©原创作者 | FLPPED
参考论文:
A Survey of Transformers
论文地址:
https://arxiv.org/abs/2106.04554
研究背景:
Transformer在人工智能的许多领域取得了巨大的成功,例如自然语言处理,计算机视觉和音频处理,也自然吸引了大量的学术和行业研究人员的兴趣。
其最初是针对seq2seq的机器翻译模型而设计的,在后续的其他工作中,以Transformer为基础的预训练模型,在不同的任务中取得了state-of-the-art 的表现,有关Transformer的变种也是层出不穷(“x-former”)。
本文将从传统的vanilla Transformer入手,从模型结构改进、预训练等两个角度全面的介绍各种不同形式的x-former,并对其未来的可能发展方向提出可行的建议。
01 Vanilla Transformer
Vanilla Transformer[1]是一个seq2seq的模型结构,包含encoder和decoder两个部分,每个部分由L个相同的block组成。其中每个encoder包含多头注意力机制和piece-wise的前馈神经网络。
Decoder相比于encoder额外增加了cross-attention的模块,并且在自注意力机制中加入了mask,防止当前位置看到未来的信息。
模型的具体组成如图1所示。下面具体介绍几个重要的模块:
Ø Attention 模块:
Transformer采用了Query-Key-Value(QKV) 组成的注意力机制,其计算公式如下所示。为了缓解softmax 在计算时产生的梯度消失问题,
query和key在做点乘时需要除以
。
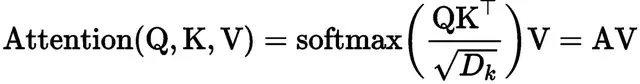


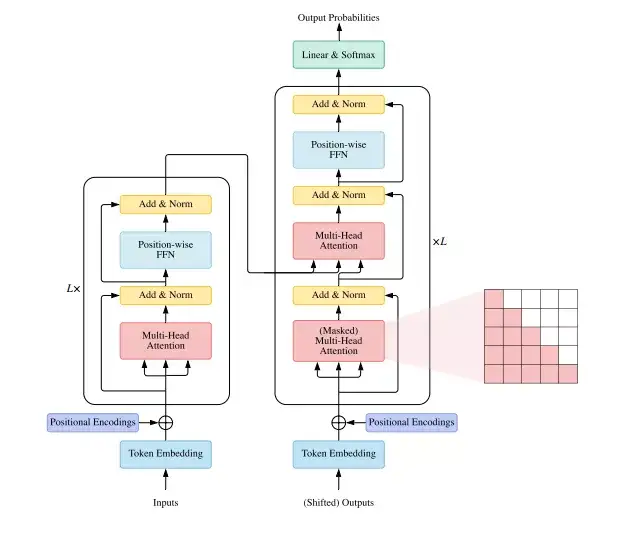
图1. Vanilla Transformer的模型示意图
在Transformer内部中,共有三种不同形式的attention:
● Self-attention:encoder中,Q=K=V。
● Masked Self-attention: Decoder中,当前位置只能注意到其位置之前的信息,通过将注意力矩阵做mask实现,如图1所示。
● Cross-attention: query 来自于decoder中上一层的输出,而K 和V使用的是encoder中的输出。
Ø Position-wise FFN、Residual connection and Normalization
全连接:
残差连接:在每个模块之间,transformer采用了残差连接的方法,并且都会经过layer normalization 层。
自注意力机制在Transformer中发挥着重要的作用,但在实际应用中也面临着两个挑战:
(1) complexity:self-attention的时间复杂度是O(T2·D),在处理长序列问题上存在较大瓶颈。
(2) structural prior:self-attention没有对输入做输入做任何结构偏差的假设,因此对于小数据集可能存在过拟合现象。
下面从这两个方面的改进,进一步介绍Transformer的各种变体。
02 模型结构: Attention
2.1 Sparse Attention
Sparse attention 在计算attention matrix时不会attend 每个token,而是遵循下面的公式(6).根据确定sparse connection的方法又可以细分为 position-based 和 content-based 两种。

2.1.1 Position-based Sparse Attention
对于position-based sparse attention来说,其主要的特点在于attention matrix模式的设计,这里首先介绍一下几种具有代表性的模式:
Ø Global Attention
为了缓解稀疏注意力在中长距离依赖关系上模型能力的退化,这一类模式增加了一些全局节点作为节点间信息传播的枢纽。这些全局节点可以关注序列中的所有节点,并且整个序列也都会关注这些全局节点。
Ø Band Attention
这一类attention 也可以成为局部attention或者滑动窗口attention,设计的主要思路在于,由于大部分的数据都有很强的局部关系特性,因此可以限制query只关注附近的一些节点从而做到稀疏化的效果。
Ø Dilated Attention
这种attention的方法与dilated CNN的方法十分相似,可以在不增加计算复杂度的情况下扩大感受野的大小,并且通过调整dilation 的间距可以扩展至strided attention.
Ø Random Attention
为了提高非局部位置之间的联系,每个query随机的选择一些位置去attend.
Ø Block Local Attention
将整个序列划分为几个没有重叠部分的block,每个block内部之间做attention.
提到的几种attention matrix如下图2所示。
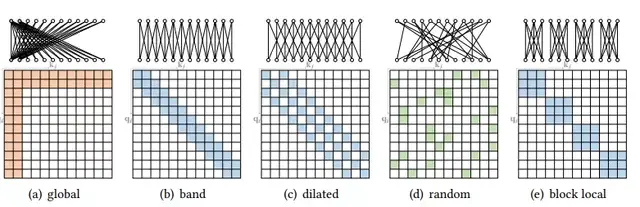
图2 具有代表性的几种sparse attention 模式
在实际提出的几种变体中,其实往往是上面几种模式的组合。
下面具体介绍几个compound sparse attention的方法。
(1) Star Transformer[2]
Star Transformer使用了band attention 和global attention的组合方法,具体来说,文章中定义了一个global node 和带宽为三的band attention, 因此任意一对不相连的节点之间通过一个共享的global node 相连接,位置相邻的节点之间可以直接相连,如图3(a)所示。
(2) Longformer[3]
Longformer 使用的是band attention 和内部global node attention的组合。在分类任务中,global node被选作[CLS]token;在问答任务中,所有question中的token被当作global nodes. 此外,在band attention之前的几层block中,文章还使用了dilated attention以此来加大感受野,如图3(b)所示。
(3) Extended Transformer Consturction(ETC)[4]
ETC使用了band attention和external global-node attention的组合,并且使用mask方法来处理结构化的输入,如图3(c)所示。
(4) BigBird[5]
BigBird中相比于上面提到的几种模型,还使用了额外的random attention 来近似full attention, 如图3(d)所示。并且通过理论分析,文章证明了使用sparse encoder 和decoder可以模拟任何图灵机。
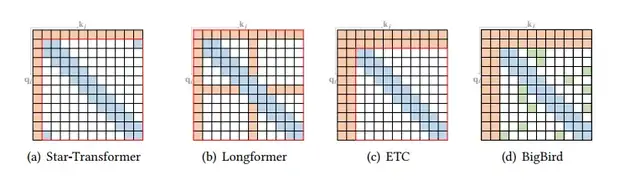
图3 几种compound sparse attention 模式
(5)Extended Sparse Attention
除了上述几种模式,还有一些针对特殊数据的扩展稀疏模式。对于文本数据,BP-Transformer[6] 构建了一个二叉树,所有token都是叶子节点,其内部的节点为包含多个节点的span nodes. 其中二叉树边的构建是来自每个叶子节点和它相连的邻居叶子节点和更高层的 span nodes, 与span nodes之间边的连接可以获取更长时间依赖的信息。
下图(a)展示了BP-Transformer的模式图,其中全局节点是分层组织的,任何一对 token 都与二叉树中的路径相连。
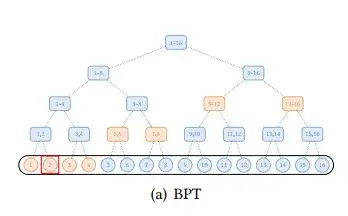
图4 Sparse attentions of BP-Transformer
2.1.2 Content-based Sparse Attention
(1) Reformer[7]
Reformer使用了Locality-sensitive hashing(LSH) 对每个query选择对应的key-value对。
基本思想是,首先利用LSH方程去对query和key做hash,相似的有更高的概率放到相同的buckets中,只对相同hashing bucket里的token做attention的计算。具体来说,LSH方程采用了random matrix方法,假设b为buckets的数量,对于一个random matrix R, 其size 为[Dk, b/2], 那么LSH的计算方法为:
LSH方法只允许第i个query attend 具有相同h值得key-value对。
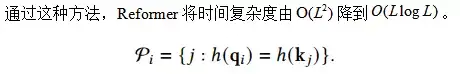
(2) Route Transformer[8]
相比于reformer,该方法采用了k-means聚类的方法对query和key进行聚类,每个query 只attend 属于同一类cluster的keys. 聚类中心的向量根据被赋予向量的指数移动平均值来计算,同时除以cluster中数目的移动平均值,具体计算如下式所示。
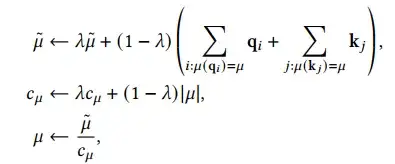
2.2 Linearized attention[9]

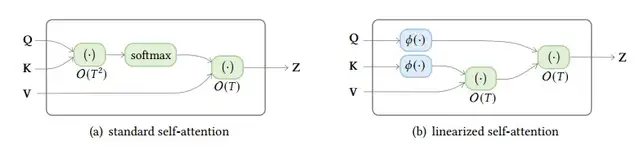
图5 标准self-attention和linearized self-attention的计算复杂度
Attention 计算的一般形式为,
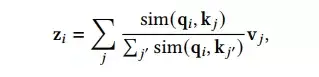
这里可将原始的指数内积的计算形式替换为核函数,从而提出新的计算方式,
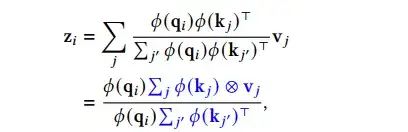
对于自回归的attention而言,上式中的累积和项可以通过上一个时间步的结果计算叠加而来,因此对于transformer的decoder来说,整个计算过程类似于RNN的计算过程。
在Linear Transformer中,linear map采用了一种简单的计算方法,
这种feature map的目的不是为了近似内积attention,但是通过实验证明它和标准的Transformer的结果表象相当。
2.3 Query Prototyping和memory Compression
除了使用sparse attention或者核函数的linearized attention外,另一个改进的思路就是减少query和key-value对的数量。
2.3.1 Query Prototyping
Query Prototyping方法这里主要以informer为例进行介绍。
Informer[10]的主要目标是通过改善自注意力机制的计算和内存开销,从而使得Transformer能够更有效的处理长序列数据。
主要创新点为:


图6 informer的模型示意图
Informer的模型框架图如上图所示。
左:编码器接收大量的长序列输入(绿色序列)。采用ProbSparse attention 来代替常规的self-attention。蓝色梯形是自注意力的蒸馏操作来提取主要的attention,大大减小了网络规模。层叠加复制副本的操作增加了鲁棒性。
右:解码器接收长序列输入,将target中元素填充为零,根据特征图的加权注意力组成,立即以生成方式预测输出元素(橙色系列)
2.3.2 Attention with Compressed Key-Value Memory
相比于减少query数量的方法,这一类方法的主要特点在于通过减少key-value对的数量来减少复杂度。
这一领域较早的尝试来自于Memory Compressed Attention(MCA),它是通过跨步卷积的方法来减少key和value的数量,减少的大小和kernel size k的数值有关,这种方法相比于之前提到局部注意力而言,增加了对全局上下文的捕捉。
Linformer[11] 利用线性投影将键和值从长度n投射到一个更小的长度的nk。这也将self attention的复杂性降低到线性。这种方法的缺点是必须假定输入序列的长度,因此不能用于自回归的问题上。
在最新的研究工作中,由微软提出的PoolingFormer[12] 将原始的全注意力机制修改为一个两级注意力机制:第一级采用滑动窗口注意力机制,限制每个词只关注近距离的邻居;第二级采用池化注意力机制,采用更大的窗口来增加每个token 的感受野,同时利用池化操作来压缩键和值向量,以减少要参加注意力运算的token数量。
这种结合滑动注意力机制和池化注意力机制的多级设计可以显著降低计算成本和内存消耗,同时还能获得优异的模型性能,模型的具体设计如下图所示。
与原始的注意力机制相比,PoolingFormer 的计算和内存复杂度仅随序列长度线性增加。
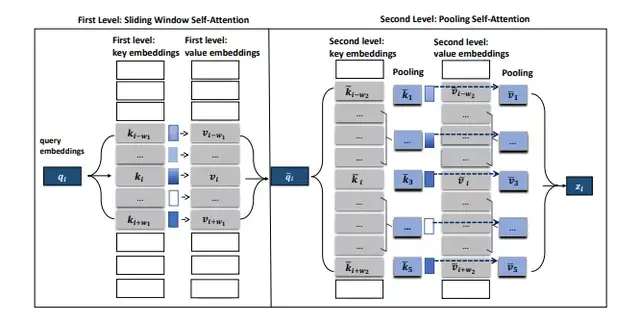
图7 PoolingFormer中两阶段self attention示意图
左边的block是第一级滑动窗口attention,右边的block是第二级的池化attention
实验结果方面,在长文档QA任务上,Poolingformer实现了新的state of art 表现,并且展现出了较强的模型优越性。
2.4 多头机制的改进
多头注意力的一大优势在于它能够共同关注来自不同子空间的不同位置的信息。然而,目前还没有一种机制可以保证不同的注意头确实捕捉了不同的特征。
为此,不同学者在这个问题上提供了两大类改进的思路:


图8 三种span masking 方法
2.5 其他模块级别的改进
2.5.1 Layer Normalization
层归一化(LN)与残差连接被认为是稳定深度网络训练的一种机制(例如,缓解不理想的梯度和模型退化)。因此很多研究将注意力放在分析和改进LN模块,尤其是Layer normalization 放置的位置。
在vanilla Transformer中,LN层位于residual block之间,称为post-LN。后来的Transformer实现将LN层放在注意力或FFN之前的残差连接内,在最后一层之后设置一个额外的LN来控制最终输出的大小,这被称为pre-LN。Pre-LN[15]
已被许多后续的研究和实现所采用,pre-LN和post-LN的区别如图所示
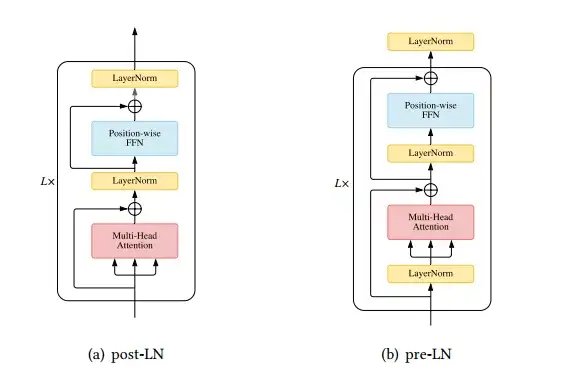
图9 Transformer encoder中 Pre-LN 和post-LN的对比
Xiong等人[16]从理论上研究了tranformer的梯度,并发现在post-LN transformer中,输出层附近的梯度在初始化时很大,这可能是是没有学习率warm-up的post-LN Transformer 训练不稳定的原因。而Pre-LN Transformer则不存在同样的问题。
因此,他们推断并从经验上验证了warm-up阶段在Pre-LN中被去掉。尽管Post-LN经常导致不稳定的训练和发散,但它在收敛后通常优于pre-LN变体。通过理论和实证分析,Post-LN在训练和发散方面的效果要好于pre-LN。
此外,还有学者认为梯度问题不是导致Post-Transformer训练不稳定的直接原因,并且证实了post-LN中存在amplification 效应:在初始化时,对residual分支的依赖性较强,导致post-LN transformer的输出偏移较大,从而导致不稳定的训练。鉴于这一发现,他们引入了额外的参数以控制post-LN对residual的依赖性。
2.5.2 postion-wise的前馈神经网络的改进
尽管FFN的网络形式十分简单,但是却对Transformer的最终结果有重要影响。这里简单总结一下再这模块的改进。
Ø 通过将Transformer中的ReLU激活函数换成Swish 函数,取得了在WMT2014英德数据集上的一致性提升。
Ø GPT在语言的预训练模型中将ReLU替换为Gaussian Error Linear Unit(GELU)。
Ø 使用Gated Linear Units (GLU)替换ReLU,在预训练实验中也取得了更好的效果。
03 框架级别的变体
除了在模块层面为减轻计算开销所做的努力外,还有部分研究试图通过在更高层次上修改即框架上使Transformer成为轻量级的模型。
3.1 轻量化的改进Transformer
Lite Transformer[17]提出用双分支结构替换Transformer中的每个注意力模块,其中一个分支使用attention捕获长距离上下文,而另一个分支使用深度卷积和线性层捕获局部依赖。
该体系结构在模型大小和计算方面都是轻量级的,因此更适合于移动设备。
作为最近的研究成果,更深更轻量的Transformer DeLighT[18]被提出,它能够更有效地在每个Transformer Block中分配参数,这主要体现在:
(1) 在每个blcok中采用深度和轻量的DeLighT 变换。
(2)在block之间使用Block-wise Scaling, 允许在输入附近有较浅和较窄的DeLighT Block,以及在输出附近有较宽和较深的DeLighT Block。
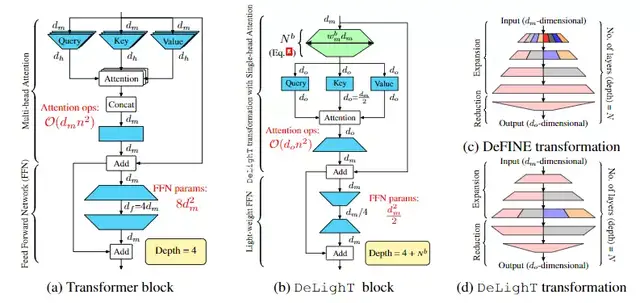
图10 Transformer block 和DeLighT block以及DeFINE 和 DeLighT 变换示意图
如上图所示,DeFINE转换(图10c)和DeLighT转换(图10d)之间的关键区别是,DeLighT转换更有效地在扩展层和简化层中分配参数。
DeFINE在组线性变换中使用更少的组来学习更鲁棒的表征,与之不同的是,DeLighT transformation使用更多的组来学习更广泛的表示,且参数更少。
DeLighT转换获得了与DeFINE转换相当的性能,但参数却少得多。标准的Transformer块如图10(a)所示。DeLighT变换先将维度输入向量映射到高维空间(展开),然后利用N层群变换将其降为维度的输出向量(降阶)。
在expansion-reduction阶段,DeLighT变换使用组线性变换(GLTs),因为它们通过从输入的特定部分导出输出来学习局部表示,比线性变换更有效。
为了学习全局表征,DeLighT变换使用特征变换在组线性变换的不同组之间共享信息,类似于卷积网络中的通道变换。
增加Transformer的表达能力和容量的一种标准方法是增加输入维数。然而,线性增加也会增加标准Transformer块中多线程注意力的复杂度。
与此相反,为了增加DeLighT块的表现力和容量,本文使用expand和reduction阶段来增加中间DeLighT转换的深度和宽度。这使DeLighT能够使用更小的维度和更少的操作来计算注意力。
在expansion阶段,DeLighT transformation将输入投影到高维空间,线性层为N/2层;在reduction阶段,DeLighT变换使用剩余的N−N/2 GLT层将维向量投影到维空间。
总的来说,DeLighT网络的深度是标准Transformer的2.5到4倍,但参数和操作更少。在机器翻译和语言建模任务上的实验表明,DeLighT在提高了基准Transformer性能的基础上,平均减少了2到3倍的参数量。
3.2 自适应计算时间
Vanilla Transformer像大多数模型一样,利用一个固定的或者可学习的计算步骤来处理每个输入。
一种有趣且由前景的改进是在Transformer模型中引入自适应计算时间(Adaptive Computation Time,ACT)使计算时间以输入为条件。
这种修改可能会产生以下优势。
(1)对困难的例子进行特征细化。对于难以处理的数据,浅表征可能不足以完成当前的任务。更理想的做法是应用更多的计算来获得一个更深更精的表征。
(2)简单例子的效率。当处理简单的例子时,一个浅层的表示可能就足以完成任务了。在这种情况下,如果网络能够学会用减少的计算时间来提取特征,并减少计算时间显然更有优势。
Universal Transformer(UT)[19]包含了一个递归-深度机制,它可以反复地迭代地完善所有符号的表示,使用一个深度共享的模块,如图所示(a). 它还增加了一个每个位置的动态停止机制,在每个时间步骤中为每个符号计算一个停止概率。
如果一个符号的停止概率大于一个预定的阈值,那么该符号的表示将在随后的时间步中保持不变。当所有符号都停止时,递归就会停止。递归在所有符号停止或达到预定的最大步长时停止。
条件计算变换器(CCT)[20]在每个自我注意和前馈层增加了一个门控模块。
和前馈层增加一个门控模块,以决定是否跳过当前层,如图(b)所示。作者还引入了一个辅助损失,鼓励模型调整门控模块,使实际计算成本与可用计算预算相匹配.
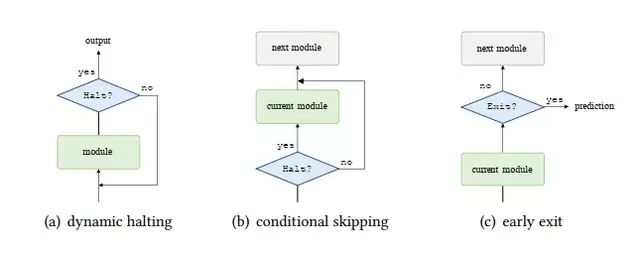
图11 三种典型的ACT 模式
与UT中使用的动态停止机制类似,有一类工作致力于将层数适应于每个输入,以实现良好的速度-精度权衡,这一类方法被称为早退机制,如图11(c)所示。
一个常用的技术是在每层增加一个内部分类器,并联合训练所有的分类器。这些方法的核心是用来决定是否在每一层退出的标准。例如,DeeBERT使用了当前层的输出概率分布的熵来决定是否退出该层。
3.3 使用分治策略的Transformer
处理长序列问题的另一类有效方法是使用分而治之的策略,即把一个输入序列分解成更细的segments,这些segments可以被Transformer或Transformer模块有效处理。
在这里介绍两种有代表性的方法,即递归和分层Transformer,如图12所示。
这类技术可以被理解为Transformer模型的包装,其中Transformer作为一个基本的组件,被重复使用来处理不同的输入segments.
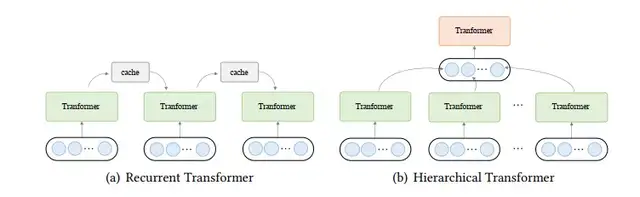
图12 递归和分层 Transformer示意图
Ø 递归Transformer
在递归Transformer中,保留了一个缓存以纳入历史信息。在处理一段文本时,网络从缓存中读取信息作为额外的输入。
在处理完成后,网络通过简单地复制隐藏状态或使用更复杂的机制将信息写入存储器中。
这一过程如图12(a)所示。


Ø 层级Transformers
分层Transformer将输入分层分解为更细粒度的元素。
低级别的特征首先被送入Transformer encoder,产生输出表示,然后汇总(使用池化或其他操作),形成高级别的特征。
高级别的特征然后进一步由高层的transformer处理。这类方法可以理解为一个层次化的抽象过程。
这种方法的概述如上图12(b)。这种方法的优点是双重的。
(1) 分层建模允许模型以有限的资源处理长的输入;
(2) 它有可能产生更丰富的表征,这对任务是有益的。
04 预训练的Transformer
卷积网络和递归网络与Transformer的一个关键区别在于,Transformer不对数据的结构做任何假设,而是将局部的归纳偏差纳入其中。
一方面,这使得Transformer成为了一个非常通用的架构,有可能捕捉到不同范围的依赖关系。
另一方面,这使得当数据有限时,Transformer容易出现过度拟合。缓解这个问题的一个方法是在模型中引入inductive bias。
最近的研究表明,在大型语料库中预先训练的Transformer模型可以学习到通用的语言表征,有利于下游任务的完成。
这些模型使用各种自监督的目标进行预训练,例如,根据其上下文预测一个被mask的单词。在预训练一个模型后,人们可以简单地在下游数据集上对其进行微调,而不是从头开始训练一个模型。
为了说明在预训练中使用transformer的典型方法,本文将其归类如下:
Ø Encoder only。 BERT[22]是一个代表性的PTM,通常用于自然语言理解任务。它利用mask语言建模(MLM)和下句预测(NSP)作为自监督的训练目标。RoBERTa[23]进一步调整了BERT的训练,并删除了NSP目标。因为它被发现会损害下游任务的性能。
Ø Decoder only。专注于对语言建模的Transformer解码器进行预训练。例如,生成性预训练Transformer(GPT)[24]系列。GPT-2[25]和GPT-3[26]致力于扩展预训练的Transformer解码器,并且最近表明,大尺度的PTM可以对few-shot的问题也能有较好的表现。
Ø Encoder-Decoder。BART[27] 将 BERT 的denoising objective扩展到编码器-解码器架构。使用编码器-解码器结构的好处是,使得模型具有同时进行自然语言理解和生成的能力。
在这篇文章中,我们对X-former进行了全面的概述,并提出了一个新的分类方法。
大多数现有的工作从不同的角度改进了Transformer,如效率、泛化和应用等方面。这些改进包括纳入结构先验、设计轻量级架构,预训练等等。尽管X-former已经证明了其在各种任务中的能力,但仍然存在不小的挑战。
除了目前关注的问题(如效率和泛化),Transformer的进一步改进可参考以下几个方向:
(1)理论分析。对Transformer相对于其他模型结构具有更优表现的更深层次的理论分析。
(2)除了attention意外的其他更好的全局交互机制。
(3)对于多模态数据的更加统一的模型架构。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Proceedings of NeurIPS. 5998–6008.
[2] Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, and Zheng Zhang. 2019. Star-Transformer. InProceedings of HLT-NAACL. 1315–1325.
[3] Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The Long-Document Transformer. arXiv:2004.05150.
[4] Joshua Ainslie, Santiago Ontanon, Chris Alberti, Vaclav Cvicek, Zachary Fisher, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang, and Li Yang. 2020. ETC: Encoding Long and Structured Inputs in Transformers. In Proceedings of EMNLP. Online, 268–284.
[5] Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big Bird: Transformers for Longer Sequences. arXiv:2007.14062
[6] Zihao Ye, Qipeng Guo, Quan Gan, Xipeng Qiu, and Zheng Zhang. 2019. BP-Transformer: Modelling Long-Range Context via Binary Partitioning. arXiv:1911.04070.
[7] Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. 2020. Reformer: The Efficient Transformer. In Proceedings of ICLR.
[8] Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. 2020. Efficient Content-Based Sparse Attention with Routing Transformers. arXiv:2003.05997
[9] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. 2020. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In Proceedings of ICML. 5156–5165.
[10] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of AAAI
[11] Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. 2020. Linformer: Self-Attention with Linear Complexity. arXiv:2006.04768
[12] Hang Zhang, Yeyun Gong, Yelong Shen, Weisheng Li, Jiancheng Lv, Nan Duan, and Weizhu Chen. 2021. Poolingformer:Long Document Modeling with Pooling Attention. arXiv:2105.04371
[13] Noam Shazeer, Zhenzhong Lan, Youlong Cheng, Nan Ding, and Le Hou. 2020. Talking-Heads Attention. CoRRabs/2003.02436 (2020). arXiv:2003.02436
[14] Qipeng Guo, Xipeng Qiu, Pengfei Liu, Xiangyang Xue, and Zheng Zhang. 2020. Multi-Scale Self-Attention for Text Classification. In Proceedings of AAAI. 7847–7854.
[15] Alexei Baevski and Michael Auli. 2019. Adaptive Input Representations for Neural Language Modeling. In Proceedings of ICLR
[16] Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. 2020. On Layer Normalization in the Transformer Architecture. In Proceedings of ICML.10524–10533.
[17] Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, and Song Han. 2020. Lite Transformer with Long-Short Range Attention. In Proceedings of ICLR
[18] Sachin Mehta, Marjan Ghazvininejad, Srinivasan Iyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2020. DeLighT: Very Deep and Light-weight Transformer. arXiv:2008.00623
[19] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. 2019. Universal Transformers. In Proceedings of ICLR.
[20] nkur Bapna, Naveen Arivazhagan, and Orhan Firat. 2020. Controlling Computation versus Quality for Neural Sequence Models. arXiv:2002.07106
[21] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, and Ruslan Salakhutdinov. 2019. TransformerXL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of ACL. Florence, Italy, 2978–2988.
[22] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of HLT-NAACL. Minneapolis, Minnesota, 4171–4186.
[23] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692
[24] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training. (2018)
[25] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. (2019).
[26] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan,Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Proceedings of NeurIPS. 1877–1901.
[27] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of ACL. 7871–7880.
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。