参考:
MySQL索引背后的数据结构及算法原理:https://www.jianshu.com/p/fae74b6a54e3
数据库索引的数据结构:https://www.jianshu.com/p/46349daf531c
索引与算法:https://www.jianshu.com/p/3cd2ff996216
数据库索引创建与优化:https://www.jianshu.com/p/6446c0118427
B-Tree与B+Tree:https://www.cnblogs.com/vincently/p/4526560.html
一.索引概述
1.定义
- 存储引擎用于加速记录查找的一种数据结构
- 时间复杂度O(n)的顺序查找不能满足海量数据场景
- 索引通过不断缩小数据查询范围快速获取查询结果
- 按数据结构,常见有 B树 / B+树 / 哈希 索引
2.索引的缺点
- 创建和维护索引的时间成本
- 创建和维护索引的空间成本
- 每次增删改操作时,索引需动态维护,降低表的增删改效率
二.索引分类
1.基本索引类型
- 普通索引(单列索引)
最基本的索引,没有任何限制 - 复合索引(组合索引)
在多个字段上创建的索引,有多个索引列,遵循最左前缀原则
联合索引自动对第二个键值进行排序处理
最左前缀:仅当查询条件使用了复合索引的第一个字段,索引才会使用 - 唯一索引
创建唯一索引的列的值必须唯一,不允许多个null
一般会将需创建唯一索引的字段设为 not null - 主键索引
特殊的唯一索引,一个表只能有一个,不允许空值 - 全文索引
用于不适合使用模糊查询产生全表扫描的海量数据场景
2.B+Tree索引
- B-树演化自平衡二叉树,数据结构如下(有序数组+平衡多叉树)
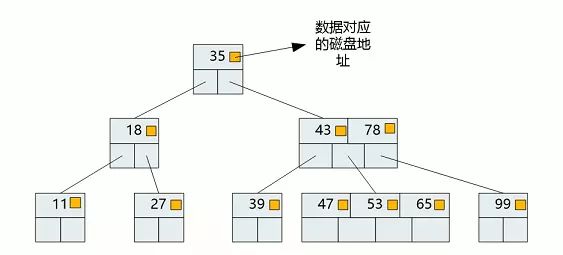
1)有效减少IO次数(平衡 + 节点数据多/深度小)
2)不能解决范围查找
3)内节点存放指针+数据
- B+树是B-树的变种,数据结构如下(有序数组链表+平衡多叉树)

1)节点可存放更多Key(数据地址只存在叶子节点)
2)叶子节点双向连接,方便范围查找
3)内节点只存放指针
- B+树索引根据叶节点是否存放整行数据分为聚集索引和辅助索引
-
查找过程:如下图所示,查找数据项29
 B+数索引数据结构
B+数索引数据结构
1)加载磁盘块1到内存,第一次IO,通过二分查找锁定磁盘块1的P2指针
2)加载P2指针对应的磁盘块3,第二次IO,同理锁定磁盘块3的P2指针
3)加载P2指针对应的磁盘块8,第三次IO,查找到数据项29 - B+树索引字段越小,查询效率越高
1)设 N=当前数据表的数据量,m=磁盘块大小/数据项大小=每磁盘块数据项数,则有树高h=log(m+1)N
2)IO速度取决于B+树的高度h - B+数最左匹配特性
1)当B+树索引的数据项是复合数据结构时,如索引为(name,age,sex),将从左到右建立搜索树
2)如(Tom,18,M)检索时,B+树索引会先比较name字段,再比较age和sex,最后完成检索
3)如(18,M)检索时,B+树索引(name,age,sex)将因无法匹配首个比较因子name而失效 - 聚集索引(clustered index)和辅助索引(secondary index)
1)聚集索引的叶子节点(也称数据页)存数据
2)辅助索引的叶子节点仍是索引节点,但有指向对应数据块的指针
3)若存在主键,MySQL以主键作为聚集索引;否则,以表中的非空唯一索引作为聚集索引;再否则,MySQL为表生成rowId作为聚集索引

- 覆盖索引(covering index)
支持直接从辅助索引中得到查询记录,不必再查询聚集索引 - Cardinality值
1)衡量字段可能取值范围大小的值
2)字段Cardinality值越高,字段选择性越高,越适合使用B+树索引
3.哈希索引
- InnoDB使用除法散列的哈希函数( h(k)=k mod m ),采用链接法解决哈希冲突
- 查询单条快,范围查询慢
4.常见存储引擎支持的索引
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B-Tree | 支持 | 支持 | 支持 |
| Hash | 不支持 | 不支持 | 支持 |
| R-Tree | 不支持 | 支持 | 不支持 |
| Full-text | 暂不支持 | 支持 | 支持 |
三.索引与查询优化
1.查询效率与IO次数/IO介质
- 内存IO
1)IO时间仅与IO次数线性相关
2)不存在机械操作,两次IO数据的“距离”不影响IO时间
3)IO速度快 - 磁盘IO
1)IO时间与次数和磁头机械运动耗时相关
2)磁头机械运动存在寻道时间和旋转时间
3)IO速度慢 - 局部性原理和磁盘预读
1)局部性原理指当一个数据被使用时,其附近数据通常也将马上被使用
2)磁盘顺序读取不需要寻道,仅需很少的旋转时间,效率较高
3)磁盘IO时会顺序读取目的数据之后一定长度的数据到内存
2.索引使用场景
- 定义有主键的列,建立索引可加速定位到表中特定行
- 定义有外键的列,建立索引可加快表间连接
- 在指定范围内(where子句)快速频繁查询的数据列,可利用索引的排序加快查询速度
- 不经常查询、记录较少或Cardinality值较低的列不适用索引
3.前缀索引
- 用列的前缀代替整个列作为索引key的索引优化策略
- 当前缀长度合适时,可以使前缀索引的选择性接近全列索引
- 缺点是不能用于ORDER BY或GROUP BY操作
4.InnoDB的自增主键与插入优化
- InnoDB的聚集索引要求同一叶子节点内各条数据记录按主键顺序存放
- InnoDB会在装载因子达到一定值(默认15/16)时打开新页(叶子节点)
- 使用自增主键顺序插入,不需移动已有数据,索引维护开销较低
5.选择整型或较小的定长字符串作为索引
- 减少B+Tree高度,减少IO次数,提高查询效率
四.应用场景
1.最左前缀原理与相关优化
- MySQL使用联合索引时,会从左到右一直匹配,直至遇到范围查询(>,<,between,like)为止
比如:where a=1 and b=2 and c>3 and d=4,如果建立的是(a,b,c,d)的联合索引,那么 d 用不到索引。而如果建立成(a,b,d,c)那么d将用到索引。因为MySQL优化器将d=4的条件前置到了c>3前面。 - employees.titles表有主索引
,考虑下列场景 - 使用“=”或“in”精确匹配将调用索引,查询器会优化where子句的条件顺序以适用索引
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26' AND emp_no='10001' AND title='Senior Engineer';
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
- 查询条件精确匹配索引左边连续一个或几个列时,可部分使用索引
下述语句explain结果中key_len为4,说明只用了索引的emp_no
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
- 查询条件精确匹配索引中的emp_no和from_date,但缺失title
只能使用中的emp_no,可通过“隔离列”优化法补全title
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
- 查询条件未指定
中的第一列emp_no,无法使用索引
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- 匹配某列的前缀字符串,通配符%不在开头即可使用索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title LIKE 'Senior%';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- 范围查询
1)范围列如果是最左前缀则可使用索引,但范围列后面的列无法使用索引
2)查询条件有多个范围列的,无法使用索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no < '10010' and title='Senior Engineer';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- 查询条件含有函数或表达式则无法使用索引
1)下面语句1无法为title列(使用函数)应用索引
2)下面语句2无法为emp_no列(使用表达式)应用索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND left(title, 6)='Senior';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
EXPLAIN SELECT * FROM employees.titles WHERE emp_no - 1='10000';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
2.常见索引失效情况
以students表为例,建表语句如下
CREATE TABLE `students` (
`stud_id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`email` varchar(50) NOT NULL,
`phone` varchar(1) NOT NULL,
`create_date` date DEFAULT NULL,
PRIMARY KEY (`stud_id`)
)
INSERT INTO `learn_mybatis`.`students` (`stud_id`, `name`, `email`, `phone`, `create_date`) VALUES ('1', 'admin', '[email protected]', '18729902095', '1983-06-25');
INSERT INTO `learn_mybatis`.`students` (`stud_id`, `name`, `email`, `phone`, `create_date`) VALUES ('2', 'root', '[email protected]', '2', '1983-12-25');
INSERT INTO `learn_mybatis`.`students` (`stud_id`, `name`, `email`, `phone`, `create_date`) VALUES ('3', '110', '[email protected]', '3dsad', '2017-04-28');
- where后使用or连接两个或多个建立索引的字段
建立email和phone字段的简单索引
CREATE INDEX index_name_email ON students(email);
CREATE INDEX index_name_phone ON students(phone);
or连接单个索引字段时,可使用索引,如:
EXPLAIN select * from students where stud_id='1' or phone='18729902095';
EXPLAIN select * from students where stud_id='1' or email='[email protected]';
or连接多个索引字段时,会依次扫描索引email和索引phone,再合并两个扫描结果,如果需要合并的结果集非常大,合并将非常耗时,导致索引失效。如:
EXPLAIN select * from students where phone='18729902095' or email='[email protected]'
EXPLAIN select * from students where stud_id='1' or phone='222' or email='[email protected]'
- 使用like,且查询以通配符%开头
建立email字段的简单索引
CREATE INDEX index_name_email ON students(email);
# 使用了index_name_email索引
EXPLAIN select * from students where email like '[email protected]%'
# 没有使用index_name_email索引,索引失效
EXPLAIN select * from students where email like '%[email protected]'
EXPLAIN select * from students where email like '%[email protected]%'
- 违反最左前缀原则(复合索引只有在查询使用了最左边的第一个字段才会被使用)
建立email和phone的复合索引index_email_phone
create index index_email_phone on students(email,phone);
# 使用了 index_email_phone 索引
EXPLAIN select * from students where email='[email protected]' and phone='18729902095'
EXPLAIN select * from students where phone='18729902095' and email='[email protected]'
EXPLAIN select * from students where email='[email protected]' and name='admin'
# 没有使用index_email_phone索引,复合索引失效
EXPLAIN select * from students where phone='18729902095' and name='admin'
- 字段类型为字符串时,必须使用引号引用,否则不使用索引
建立name字段索引index_name
CREATE INDEX index_name ON students(name);
# 使用索引
EXPLAIN select * from students where name='110'
# 没有使用索引
EXPLAIN select * from students where name=110
- 使用函数和表达式将使索引失效
略
3.注意
- in可以使用索引
select A, B, C from TABLE where A in (m, n, p) and B=b;
推荐索引:(A,B)
对于in谓词后的列表,MySQL将循环列表中数据,然后分别与后续索引字段联合。上述查询将被MySQL拆分为(A=m and B=b) union (A=n and B=b) union (A=p and B=b),然后再分别以这三个拆分条件扫描联合索引(A,B)。由于与or相比,in列表条件不重复,合并结果集时不存在去重操作,所以查询效率高,能够使用索引
- 不等式符号(>、<、!=)可使用索引
select A, B, C, D from TABLE where A=a and B>b and C>c;
推荐索引:(A, B, C, D)或(A, C, B, D),具体使用哪个索引根据B和C的选择性定
1)需要满足最左前缀原则
2)建立复合索引时,将选择性高的字段放在前面进行索引过滤,将选择性低的字段放在后面进行索引覆盖扫描
4.一个索引失败的案例(索引建立在区分度低的列)
mysql> desc s1;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| gender | char(5) | YES | | NULL | |
| email | varchar(50) | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
现象:
1)没有为name字段添加索引时查询慢
2)为name字段添加索引后查询速度变快
3)如果查询条件为name='egon',速度又变慢了

原因:
1)name字段区分度很低,大多数name都被赋值为egon
2)根据B+树结构,name字段索引的树高很高
3)当查询条件正好是name='egon'时,IO次数较大,查询效率低,与全表扫描速度相近
欲去不得去,薄游成久游