和真实用户之间的差异,在经过模拟训练的代理应用于真实用户时次优,但是模拟设置使我们能够在不花费大量成本的情况下对DDQ进行详细分析,并轻松再现实验结果。
User Simulator:
我们根据任务完成对话设置调整了公开可用的用户模拟器(Li等,2016b)。在训练过程中,模拟器在每次对话回合中为坐席提供模拟的用户响应,并在对话结束时提供奖励信号。只有成功预订了电影票并且代理提供的信息满足了所有用户的约束,对话才被认为是成功的。在每次对话结束时,代理会为成功获得的正向奖励,对于失败会获得的负向奖励,其中是每次对话的最大转数,在我们的实验中设为40 。此外,代理在每个回合中都获得的奖励,因此鼓励进行较短的对话。读者可以参考附录B了解有关用户模拟器的详细信息。
附录D:用户模拟器
在任务完成对话设置中,整个对话都隐含地围绕用户目标,但是代理对用户目标一无所知,其目的是帮助用户实现该目标。通常,用户目标的定义包含两个部分:
-
inform slots包含许多作为用户约束的广告位/值对。 -
request slots包含一组插槽,用户不了解有关值的信息,但希望在对话过程中从代理获取值。ticket是默认插槽,始终显示在用户目标的request_slots中。
为了使用户目标更加现实,我们添加了用户目标的一些限制:插槽分为两组。一些插槽必须出现在用户目标中,我们称这些元素为必需(Required)插槽。在电影预订方案中,它包括电影名称(moviename), 剧院(theater), 开始时间(starttime), 日期(date), 人数(num berofpeople); 其余插槽是可选(Optional)插槽,例如剧院链(theater_chain),视频格式(video_format)等。
我们使用两种机制从第3.1节中提到的标记数据集生成了用户目标。一种机制是从数据中的第一个用户回合(不包括问候用户回合)中提取所有时隙(已知和未知),因为通常第一回合包含来自用户的一些或全部所需信息。另一种机制是提取所有出现在所有用户回合中的所有广告位(已知和未知),然后将它们汇总到一个用户目标中。我们将这些用户目标转储到文件中作为用户目标数据库。每次进行对话时,我们都会从该用户目标数据库中随机抽样一个用户目标。
Results:
结果主要仿真结果记录在表1和图4和5中。对于每个代理,我们以成功率,平均奖励和平均转数(平均5次重复实验)报告其结果。
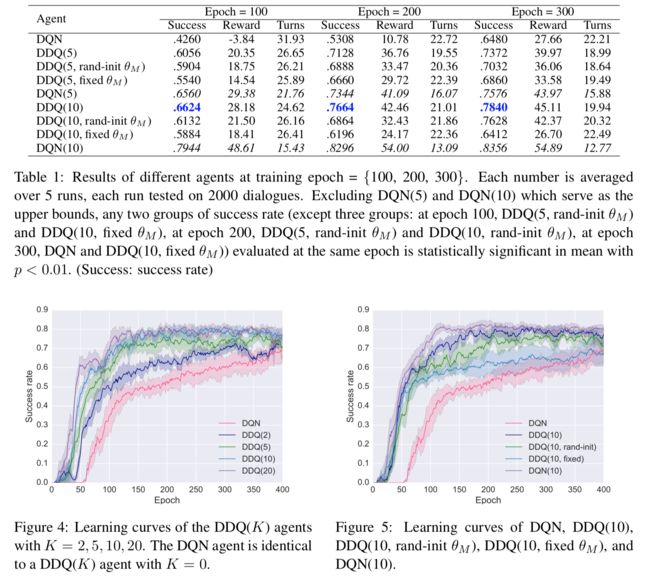
结果表明,DDQ代理始终具有DQN优势,且具有统计上的显着优势。图4显示了使用不同计划步骤训练的不同DDQ代理的学习曲线。由于所有RL代理的培训都是使用相同的基于规则的代理从RBS开始的,因此它们在前几个时期的表现非常接近。此后,对于所有值,性能都有所提高,但是对于较大的值,性能提高得更快。回想一下,当的代理与DQN代理相同,后者没有规划,而仅依赖于直接强化学习。未经规划,DQN代理大约需要180个epochs(真实对话)才能达到50%的成功率,而DDQ(10)仅花费了50个epochs。
直观地讲,K的最佳值需要为通过在世界模型的质量和模拟经验的数量之间寻求最佳折中来确定,这对于改善对话代理是有用的。这是一个非平凡的优化问题,因为对话代理和世界模型都在训练过程中不断更新,并且需要相应地调整最佳。例如,我们在实验中发现,在训练的早期阶段,可以通过使用大量的模拟经验(即使它们的质量很差)来积极地执行规划,但是在训练的后期阶段,对话代理已得到显着改善,低质量的模拟体验可能会损害性能。因此,在算法1的实现中,我们使用启发式算法在训练的后期(例如,在图4中的150个历时之后)减小的值,以缓解低水平模拟体验的负面影响。在DDQ培训期间,如何以有原则的方式优化规划步长,这留给以后的工作。
图5显示,世界模型的质量对代理的性能有重大影响。的学习曲线表明,我们可以用理想的世界模型获得最佳性能。使用预先训练的世界模型,尽管最终,和DDQ(rand-init )代理在许多时期之后达到了相同的成功率,但DDQ代理的性能提高得更快。世界模型的学习过程对于对话策略学习的效率和代理的最终性能都至关重要。例如,在早期(60个epochs之前),DDQ和DDQ(固定)的性能仍然非常接近,但是DDQ的成功率几乎达到在400Epochs后比DDQ(fixed )好10%。
5.4 Human-in-the-Loop Evaluation
在此设置下,RL通过与真实的人类用户互动的方式训练了五个对话代理(即DQN,DDQ(10),DDQ(10,rand-init ),DDQ(5)和DDQ(5,rand-init ))。在每个对话会话中,随机选择一个代理与用户交谈。向用户展示了从语料库中抽取的用户目标,并指示用户与代理进行交谈以完成任务。如果用户认为对话不太可能成功或仅仅是因为对话拖了太多回合,则可以选择放弃任务并随时结束对话。在这种情况下,对话会话被视为失败。在每次会话结束时,要求用户提供明确的反馈,以确认对话是否成功(即,是否在满足所有用户约束的情况下预订了电影票)。每条学习曲线都经过两次执行训练,每次执行产生150个对话(应用规划时会产生个附加的模拟对话)。我们总共收集了1500个对话会话,以培训所有五个代理。
主要结果显示在表2和图6中,每个代理平均超过两次独立运行。结果证实了我们在模拟实验中观察到的结果。结论总结如下:
- DDQ(10)和DQN之间的比较表明,DDQ代理的性能明显优于DQN。表3给出了两个对话代理分别与模拟用户和人类用户交互产生的四个示例对话。DQN代理在接受了100个对话的培训后,仍然表现得像一个天真的基于规则的代理,以固定的顺序逐位请求信息。当用户没有明确回答请求时(例如,usr: which theater is available?
(usr:哪个剧院可用?),代理无法正确响应。
另一方面,通过规划,用100个真实对话训练的DDQ代理更加健壮,可以成功完成50%的用户任务。 - 如DDQ(10)与DDQ(5)所示,较大的K会导致更积极的计划和更好的结果。
- 预先训练有人类意识的世界模型
双向数据可提高学习效率和代理的性能,如DDQ(5)与DDQ(5,rand-init )和DDQ(10)与DDQ(10,rand-init )所示。
6. 结论
我们为任务完成对话代理提出了一种新策略,以通过与真实用户进行交互来学习其策略。与以前的工作相比,我们的代理仅使用少量的实际用户交互即可以更有效的方式进行学习,这在许多非平凡的领域中都可以承受。我们的策略基于Deep Dyna-Q(DDQ)框架,其中将规划整合到对话策略学习中。 DDQ的有效性已通过在环实验进行了验证,表明对话代理可以通过深度RL与实际用户进行交互,从而有效地动态调整其策略。
未来研究的一个有趣的话题是规划中的探索。我们需要应对不断变化的环境中适应世界模型的挑战,例如域扩展问题(Lipton等人,2016)。正如萨顿(Sutton)和巴托(Barto)(1998)所指出的,这里的普遍问题是勘探与开发之间冲突的一种特殊表现。在计划的背景下,探索意味着尝试采取可能改善世界模型的行动,而探索意味着尝试在给定当前模型的情况下以最佳方式行事。为此,我们希望代理在环境中进行探索,但又不要太大,以至于性能会大大降低。
7. 重点论文
- Richard S Sutton. 1990. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Proceedings of the seventh international conference on machine learning. pages 216–224.
- Jiwei Li, Alexander H Miller, Sumit Chopra, Marc’Aurelio Ranzato, and Jason Weston. 2016a. Dialogue learning with human-in-the-loop. arXiv preprint arXiv:1611.09823 .
- Xiujun Li, Zachary C Lipton, Bhuwan Dhingra, Lihong Li, Jianfeng Gao, and Yun-Nung Chen. 2016b. A user simulator for task-completion dialogues. arXiv preprint arXiv:1612.05688 .
- Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidje- land, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Na- ture 518(7540):529–533.
- Zachary C Lipton, Jianfeng Gao, Lihong Li, Xiujun Li, Faisal Ahmed, and Li Deng. 2016. Efficient exploration for dialogue policy learning with bbq networks & replay buffer spiking. arXiv preprint arXiv:1608.05081 .
7. 代码编写
本文源码地址:https://github.com/MiuLab/DDQ
# 后续追加代码分析
参考文献
- Peng, B., Li, X., Gao, J., Liu, J., & Wong, K.-F. (2018). Deep Dyna-Q - Integrating Planning for Task-Completion Dialogue Policy Learning. Acl, 2182–2192.