(1)万用的hash function
在使用以Hash Table作为底层容器的容器(例如unordered_map)时,为了能够确定容器在Hash Table中的位置,就必须计算其Hash Code。对于自定义的容器类型而言,就必须自定义相对应的Hash Function。
<1>指定自定义的hash function的方法一:
#include
class Customer{
······
}
以上是一个自定义的类,将其作为HashTable的底层容器。利用Hash Function使系统清除怎样把这个类放置在Hash Table的一个具体的位置上。
class CustomerHash
{
public:
std::size_t operator()(const Customer& c) const{
return /*........*/;
}
};
在上述类中,重载了()操作符,由此可以形成一个仿函数。
unordered_set customers; // CustomerHash就是相对应的Hash Function
<2>指定自定义的hash function的方法二:
size_t customer_hash_func(const Customer& c)
{
return ······;
}
unorder_set customers(20, customer_hash_func);
这个方法实际是通过指定了一个函数指针的方式来通知容器,对于这个。自定义类到底应该使用哪个hash function.
<3>指定自定义的hash function的方法三:以struct hash 偏特化形式实现hash function。
class MyString
{
private:
char* _data;
size_t _len;
};
namespace std;
{
template<>
struct hash
{
size_t operatoe()(const MyString& s) const noexcept
{
return hash()(string(s.get()));
}
}
}
对于使用将Hash Code简单相加的方法是不合理的:
class CustomerHash
{
public:
std::size_t operator()(const Customer& c) const{
return std::hash()(c.fname)
+ std::hash()(c.Iname)
+ std::hash 虽然这个方法可以实现计算出Hash code,但是这样计算的hash code的重复概率比较高;而重复的hash code 会导致“bucket”中的元素过多,影响查询的效率。
一个万能的Hash Function:
class CustomerHash
{
public:
std::size_t operator()(const Cunstomer& c) const {
return hash_val(c.fname, c,Iname, c.no);
}
}
其详细代码:
#include
template
inline void hash_combine(size_t& seed, const T& val){
// 利用黄金分割比例
seed = std::hash(val) + 0x9e3779b9
+ (seed << 6) + (seed >> 2);
}
template
inline void hash_val(size_t& seed, const T& val){
hash_combine(seed, val);
}
template
inline void hash_val(size_t& seed, const T& val, const Type&... args){
hash_combine(seed, val);
hash_val(seed, args...);
}
template
inline size_t hash_val(const Types&... args){
size_t seed = 0;
hash_val(seed, args...);
return seed;
}
在上述代码中使用了variadic templates,传入函数中的每个参数都会具备一个模版,也就是说,可能每个参数的类型都会不同,那么应该处理每个不同的参数需要一套对应的解决方案。上述代码就提供这样一种对于不同类型通用的解决方案。
template
inline size_t hash_val(const Types&... args)
可以看作为是一个泛化的版本,因为这里面的模版可以传入任意数量的任意模版类型。
template
inline void hash_val(size_t& seed, const T& val, const Type&... args)
接收的参数的范围是比第一个函数要少的,那么,也就是范围其实先对减小,我们可以把它理解为偏特化的一个过程,也就是在泛化中,调用了偏特化的函数,每次调用其实都会减少模版的数量。
针对于hash_val进行了三次重载,最后一个hash_val只接收一个模版,那么也就是最后的时候会被调用,也就是,通过函数重载和模版特化的过程来一层一层把模版参数的数量解开。最后调用hash_combine的函数来计算出hash code。
hash_combine函数中的处理方式保证了最后的计算结果足够Hash。
(2)tuple
tuple可以存放不同类型的数据。
#include // std::cout
#include // std::tuple, std::get, std::tie, std::ignore
int main()
{
//通过构造函数来创建tuple对象
std::tuple foo(10, 'x');
//通过make_tuple来创建tuple对象,并且可以实现自动类型推到
//实际的类型应该为: tuple
auto bar = std::make_tuple("test", 3.1, 14, 'y');
// 从tuple中获取数据
std::get<2>(bar) = 100; // access element
int myint; char mychar;
//通过tie函数来从tuple中一次性获取所有的数据
std::tie(myint, mychar) = foo; // unpack elements
//也可以通过std::ignore跳过部分不需要的元素,只取出需要的元素
std::tie(std::ignore, std::ignore, myint, mychar) = bar; // unpack (with ignore)
mychar = std::get<3>(bar);
//直接修改其中元素的值
std::get<0>(foo) = std::get<2>(bar);
std::get<1>(foo) = mychar;
std::cout << "foo contains: ";
std::cout << std::get<0>(foo) << ' ';
std::cout << std::get<1>(foo) << '\n';
typedef tuple TupleType;
//获取tuple中的元素个数
cout << tuple_size::value << endl; //3
//获取元素类型
tuple_element<1, TupleType>::type f1 = 1.0; //float
return 0;
}
tuple的实现原理(GNU4.8节选并简化版本):
//只有一个模版参数的版本的特化版本
template class tuple;
//没有模版参数的版本的特化版本
template<> class tuple < > {};
//每次都会继承剔除掉第一个模版参数的class
template
class tuple : private tuple < Tail... >
{
typedef tuple inherited;
public:
tuple();
tuple(Head v, Tail... vtail) :m_head(v), inherited(vtail...){}
typename Head::type head() { return m_head; }
protected:
Head m_head;
};
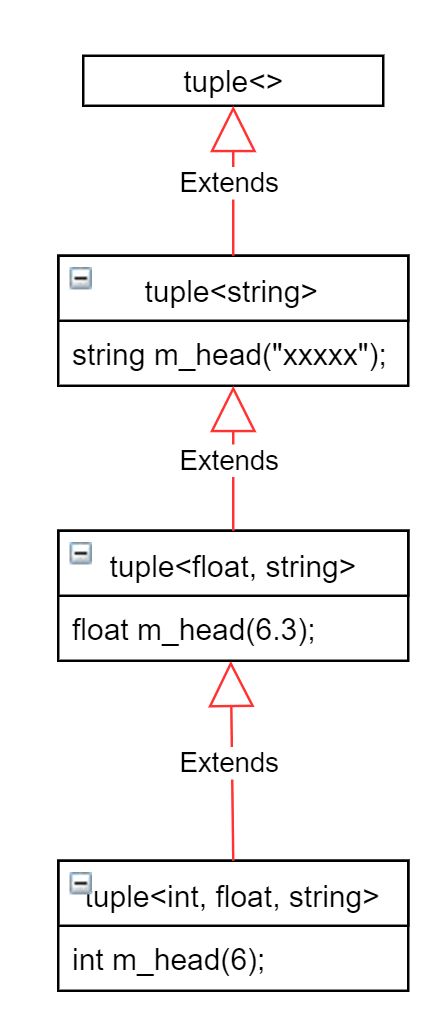
为了能够处理每个不同类型的元素,tuple自动在多个参数之间构建了继承关系。每次继承的都是模版的后半部分,逐渐将第一个模版参数解析出来。在tuple中,head()可以返回第一个元素的值;tail()可以返回父类成分起点,返回类型是父类的类型。
(3)TypeTraits
GNU 2.9版本:
//泛化
template
struct __type_traits{
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type; //POD = Plain Old Data,代表旧式的class 也就是struct
};
//int的特化
template<>
struct __type_traits < int > {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
}
//double的特化
template<>
struct __type_traits < double > {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
}
在上述代码中,通过模板的泛化以及特化机制使得不同的类型进入不同的代码逻辑中。
利用typedef标志类型的特征:是否有默认的构造函数,拷贝构造,赋值构造,析构函数等。
对于自定义的类型,用户需要自己定义相对应的type traits。
从C++2.0 开始,type traits的复杂程度大幅上升。此时不需要再重新定义type traits。
{
std::cout << "int: " << std::is_trivially_copy_constructible::value << std::endl;
}
type_traits的实现:
<1>is_void
//去除const
template
struct remove_const{
typedef _Tp type;
};
template
struct remove_const < _Tp const > {
typedef _Tp type;
};
//volatile
template
struct remove_volotile{
typedef _Tp type;
};
template
struct remove_volotile < _Tp volatile > {
typedef _Tp type;
};
//去除const和volatile
template
struct remove_cv{
typedef remove_const::type>::type type;
};
template
struct __is_void_helper : public false_type{};
template<>
struct __is_void_helper :public true_type{};
//is_void
template
struct is_void:public __is_void_helper::type>::type {}
<2>is_integral
typename
struct __is_integral_helper:public false_type{};
typename<>
struct __is_integral_helper:public true_type{};
typename<>
struct __is_integral_helper:public true_type{};
typename<>
struct __is_integral_helper:public true_type{};
typename<>
struct __is_integral_helper:public true_type{};
template<>
struct __is_integral_helper:public true_type{};
template<>
struct __is_integral_helper:public true_type{};
template<>
struct __is_integral_helper:public true_type{};
template<>
struct __is_integral_helper:public true_type{};
template<>
struct __is_integral_helper :public true_type{};
template<>
struct __is_integral_helper:public true_type{};
//is_integral
template
struct __is_integral:public __is_integral_helper::type>::type{};
<3>is_class, is_union, is_enum, is_pod
//is_enum
template
struct is_enum:public integral_constant < bool, __is_enum(_Tp) > {};
//is_union
template
struct is_union:public integral_constant < bool, __is_union(_Tp) > {};
//is_class
template
struct is_class:public integral_constant < bool, __is_class(_Tp) > {};
//is_pod
//Could use is_standard_layout && is_trivial instead of the builtin.
template
struct is_pod:public integral_constant();
__is_xxx(_Tp)不存在与标准库中,应该是编译器的底层机制。
<4>is_move_assignable
template::value>
struct __is_move_assignable_impl;
template
struct __is_move_assignable_impl<_Tp, false> :public false_type{};
template
struct __is_move_assignable_impl<_Tp, true> :public is_assignable < _Tp&, _Tp&& > {};
template
struct __is_referenceable :public __or_, is_reference<_Tp>>::type
template
struct __is_referenceable<_Res(_Args...)> :public true_type{};
template
struct __is_referenceable<_Res(_Args......)> :public true_type{};
//is_move_assignable
template
struct is_move_assignable :public __is_move_assignable_impl < _Tp > {};
(4)cout
class ostream : virual public ios
{
public:
ostream& operator << (char c);
ostream& operator << (unsigned char c){ return (*this) << (char)c; };
ostream& operator << (signed char c){ return (*this) << (char)c; };
//cout根据操作符重载的方式来使得cout可以接受许多的类型
};
class _IO_ostream_withassign : public ostream
{
public:
_IO_ostream_withassign& operator= (ostream&);
_IO_ostream_withassign& operator=(_IO_ostream_withassign& rhs){
return oprator = (static_cast (rhs);
}
}
extern _IO_ostream_withassign cout;
(5)moveable元素对于容器影响
<1>对vector的影响

在进行数据插入是,vector会进行多次容积增长,其中要调用copy Constructer或move Constructer。有move Constructer的结果会更快。
<2>对list的影响
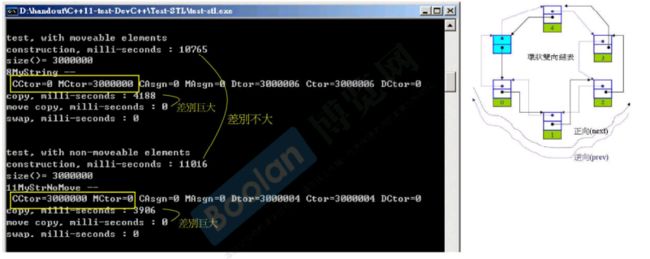
在list的数据插入过程中不存在过多的数据搬移,所以有没有move Constructer对效率差别不大。
同样对于deque、multiset、ubordered_multiset的效率影响也不大。
定义一个moveable class:
class MyString{
public:
static size_t DCtor; //累计调用默认ctor的次数
static size_t Ctor; //累计ctor的调用次数
static size_t CCtor; //累计copy-ctor的调用次数
static size_t CAsgn; //累计copy-asgn的调用次数
static size_t MCtor; //累计move-ctor的调用次数
static size_t MAsgn; //累计move-asgn的调用次数
static size_t Dtor; //累计dtor的调用次数
private:
char* _data;
size_t _len;
void _init_data(const char* s){
_data = new char[_len + 1];
memcpy(_data, s, _len);
_data[_len] = '0';
}
public:
//default ctor;
MyString() :_data(NULL), _len(0){ ++DCtor; }
//ctor
MyString(const char* p) : _len(strlen(p)){
++Ctor;
_init_data(p);
}
//copy ctor
MyString(const MyString& str) : _len(str._len){
++CCtor;
_init_data(str._data);
}
//move ctor, with noexcept
MyString(MyString&& str) noexcept : _data(str._data), _len(str._len){
++MCtor;
str._len = 0;
str._data = NULL; //避免delete(in dtor)
}
//cope assignment
MyString& operator= (const MyString& str){
++CAsgn;
if (this != &str){
if (_data) delete _data;
_len = str._len;
_init_data(str._data);
}
return *this;
}
//move assignment
MyString& operator=(MyString&& str) noexcept{
++MAsgn;
if (this != &str){
if (_data) delete _data;
_len = str._len;
_data = str._data; //move
str._len = 0;
str._data = NULL;
}
return *this;
}
//dtor
virtual ~MyString(){
++Dtor;
if (_data) delete _data;
}
bool operator< (const MyString& rhs) const{
return std::string(this->_data) < std::string(rhs._data);
}
bool operator==(const MyString& rhs) const{
return std::string(this->_data) == std::string(rhs._data);
}
char* get() const { return _data; }
};
size_t MyString::DCtor = 0;
size_t MyString::Ctor = 0;
size_t MyString::CCtor = 0;
size_t MyString::CAsgn = 0;
size_t MyString::MCtor = 0;
size_t MyString::MAsgn = 0;
size_t MyString::Dtor = 0;
namespace std{
template<>
struct hash < MyString > {
size_t operator()(const MyString& s)const noexcept{ return hash()(string(s.get())); }
}
}