0. 背景
论文名称:UNILMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
作者:Hangbo Bao,Li Dong, etc.
机构:Microsoft
面向任务:Natural Language Understanding and Generation
论文代码:https://github.com/microsoft/unilm
0.1. 摘要
本文提出一个能同时处理自编码Autoencoding(AE)和部分自回归Partially Autoregressive(PAR)任务的统一语言模型Language Model(LM),采用了全新的训练过程,称为伪掩码语言模型Pseudo-Masked Language Model(PMLM)。对于给定的带有masked tokens的文本,通过AE,依赖常规掩码conventional masks学习masked tokens与文本的相互关系inter-relations,通过PAR,依赖伪掩码pseudo masks学习masked spans之间的内在关系intra-relations。
通过精心设计的位置嵌入position embeddings和自关注掩码self-attention masks,使得文本编码encoding得以重用,以避免冗余计算。此外,用作AE的conventional masks提供了全局的掩码信息,因此在PAR中可以访问到所有的position embeddings。此外,这两个任务分别将一个统一的语言模型预训练成bidirectional encoder和seq2seq decoder。实验表型,使用PMLM预训练的统一语言模型在广泛的自然语言理解NLU和生成任务NLG中,在广泛的基准上都取得了state-of-the-art的结果。
1. 介绍
在大规模文本集中预训练的语言模型几乎屠榜了所有NLP任务。在预训练之后,通过fine-tune模型可以适应不同的下游任务。
两种语言模型的预训练目标常常被用于预测受制于上下文的单词从而学习语境化的文本表征。第一类工作依赖于AE模型,比如大热的BERT就是通过随机的mask掉文本序列中的一些tokens,通过双向Transformer得到的编码向量恢复被mask掉的tokens。第二类预训练采用AR模型,一个单词的概率不是仅依赖于独立的预测单词,而是还依赖于之前的预测。
本文从UniLM而来,提出了PMLM模型联合训练为了解决NLU问题的bidirectional LM和为了解决NLG问题的seq2seq LM。具体来说,bidirectional LM由AE LM预训练,而seq2seq LM由PAR LM预训练。模型参数在两个LM任务中共享,并且对于给定文本tokens,编码结果是重用的。本文用传统掩码[MASK]([M])来表示为了AE预训练的掩码tokens。为了处理PAR LM的分解步骤,本文在输入序列中附加伪掩码[Pseudo]([M])使得原始tokens不被丢弃。通过精心设计的self-attention masks和position embeddings,PMLM可以在同一个前馈中执行两个LM任务,而不需要对文本进行冗余计算。
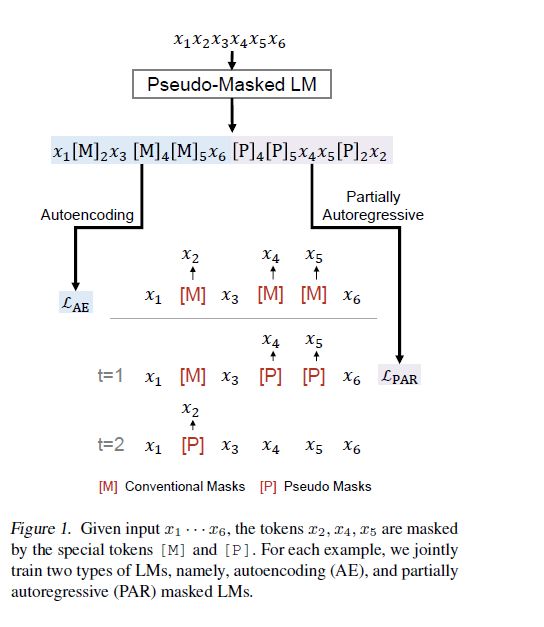
该方法具有如下的优点:
- PMLM用统一的方式预训练不同的LM,这样既能学到masked tokens和文本之间的inter-relations(via AE),也能学到masked spans之间的intra-relations(PAR),此外,用于AE的传统掩码提供了全局掩码信息,这样,PAR预训练的每个分解步骤都可以像在fine-tune中一样访问所有的position embeddings。
- 统一的预训练框架学习自然语言理解和生成模型。具体来说,基于AE的模型是学到了bidirectional Transformer的encoder,而PAR目标预训练seq2seq的decoder。
- 此模型计算效率高,因为AE和PAR模型可以在一个前向过程中进行计算。由于给定文本的编码结果被两个LM任务重用,避免了冗余计算。
- PAR LM在预训练时学到了token-to-token, token-to-span和span-to-span关系。通过段span(i.e., continuous tokens)的引入,PMLM被鼓励学习长距离的依赖关系从而避免local shortcuts。
2. 准备工作
2.1. 主干网络:Transformer
给定输入向量。先将其整理为,再将其输入到一个L层的Transformer网络中对输入进行encode:
其中L是层数。最后一层的隐藏向量是输入文本的语境化表征。在每一个Transformer模块中,多头自注意聚合上一层的所有输出向量,紧接着是一个全连接前馈网络。
自注意掩码 第层 Transformer中某一个self-attention head的输出为:
其中参数是前一层输出到queries, keys, 和values的线性投影参数。特别值得注意的是掩码矩阵控制两个tokens是否可以相互attention。
2.2. 输入表征
格式上与BERT类似,在输入词序列开头加上一个特殊的start-of-sequence token [SOS],用来得到整个输入的表征。此外,每个词序列被特殊的end-of-sequence token [EOS] 分成不同的segments。最终的输入形式是"[SOS] S1 [EOS] S2 [EOS]",这里的S1和S2是连续的文本。其向量表征是token embedding, absolute position embedding和segment embedding的和。所有的embedding vectors都是通过查找可学习矩阵得到的。
3. UniLM预训练
本文提出一个伪掩码语言模型PMLM来联合预训练AE LM和PAR LM。PMLM重用了样例的编码结果,通过伪掩码对两种模型方法进行联合预训练。
3.1. 预训练任务
本文采取完形填空的方法预训练Transformer网络。对于给定的输入,随机用[MASK]替代掉一些tokens,训练目标是通过softmax将Transformer的输出还原被mask掉的真实tokens。本文权衡使用AE和PAR进行预训练,值得注意的是AE和PAR的masked positions是相同的,但概率分解是不同的。
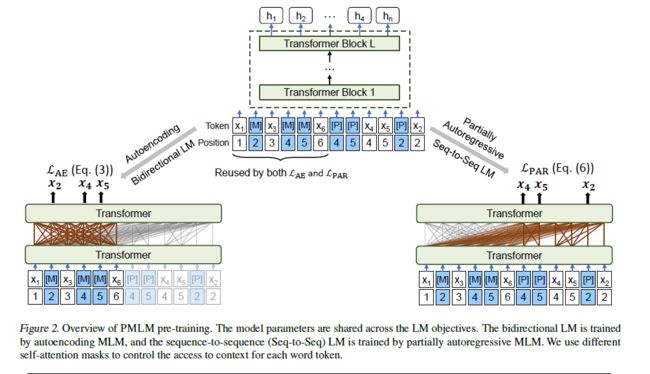
3.1.1. 自编码模型
与BERT相同,AE方法独立的根据上下文预测掩码。对于给定的输入以及掩码位置, 通过计算masked tokens的概率似然,其中。 自编码预训练损失函数定义为:
其中是训练语料库
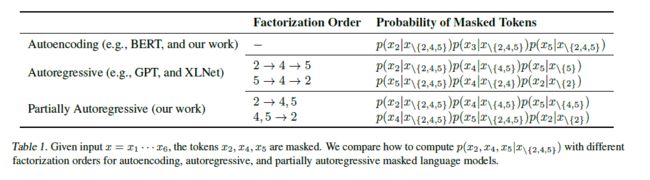
3.1.2. 部分自回归模型
本文提出部分自回归模型,在每一个分解步骤,模型可以预测一个或多个tokens。表示分解序列,其中是第个分解步骤的掩码位置集合。事实上如果所有分解步骤中的都只包含一个掩码,模型就变成了自回归模型AR。本文将每一个分解步骤看成一个span,这样PAR就变成了AR。掩码的概率似然为:
其中, 并且。部分自回归预训练损失函数为:
其中是每一个分解步骤分布的期望。在实际预训练中,对每一个输入文本随机sample一个分解序列而不是计算确切的期望。

掩码块与分解 给定输入序列掩蔽策略统一的产生一个分解序列。对第步分解,掩码位置集合包含一个token或多个连续tokens组成的span。在上图的算法中,随机sample 15% 的原始tokens作为掩码。在这些掩码中,40% 时间mask掉一个-gram block, 60% 的时间只mask一个token。这种随即sample的分解序列很像XLNet使用的基于排列的LM。然而,XLNet只是一个一个的发出预测(AR),而此方法可以在一个分解步骤中生成一个token或一个span(PAR)。
3.2. 伪掩码语言模型PMLM
部分自回归语言模型的分解步骤依赖于不同的上下文,所以如果直接用[MASK],对于每个分解步骤都要重建一个下图所见完形填空的实例,这意味着预训练无法操作。本文提出了新的训练流程伪掩码语言模型PMLM来克服这个问题。

对Table 1中的最后一个例子,下图展示了PMLM是如何计算部分自回归预测的:
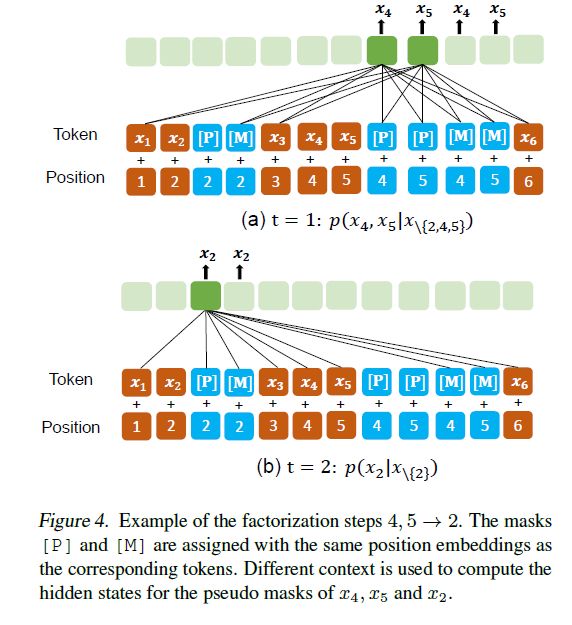
对于每一个masked token,插入一个具有相同position embedding的 [P] token。把隐藏层最顶层的 [P] tokens扔到softmax分类器中做掩码预测。因为Transformer模型是不知道输入序列的位置信息的,位置仅由position embedding编码。也就是说,无论一个token出现在句子中的哪个位置,这个token的位置仅由它的position embedding决定。所以可以把相同的position embedding赋给两个 tokens,这样在Transformer看来,这两个tokens是在同一个位置上的。
Vanilla MLMs允许所有tokens相互attention,然而PMLM根据分解序列控制每个token可以attention的上下文。如上图所示,分解序列是, 当计算时,只有tokens和的伪掩码被考虑其中。的原始tokens被mask掉以防止信息泄露,这时它们的伪掩码[P]被用作masked language model预测的占位符。在第二步中,tokens和的伪掩码被用来计算。与第一步不同的是,的原始tokens也被用来做预测。
自注意掩码被用来在计算语境化表征时控制一个token可以attention哪些文本。下图展示了用在上面样例中的自注意掩码矩阵
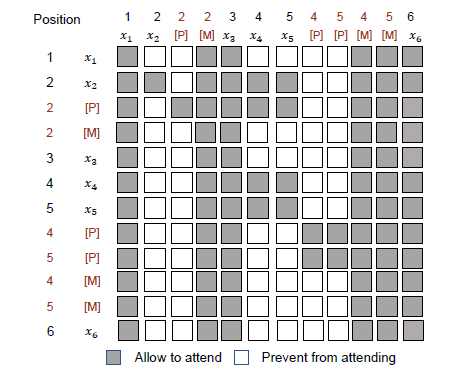
该矩阵被设计用来避免两种信息泄露。第一种是explict leakage(直接泄露),即掩码直接attention到了它的伪掩码,这就让这个语言模型没什么意义了。所以伪掩码不能接触到“自己”的内容。第二种泄露是implict leakage(间接泄露),即多步注意力传播中间接泄露了预测信息。举个例子,如果上图中的文本token 可以连接到 ,那么就存在 ""的attention flow,使得的预测变得十分容易。因此,对于每个token,要mask掉和那些要在将来分解步骤中被预测的tokens的attentions。
3.3. 统一预训练
本文使用相同的输入文本和掩码位置,对bidirectional LM和seq2seq LM进行联合预训练。特殊掩码[M]和[P]都要预测tokens。训练目标是最大化正确tokens的概率似然,也就是说在一个样例中同时考虑两种语言模型。损失函数描述如下:
对于两种语言模型的训练目标,该方法充分重用了计算出的隐藏状态。此外,实验证明了这样设计的预训练任务是相互补足的,既捕捉到了输入文本的inter-relations,也捕捉到了intra-ralations。
3.4. 在NLU任务和NLG任务上的Fine-tune
NLU任务的fine-tune方法与BERT相同,输入样例"[SOS] TEXT [EOS]"用[SOS]的编码向量作为输入文本的表征,让后扔到一个随机初始化的softmax分类器里,通过更新预训练PMLM和softmax classfier的参数来最大化标注好的训练数据的概率似然。
对于seq2seq生成任务,输入样例"[SOS] SRC [EOS] TGT [EOS]"。微调的过程与预训练过程接近,SRC序列是可以随意attention的而TGT序列以自回归的方式生成。因此,为每个目标token都加上伪掩码[P],并使用自注意掩码进行自回归生成,微调目标是最大化给定输入序列中TGT序列的概率似然。值得注意的是[EOS]用来标记TGT序列的结束,一旦[EOS]被抛出,就终止目标序列的生成过程。在解码过程中,使用波束搜索beam search逐个生成目标tokens。
4. 实验结果
4.1. 预训练设置
网络模型与相同,十二层Transformer,每层12头attention隐藏参数为768,前馈网络隐藏参数3072。Softmax分类器的权值矩阵与token embedding matrix挂钩。同时将相对位置偏差加入attention得分。整个模型约包含个参数。
有15%的tokens被mask。在masked tokens中,80%的情况下,使用掩码替换tokens,10%的情况下使用随机tokens,其余时间保留原始tokens。PAR中每一个span最多可以mask掉6个tokens。
超参数等设置详见原文。
4.2. 实验结果
见下图:
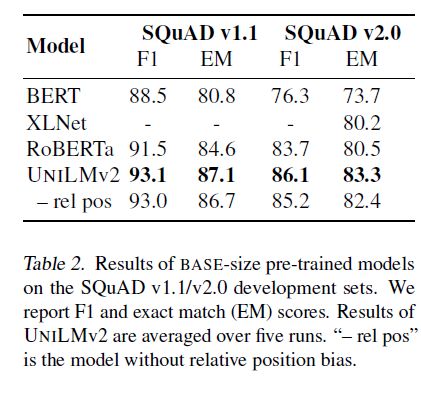
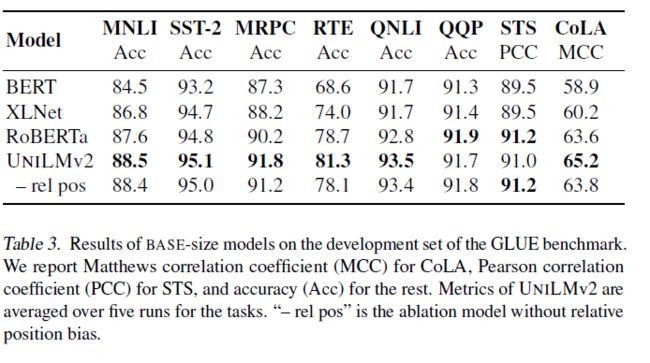
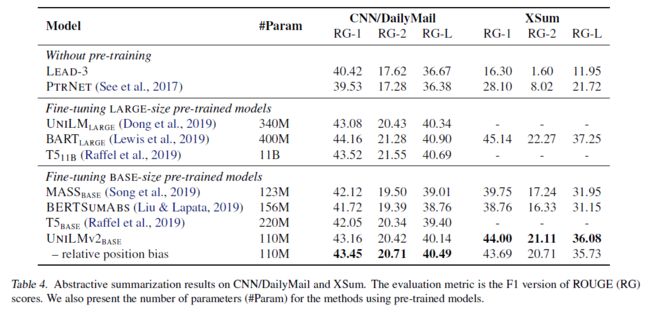
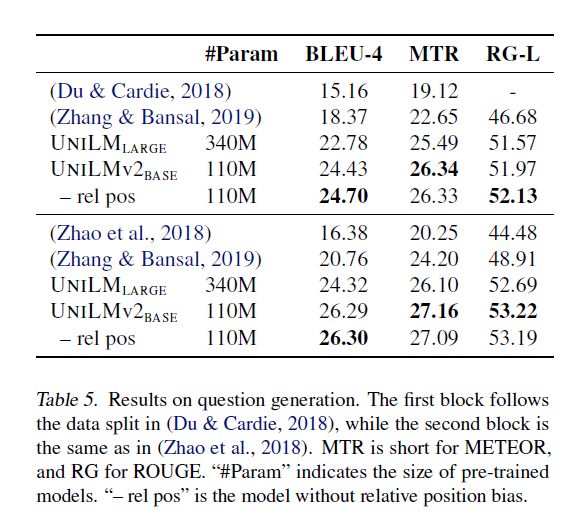
可以看到在自然语言理解和自然语言生成生成的大多数基准任务上都取得了SOTA的结果
4.3. 预训练目标的效果
本文进行了消融研究,对PMLM模型设置不同的预训练目标,如下图:
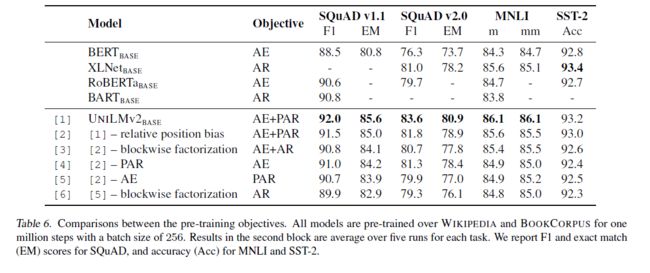
在文本分类任务上(MNLI和SST-2),纯PAR相较于纯AE和纯AR有更好的性能,说明了PAR模型的有效性。相比之下,问答任务(SQuAD)为了从输入文本提取答案,需要对span进行更精确的建模。纯AE和纯PAR都优于纯AR。结果说明了掩码块和分解步骤对语言模型的预训练十分重要。
此外结合多种目标,在五种方式里AE+PAR取得了最佳效果,说明在与训练中autoencoding模型和partially autoregressive模型是互补的。
5.结论
通过联合学习bidirectional LM(AE)和seq-seq LM(PAR),本文预训练了一个统一的语言模型,用于语言理解和生成。提出了一种伪掩码语言模型(PMLM),有效地实现了统一的预训练过程。PMLM的计算效率很高,因为AE和PAR可以在一次前馈过程中进行计算,而不需要进行冗余计算。此外,这两个建模任务是互补的。由于AE的传统掩码提供了全局的掩码信息,因此PAR可以学习spans之间的相互关系。此外,本文的PAR预训练通过防止local shortcuts来鼓励学习远程依赖关系。实验结果表明,PMLM提高了多种语言理解和生成基准的最终结果。