1.什么是Unicode?
unicode官网的简介
The Unicode Standard provides a unique number for every character,
no matter what platform, device, application or language.
Unicode给每一个符号都给予一个独一无二的编码。
2.Unicode问题
阮一峰 字符编码笔记:ASCII,Unicode 和 UTF-8有清晰的介绍:
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
这里就有两个问题:
- 第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
3.Unicode 的多种存储方式(表示方式)
官网的UTF-8, UTF-16, UTF-32 & BOM介绍
there are several possible representations of Unicode data, including
UTF-8, UTF-16 and UTF-32. In addition, there are compression
transformations such as the one described in the UTS #6: A
Standard Compression Scheme for Unicode (SCSU).
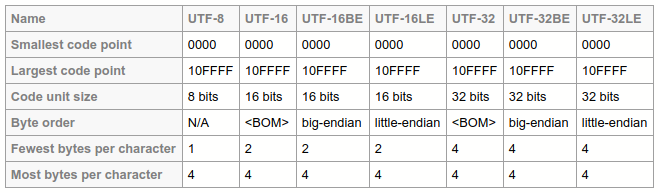
什么是UTF?
A Unicode transformation format (UTF) is an algorithmic mapping
from every Unicode code point (except surrogate code points) to a
unique byte sequence. The ISO/IEC 10646 standard uses the term
“UCS transformation format” for UTF; the two terms are merely
synonyms for the same concept.
Each UTF is reversible, thus every UTF supports *lossless round
tripping*: mapping from any Unicode coded character sequence S to
a sequence of bytes and back will produce S again. To ensure round
tripping, a UTF mapping *must* map all code points (except
surrogate code points) to unique byte sequences. This includes
reserved (unassigned) code points and the 66 noncharacters
(including U+FFFE and U+FFFF).
The SCSU compression method, even though it is reversible, is not
a UTF because the same string can map to very many different byte
sequences, depending on the particular SCSU compressor.
UTF是将每个Unicode码点转换成唯一字节序列的映射算法。ISO/IEC 10646 标准定义UTF为“UCS transformation format” 。
每个UTF都是可逆的。UTF映射必须将所有码点映射到唯一字节序列,包括保留码点(未分配)和66个非字符(包括U+FFFE和U+FFFF)。
3.1 UTF-8
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
参见Section 3.9, Unicode Encoding Forms
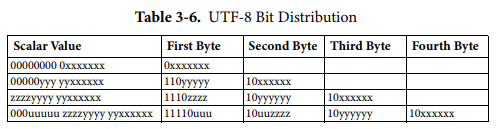
另外参考RFC3629一张图:
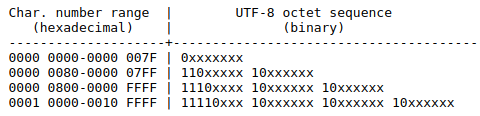
阮一峰 字符编码笔记:ASCII,Unicode 和 UTF-8介绍的一个示例:
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
3.2 UTF-16
参考彻底弄懂 Unicode 编码以及《Java核心技术 卷一》。
3.2.1 级别plane
分区定义。每个区可以存放 65536 个(2^16)字符,称为一个plane。
总共17个编码级别:
- 最前面的 65536 个字符位,称为基本级别(简称 BMP ),它的码点范围是从 0 到 2^16-1,写成 16 进制就是从 U+0000 到 U+FFFF。所有最常见的字符都放在这个级别,这是 Unicode 最先定义和公布的一个级别。
- 剩下的16个级别:字符都放在辅助级别(简称 SMP ),码点范围从 U+010000 到 U+10FFFF。
3.2.2 UTF-16编码规则
- 基本级别(U+0000 到 U+FFFF)的字符占用 2 个字节
- 辅助级别(U+010000 到 U+10FFFF)的字符占用 4 个字节
3.2.3 遇到两个字节时怎么区分是基本级别还是辅助级别?
在基本级别内,从 U+D800 到 U+DFFF 是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助级别的字符。
- U+010000 到 U+10FFFF总共可以表示2^20个不同字符,因此这些字符至少需要20个二进制位。
- UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF,称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF,称为低位(L)。这意味着,一个辅助级别的字符,被拆成两个基本级别的字符表示。
因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解读。
3.2.4 示例
汉字""的 Unicode 码点为 0x20BB7,该码点显然超出了基本平面的范围(0x0000 - 0xFFFF),因此需要使用四个字节表示。
- 首先用 0x20BB7 - 0x10000 计算出超出的部分
- 然后将其用 20 个二进制位表示(不足前面补 0 ),结果为0001000010 1110110111。
- 接着,将前 10 位映射到 U+D800 到 U+DBFF 之间,后 10 位映射到 U+DC00 到 U+DFFF 即可。U+D800 对应的二进制数为 1101100000000000,直接填充后面的 10 个二进制位即可,得到 1101100001000010,转成 16 进制数则为 0xD842。同理可得,低位为 0xDFB7。因此得出汉字""的 UTF-16 编码为 0xD842 0xDFB7。
4. BE, LE and unmarked
官网的UTF-8, UTF-16, UTF-32 & BOM介绍
UTF-16 and UTF-32 use code units that are two and four bytes long
respectively. For these UTFs, there are three sub-flavors: BE, LE and
unmarked. The BE form uses big-endian byte serialization (most
significant byte first), the LE form uses little-endian byte serialization
(least significant byte first) and the unmarked form uses big-endian
byte serialization by default, but may include a byte order mark at the
beginning to indicate the actual byte serialization used.
- BE—— big-endian 高位在前 字节序列
- LE——little-endian低位在前 字节序列
- unmarked form——默认是BE方式,但是可能在最开始处有一个字节序列标记用来标识实际使用的是哪种顺序。