Swin Transformer代码阅读注释

Swin Transformer代码阅读注释
- 前言
- Swin Transformer
-
- 1 PatchEmbed
- BasicLayer
-
- SwinTransformerBlock
-
- Mlp
- window_partition
- window_reverse
- WindowAttention
- Block
- PatchMerging
前言
上一篇博文以论文中的内容介绍了Swin Transformer的网络结构和一些细节。本篇博文将从官方代码中的swin_transformer.py去详细介绍Swin Transformer结构,并补充代码中才有而论文中没有的细节。
|| 如果对 Swin Transformer 不了解建议先看论文介绍再看源码 ||
Swin Transformer介绍博客:论文阅读笔记:Swin Transformer
Swin Transformer
代码中实现的网络结构与论文中的结构如如下:

如上图所示,代码中使用PatchEmbed来实现Patch Partition + Linear Embedding,使用BasicLayer来实现Swin Transformer Block + PatchMerging,对于最后一个BasicLayer不使用PatchMerging来降采样。
Swin-T 的配置如下:

网络结构介绍可看Swin Transformer介绍博客:论文阅读笔记:Swin Transformer
整体结构代码和注释如下(代码大部分和和 Vision Transformer 是一样):
class SwinTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
'''
img_size(int | tuple(int)): 输入图像尺寸. 默认: 224
patch_size (int | tuple(int)): Patch尺寸. 默认: Swin-T参数配置表中 stage1中的96
in_chans (int): 输入图像通道. 默认: 3
num_classes (int): 分类数. 默认: 1000
embed_dim (int): Patch embedding的输出通道. 默认: 96 (Swin-T参数配置表中 stage 1 中的 96-d)
depths (tuple(int)):Swin Transformer Block 的个数. 默认:[2, 2, 6, 2] (Swin-T参数配置表中的[×2, ×2, ×6, ×2])
num_heads (tuple(int)): 不同层 MSA 计算中的 head 数. 默认:[3, 6, 12, 24] (Swin-T参数配置表中的[head 3,head 6,head 12,head 24])
window_size (int): W-MSA 和 SW-MSA 的 Window 尺寸. 默认: 7 (Swin-T参数配置表中的 “win.sz. 7×7”)
mlp_ratio (float): 通过MLP的输出通道倍数. 默认: 4 (Swin-T参数配置表中的“dim 96”,“dim 192”,“dim 384”,“dim 768”可以看出)
qkv_bias (bool): 使用 Linear 将输入映射到 qkv 时,Linear是否使用偏置. 默认: True
qk_scale (float):qk缩放比例,如果是 None 则使用根号 dim_k 分之一. 默认: None
drop_rate (float): dropout概率. 默认: 0
attn_drop_rate (float): attention 中的 dropout 概率. 默认: 0
drop_path_rate (float): attention 中的 droppath 概率. 默认: 0.1
norm_layer (nn.Module): 归一化方式. 默认: nn.LayerNorm.
ape (bool): 是否在 patch embedding 后使用绝对位置编码. 默认: False
patch_norm (bool): 是否在 patch embedding 后使用归一化. 默认: True
use_checkpoint (bool): 是否 checkpointing 节省内存. 默认: False
'''
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
'''
经过4个stage后的通道数(从96->768 即:96*2^(4-1)=768)
'''
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
'''
将图片划分成没有重叠的多个patch
PatchEmbed代码在下文中介绍
patches_resolution = [img_size[0]//patch_size[0], img_size[1]//patch_size[1]] = [56,56]
num_patches = patches_resolution[0] * patches_resolution[1] = 3136
'''
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
'''
如果使用绝对位置编码则构建可学习的绝对位置编码参数:
self.absolute_pos_embed : [1,3136,96]
默认不使用
'''
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
'''
pos_drop 以 drop_rate 概率进行 Dropout
'''
self.pos_drop = nn.Dropout(p=drop_rate)
'''
构建首项为0,长度为depths(2+2+6+2=12)的等差数列,且最后一项小于drop_path_rate
也就是说 传入 BasicLayer 的 droppath 概率是递增的。
代码这里是让 drop_path_ratio 默认等于0.1
最后利用参数构建 depth(12) 层 BasicLayer 层
BasicLayer 的代码在下文中介绍
'''
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer), #每个Basiclayer模块后通道数都翻倍
'''
每个Basiclayer都进行了降采样
所以input_resolution每一次都要除以2
'''
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
'''
如果i_layer 是最后一层则不使用PatchMerging 来降采样
'''
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
'''
进行归一化和平均池化
最后用一个Linear做预测head
'''
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
'''
初始化权重
'''
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
'''
如图所示先进行patch embedding
如果使用绝对位置偏置就加上绝对位置编码
'''
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
'''
循环执行Blocks
'''
for layer in self.layers:
x = layer(x)
'''
归一化并平均池化
'''
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
'''
对swin transformer的特征提取进行预测
'''
x = self.head(x)
return x
1 PatchEmbed
Swin Transformer中的PatchEmbed模块和 VIT 中的 Linear Projection of Flattened Patches: PatchEmbed模块差不多,可查看博文Vision Transformer(Pytorch版)代码阅读注释 查看,其主要思想是通过感受野大小等于步距大小的卷积来实现,与 VIT 不同的是其使用了nn.LayerNorm。
PatchEmbed代码和注释如下:
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
Args:
img_size (int): 图像尺寸. 默认: 224.
patch_size (int): token尺寸. 默认: 4.
in_chans (int): 图像通道. 默认: 3.
embed_dim (int): patch embed通道. 默认: 96.
norm_layer (nn.Module, optional): 归一化. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
'''
self.image_size = (224,224)
self.patch_size = (4,4)
self.patches_resolution = [56,56]
self.num_patches = 56*56=3136
'''
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
'''
self.in_chans = 3
self.embed_dim = 96
'''
self.in_chans = in_chans
self.embed_dim = embed_dim
'''
self.proj = nn.Conv2d(3,96,(4,4),4)
self.norm = nn.LayerNorm(96)
'''
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
'''
self.proj(x):[B,3,224,224]->[B,96,56,56]
flatten(2):[B,96,56,56]->[B,96,56*56]=[B,96,3136]
transpose(1, 2):[B,96,3136]->[B,3136,96]
self.norm(x):[B,3136,96]->[B,3136,96]
'''
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
BasicLayer
代码中使用BasicLayer来实现论文中的Swin Transformer Block + PatchMerging,对于最后一个BasicLayer不使用PatchMerging来降采样。
BasicLayer的代码和注释如下:
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): 输入特征图的通道数.
input_resolution (tuple[int]): 输入特征图的分辨率大小.
depth (int): SwinTransformerBlock的个数.
num_heads (int): Muti-Head Self-Attention 中的head个数.
window_size (int): window 大小.
mlp_ratio (float): patch embedding通过MLP的通道倍数.
qkv_bias (bool): 使用 Linear 将输入映射到 qkv 时,Linear是否使用偏置. 默认: True
qk_scale (float):qk缩放比例,如果是 None 则使用根号 dim_k 分之一. 默认: None
drop (float, optional): dropout概率. 默认: 0
attn_drop (float, optional): attention 中的 dropout 概率. 默认: 0
drop_path (float | tuple[float], optional): attention 中的 droppath 概率. 默认: 0.1
norm_layer (nn.Module): 归一化方式. 默认: nn.LayerNorm.
downsample (nn.Module | None, optional): 降采样层. 默认: None 代码使用PatchMerging
use_checkpoint (bool): 是否 checkpointing 节省内存. 默认: False
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
'''
构建SwinTransformerBlock
SwinTransformerBlock代码在下文介绍
'''
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
'''
如果i是偶数,则表示是W-MSA,shift_size =0
如果i是奇数,则表示是SW-MSA,shift_size = window_size // 2
'''
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
'''
使用PatchMerging进行降采样
PatchMerging代码在下文介绍
'''
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
SwinTransformerBlock
SwinTransformerBlock的结构如下:
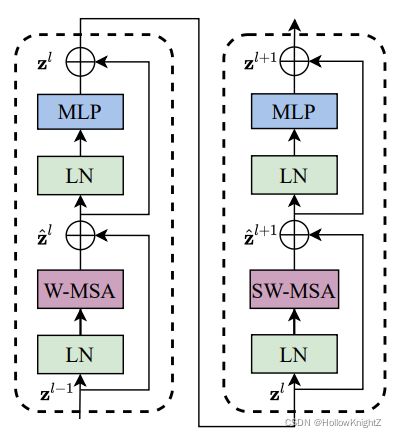
Mlp
此处和 VIT 中MLP一模一样,可查看Vision Transformer(Pytorch版)代码阅读注释 。代码也很简单,就不再做任何赘述了。
Mlp的代码如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
window_partition
W-MSA和SW-MSA首先需要将特征图拆分成多个windows。

window_partition的代码和注释如下:
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
'''
[B, H, W, C] -> [BHW//(window_size*window_size), window_size, window_size, C]
'''
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
window_reverse
在对每一个windows进行WSA计算以后需要将其还原成正常的特征图传入下一模块中。其实就是window_partition的逆过程。
window_reverse的代码和注释如下:
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
WindowAttention
WindowAttention就是在 Vision Transformer 模块的Attention基础上加入了相对位置偏移relative_position_bias_table(即论文中提出的 Relative Position Bias)来提升精度:
![]()
生成相对位置偏置的过程(以一个head为例,假设window_h = 2,window_w = 2,相关代码已在图中标出):
1.随机生成相对位置偏置表relative_position_bias_table:

self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
2.首先windows内部每个像素都有自己的位置编码,其绝对位置编码的坐标abs_coords如果以左上角为原点,则如下图:

coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
3.为了获得每个绝对坐标相对于其他坐标的相对位置,则需要用每个绝对坐标减去其他绝对坐标,即:
- 用 ( 0 , 0 ) (0,0) (0,0) 分别减去 ( 0 , 1 ) (0,1) (0,1), ( 1 , 0 ) (1,0) (1,0), ( 1 , 1 ) (1,1) (1,1)
- 用 ( 0 , 1 ) (0,1) (0,1) 分别减去 ( 0 , 0 ) (0,0) (0,0), ( 1 , 0 ) (1,0) (1,0), ( 1 , 1 ) (1,1) (1,1)
- 用 ( 1 , 0 ) (1,0) (1,0) 分别减去 ( 0 , 0 ) (0,0) (0,0), ( 0 , 1 ) (0,1) (0,1), ( 1 , 1 ) (1,1) (1,1)
- 用 ( 1 , 1 ) (1,1) (1,1) 分别减去 ( 0 , 0 ) (0,0) (0,0), ( 0 , 1 ) (0,1) (0,1), ( 1 , 0 ) (1,0) (1,0)
以此得到相对坐标relative_coords。这样每一个像素相对于其他像素的相对位置关系就得到了。
代码中实现过程如下:

relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
4.将二维的坐标转换成一维的索引relative_position_index。
- 先将每一行加上 w i n d o w − h − 1 window_-h-1 window−h−1,每一列加上 w i n d o w − w − 1 window_-w-1 window−w−1
- 然后将每一行乘上 2 ∗ w i n d o w − w − 1 2*window_-w-1 2∗window−w−1
- 最后将行列坐标相加,得到
relative_position_index
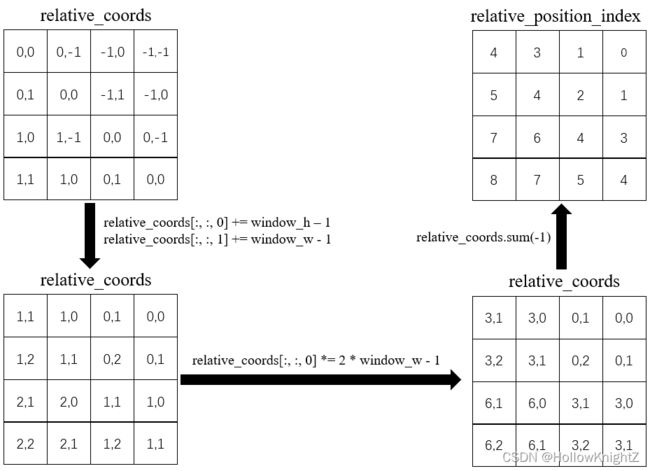
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
这里作用的用意是为了让不同的相对关系只对应一种数字。如果一开始直接将行列坐标相加,会发现 ( 0 , 1 ) (0,1) (0,1) 和 ( 1 , 0 ) (1,0) (1,0) 这两种关系无法分辨(相加都是1)。而如果不乘上 2 ∗ w i n d o w − w − 1 2*window_-w-1 2∗window−w−1,会发现 ( 1 , 1 ) (1,1) (1,1) 和 ( 2 , 0 ) (2,0) (2,0) 这两种关系无法分辨(相加都是2)。所以经过几次变换以后再转换成1维的坐标就可以得到唯一的相对位置关系,如下图:

- 0代表右下的相对位置关系
- 1代表正下的相对位置关系
- 2代表坐下的相对位置关系
- 3代表正右的相对位置关系
- 4代表和自己的相对位置关系
- 5代表正左的相对位置关系
- 6代表右上的相对位置关系
- 7代表正上的相对位置关系
- 8代表左上的相对位置关系
5.通过相对位置索引relative_position_index在相对位置偏置表relative_position_bias_table中取找对应的相对位置偏置relative_position_bias。

relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
WindowAttention的代码和注释如下(大部分代码在Vision Transformer(Pytorch版)代码阅读注释的Multi-Head Attention部分已经介绍,主要还是相对位置偏置部分不同):
class WindowAttention(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): 输入特征图的通道
window_size (tuple[int]): window的尺寸.
num_heads (int): muti-head self-attention的head个数.
qkv_bias (bool, optional): 是否使用 qkv 偏置(即使用 Linear 将输入映射到 qkv 时,Linear是否使用 bias )
qk_scale (float | None, optional): qk缩放比例,默认使用根号 dim_k 分之一
attn_drop (float, optional): attention 中的 dropout 概率
proj_drop (float, optional): linear 中的 dropout 概率
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
'''
VIT源码阅读中已经讲过了
'''
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
'''
上述生成相对位置偏置的过程对应的代码:
1.生成相对位置偏置表
relative_position_bias_table.shape = [2*window_h-1 * 2*window_w-1, num_heads]
'''
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
'''
2.生成绝对位置坐标
coords.shape = [2, window_h, window_w]
'''
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
'''
3.生成相对位置坐标
relative_coords.shape = [window_h*window_w, window_h*window_w, 2]
'''
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
'''
4.将二维相对位置坐标转换成一维相对位置索引
relative_position_index = [window_h*window_w, window_h*window_w]
'''
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
'''
VIT源码阅读中已经讲过了,是一模一样的
'''
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: shape为(num_windows*B, N, C)的特征图
mask: 为了使SW-MSA中不相邻的子窗口之间的不进行qk匹配,论文阅读笔记中已介绍,
mask的生成和使用原理在后面介绍SwinTransformerBlock的代码时会介绍
"""
B_, N, C = x.shape
'''
将VIY和attention时已经讲过了,不再介绍
'''
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
'''
5.根据相对位置索引在相对位置偏置表中找到对应的相对位置偏置并加上
'''
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
'''
利用mask掩膜计算将不相邻的子窗口之间使用softmax抑制来去除qk匹配
'''
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
Block
在论文阅读笔记:Swin Transformer中讲过Efficient batch computation for shifted configuration:

其将A、B、C三个框中的 window 移动到四个 4 × 4 红色框的对应位置,使其凑成四个 4 × 4 的window。由于有几个 window 是由不相邻的子窗口组成,需要通过Masked MSA 掩膜计算来限制每个 window 中的不同子窗口的 MSA。
掩膜计算相关代码如下:
'''
self.input_resolution为当前特征图的大小
img_mask 用于记录同特征图上每个像素的掩膜权重
h_slices w_slices 分别为宽高切片
self.shift_size 只有为SW-MSA计算时为self.window_size//2,W-MSA计算时为0
'''
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
'''
将不同区域按0到8进行标记
'''
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_window s.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
过程如下(假设self.input_resolution=(8,8),self.window_size=4,self.shift_size=self.window_size//2=2):
1.按特征图中的 window 通过切片方式生成划分子窗口的img_mask:

2.对img_mask中不同区域按0到8进行标记:

3.将window拆分并展开:
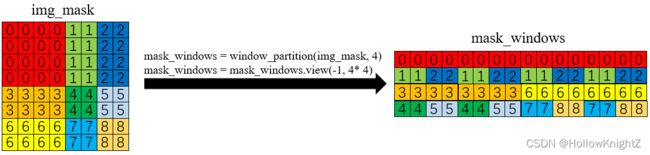
4.每个window中分别用每个像素的标记值互减,计算像素之间是否在同一个子window中得到attn_mask(attn_mask.shape=[4,16,16]):
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
举例说明:
第一个window标记向量为:[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],依次减去每一个标记值,进行了16×16次减法,得到16×16的矩阵[[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],...,[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]
第二个window标记向量为:[1,1,2,2,1,1,2,2,1,1,2,2,1,1,2,2],依次减去每一个标记值,进行了16×16次减法,得到16×16的矩阵[[0,0,1,1,0,0,1,1,0,0,1,1,0,0,1,1],...,[-1,-1,0,0,-1,-1,0,0,-1,-1,0,0,-1,-1,0,0]]
第三个window标记向量为:[3,3,3,3,3,3,3,3,6,6,6,6,6,6,6,6],依次减去每一个标记值,进行了16×16次减法,得到16×16的矩阵[[0,0,0,0,0,0,0,0,3,3,3,3,3,3,3,3],...,[0,0,0,0,0,0,0,0,-3,-3,-3,-3,-3,-3,-3,-3]]
第四个window标记向量为:[4,4,5,5,4,4,5,5,7,7,8,8,7,7,8,8],依次减去每一个标记值,进行了16×16次减法,得到16×16的矩阵[[0,0,1,1,0,0,1,1,3,3,4.4,3,3,4,4],...,[-4,-4,-3,-3,-4,-4,-3,-3,-1,-1,0,0,-1,-1,0,0]]
attn_mask中某个window第 i i i 行第 j j j 列如果为 0,则表示第 i i i 个像素和第 j j j 个像素属于同一个子窗口。
5.给attn_mask赋值(如果为0,则等于0,不为0,则等于-100):
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
结合WindowAttention的代码:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
其实现原理如下(以第0个像素为例):
第0个像素与其他像素的再完成 Q K T / d + B QK^T/\sqrt{d}+B QKT/d+B的计算后,得到 α 0 , 0 \alpha_{0,0} α0,0 , α 0 , 1 \alpha_{0,1} α0,1… α 0 , 15 \alpha_{0,15} α0,15,再进行掩膜计算attn = attn + mask,这样与像素0不在同一子窗口的像素结果就会减去100,最后通过softmax使其等于0,这样就抑制了不同窗口间的qk匹配。
再进行掩膜计算,
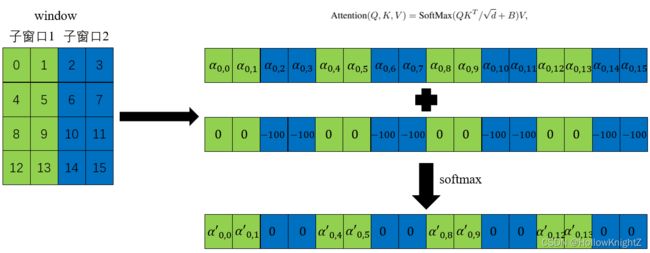
那么代码是如何实现子窗口之间的移动的呢?
窗口移动代码如下:
'''
X.shape = [B,H,W,C]
在 H 所在维度上滚动-self.shift_size个像素,
在 W 所在维度滚动-self.shift_size个像素
shift_size = window_size//2
注:torch.roll正方向是往下
'''
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
其实现过程如下(假设window_size = 4,shift_size = window_size //2 = 2):

接着对图像进行拆分即可:

SwinTransformerBlock的代码和注释如下:
class SwinTransformerBlock(nn.Module):
""" Swin Transformer Block.
Args:
dim (int): 特征图的维度.
input_resolution (tuple[int]): 输入特征图的分辨率.
num_heads (int): muti-head self-attention的headg个数.
window_size (int): 窗口尺寸.
shift_size (int): SW-MSA的偏移尺寸,为window_size // 2.
mlp_ratio (float): patch embedding通过MLP的通道倍数.
qkv_bias (bool): 使用 Linear 将输入映射到 qkv 时,Linear是否使用偏置. 默认: True
qk_scale (float):qk缩放比例,如果是 None 则使用根号 dim_k 分之一. 默认: None
drop (float, optional): dropout概率. 默认: 0
attn_drop (float, optional): attention 中的 dropout 概率. 默认: 0
drop_path (float | tuple[float], optional): attention 中的 droppath 概率. 默认: 0.1
act_layer (nn.Module, optional): 激活函数. 默认: nn.GELU
norm_layer (nn.Module, optional): 归一化层. 默认: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
'''
如果窗口尺寸已经大于分辨率,则让窗口尺寸等于分辨率H、W 中较小的那一个
'''
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
'''
如果偏移量大于0,则表示使用SW-MSA
计算attn_mask,原理如上述过程。
'''
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
'''
在 H 所在维度上滚动-self.shift_size个像素,
在 W 所在维度滚动-self.shift_size个像素
注:torch.roll正方向是从上往下和从左往右
'''
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
'''
划分窗口
'''
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
'''
每个window进行MSA计算
'''
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
'''
合并窗口
'''
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
'''
如果是SW-MSA还需要将窗口滑动回来
'''
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
'''
残差结构
'''
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
PatchMerging
论文阅读笔记:Swin Transformer已对PatchMerging进行了介绍,其流程图如下(最终通道翻倍,大小变为原来的一半达到降采样的效果):

PatchMerging的代码和注释如下:
class PatchMerging(nn.Module):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): 输入特征图的大小
dim (int): 输入特征图的通道
norm_layer (nn.Module, optional): 归一化层. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
'''
将输出通道在最初的特征图通道上翻倍(即流程图中最4个步骤和第1个步骤的倍数关系)
'''
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
'''
将输入按流程图中的方式拆分成4份
在concat以后进行flatten
'''
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
'''
进行LayerNorm并再用一个全连接层输出
'''
x = self.norm(x)
x = self.reduction(x)
return x