《全网最强》详解机器学习分类算法之决策树(附可视化和代码)
目录
走进决策树
案例一
案例二
灵魂的树
决策树的选择机制
节点纯度的度量规则
纯度的度量方法
决策树算法背景介绍
信息(Information)和信息的量化
信息熵(Information Entropy)
条件熵(Conditional Entropy)
信息增益(Information Gain,ID3算法使用)
信息增益总结
基尼指数(Gini Index,CART算法使用)
代码实现
特征的重要性
参数splitter
剪枝参数
代码案例
手动对max depth 进行调参
min_impurity_decrease调参
网格搜索
带入最佳参数进行训练
决策树模型特征选取
相关系数
轻量级的高效梯度提升树特征选取
再次带入模型进行训练
决策树可视化
ROC曲线AUC
总结
每文一语
走进决策树
决策树是广泛用于分类和回归任务的模型。本质上,它从一层层的 if/else 问题中进行学习,并得出结论。
说到决策树,那么最容易想到的就是在程序语言中的条件判断语句,if and else 可谓是是决策树的本质。
下面通过两个案例对其进行本质的剖析:
案例一
想象一下,你想要区分下面这四种动物:熊、鹰、企鹅和海豚。你的目标是通过提出尽可能少的 if/else 问题来得到正确答案。你可能首先会问:这种动物有没有羽毛,这个问题会将可能的动物减少到只有两种。如果答案是“有”,你可以问下一个问题,帮你区分鹰和企鹅。例如,你可以问这种动物会不会飞。如果这种动物没有羽毛,那么可能是海豚或熊,所以你需要问一个问题来区分这两种动物——比如问这种动物有没有鳍。

在这张图中,树的每个结点代表一个问题或一个包含答案的终结点(也叫叶结点)。树的边将问题的答案与将问的下一个问题连接起来。用机器学习的语言来说就是,为了区分四类动物(鹰、企鹅、海豚和熊),我们利用三个特征(“有没有羽毛”“会不会飞”和“有没有鳍”)来构建一个模型。我们可以利用监督学习从数据中学习模型,而无需人为构建模型。
案例二
理想总是很美好,但是现实确实很骨感。随着中国人口比例失衡,很多适龄青年都会面对一个严峻的考验,那就是“择偶”,正所谓“你在桥上看风景,看风景的人在看你”,那么多少人在进行另一半的寻找的时候,会考虑什么因素呢?下面看一张决策树的现象图:
你是否也是上述的标准呢?
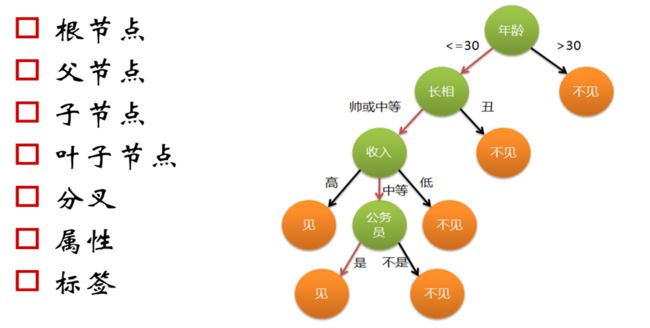
灵魂的树
在编程中, if-else所依赖的判断条件是由程序员来填写,但在机器学习里,我们能做的只有两件事,第一件事是选择模型,第二件事是往模型“嘴”里塞数据,剩下的就只能坐在一旁干着急。上面这棵可以决策的树得依靠我们把判别条件填进去,它要想成为真正的决策树,就得学会怎样挑选判别条件。这是决策树算法的灵魂,也是接下来需要重点探讨的问题。
第一个要紧问题就是:判别条件从何而来呢?分类问题的数据集由许多样本构成,而每个样本数据又会有多个特征维度,譬如学生资料数据集的样本就可能包含姓名、年龄、班级、学号等特征维度,它们本身也是一个集合,我们称为特征维度集。数据样本的特征维度都可能与最终的类别存在某种关联关系,决策树的判别条件正是从这个特征维度集里产生的。
部分教材认为只有真正有助于分类的才能叫特征,原始数据里面的这些记录项目只能称为属性(Attribute),而把特征维度集称为属性集,所以在这些教材中,决策树是从称为树形集的集合中选择判别条件。这里为了保持本书用语的连贯性,我们仍然称之为“特征维度”。当然,这只是用语习惯上的不同,在算法原理上是没有任何区别的。
决策树的选择机制
活经验告诉我们:挑重要的问题先问。决策树也确实是按这个思路来选择决策条件的。思考这个问题,可以从“怎样才算是好的决策条件”开始。决策树最终是要解决分类问题,那么最理想的情况当然是选好决策条件后,一个if-else就正好把数据集按正类和负类分成两个部分。
不过,现实通常没有“一刀切”这么理想,总会有一些不识时务的样本“跑”到不属于自己的类别里,我们退而求其次,希望分类结果中这些不识时务的杂质越少越好,也就是分类结果越纯越好。
依照这个目标,决策树引入了“纯度”的概念,集合中归属同一类别的样本越多,我们就说这个集合的纯度越高。每一次使用if-else进行判别,二元分类问题的数据集都会被分成两个子集,那么怎么评价分类的效果呢?可以通过子集的纯度。子集纯度越高,说明杂质越少,分类效果就越好。
节点纯度的度量规则
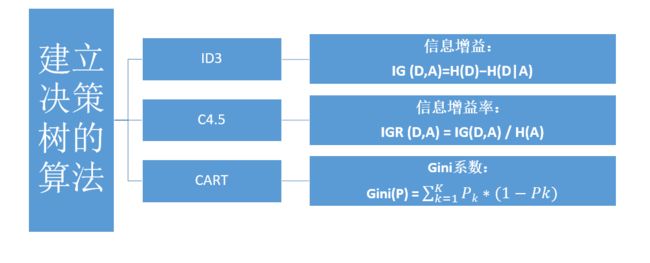
使用决策树这套框架的分类算法有很多,其中最著名的决策树算法一共有三种,分别是ID3、C4.5和CART,这三种决策树算法分别采用了信息增益、增益率和基尼指数这三种不同的指标作为决策条件的选择依据。
虽然三种决策树算法分别选择了三种不同的数学指标,但这些指标都有一个共同的目的:提高分支下的节点纯度(Purity)。
决策树算法中使用了大量二叉树进行判别,在一次判别后,最理想的情况就是二叉树的一个分支纯粹是正类,另一个分支纯粹是负类,这样就意味着完整和准确地完成了一次分类。但大多数的判别结果都没有这么理性,所以一个分支下会既包含正类又包含负类,不过我们希望看到的是一个分支包含的样本尽可能地都属于同一个类,也就是希望这个分支下面的样本类别越纯越好,所以用了“纯度”来进行描述。纯度有三点需要记住:
当一个分支下的所有样本都属于同一个类时,纯度达到最高值。
当一个分支下样本所属的类别一半是正类一半是负类时,纯度取得最低值。
纯度考察的是同一个类的占比,并不在乎该类究竟是正类还是负类,譬如某个分支下无论是正类占70%,还是负类占70%,纯度的度量值都是一样的。
纯度的度量方法
我们的任务就是要找到一种满足纯度达到最大值和最小值条件的纯度度量函数,它既要满足这三点需求,又要能作为量化方法。
现在让我们把这三点要求作成图像(可视化的图像有助于更直观地理解),同时,如果我们能够找到一款函数符合这个图像,就等于找到了符合条件的函数。我们约定所作图像的横轴表示某个类的占比,纵轴表示纯度值,首先来分析极值点的位置。
根据第一点要求,某个类占比分别达到最大值和最小值时,纯度达到最高值。最大值好理解,为什么最小值也能令纯度达到最高?可以反过来想,这个类取得最小值时,另一个类就取得了最大值,所以纯度也就最高。根据分析,我们知道了纯度将在横坐标的头尾两个位置达到最大值。
根据第二点要求,纯度的最小值出现在某个类占比为50%的时候。换句话说,当横坐标为0.5时,纯度取得最低值。
现在可以作出图像了。根据上述分析的纯度最高值和最低值随类占比的变化情况,我们用一条平滑的曲线连接起这三个点,则所作出来的图像应该类似一条微笑曲线
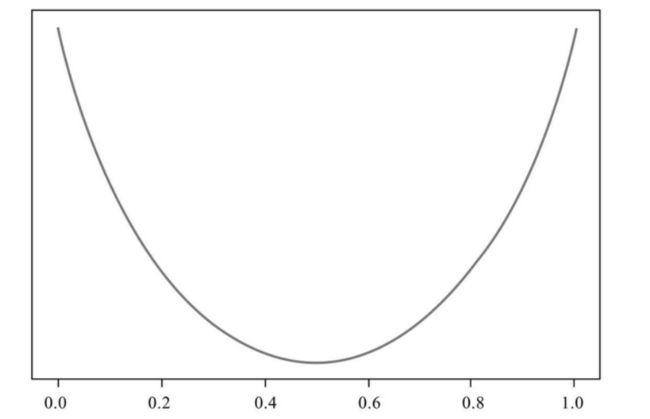
不过我们在机器学习中更喜欢计算的是“损失值”,那么对纯度度量函数的要求正好与纯度函数的要求相反,因为纯度值越低意味着损失值越高,反之则越低。所以纯度度量函数所作出来的图像正好相反
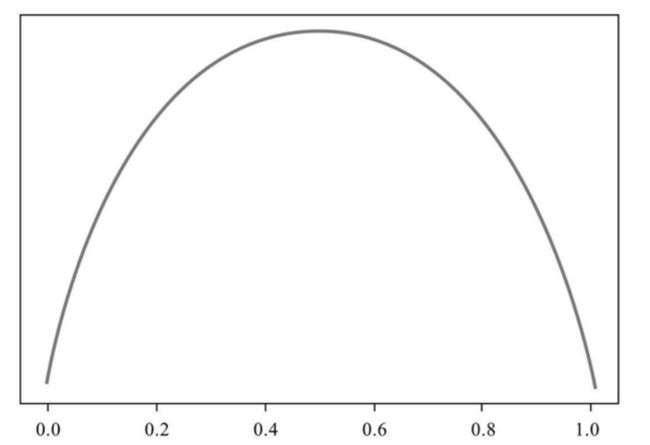
决策树算法背景介绍
最早的决策树算法是由Hunt等人于1966年提出的CLS。后来的决策树算法基本都是基于Hunt算法框架的改进。
当前最有影响力的决策树算法是Quinlan于1986年提出的ID3和1993年提出的C4.5(现在已经进化到C5.0),以及BFOS(Breiman、Friedman、Olshen、Stone)四位学者于1984年提出的CART算法。
追溯其原理,决策树的算法原理就是如此的清晰 ,建立决策树的关键,即在当前状态下选择哪个属性作为分类依据

信息(Information)和信息的量化
假设:X为某随机变量,xi表示X的某个取值,p(xi) 指当X=xi的概率,I(X=xi)表示X=xi的信息量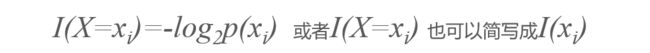
该函数满足: 当一个事件发生的概率越大(确定性越大), 它所携带的信息量就越小, 反之, 当一个事件发生的概率越小(确定性越小), 它所携带的信息量就越大。
1. 当小概率事件发生时, 我们才会感觉’信息量大’
2. 当大概率事件发生时, 我们会感觉’理所应当’, ‘信息量小-正常操作’
也就是越容易发生的事件,那么它所携带的信息量就越小,因为不需要去寻找这些多因素
信息熵(Information Entropy)
熵(Entropy): 事件不确定性的度量
信息熵: 实质上就是对事件的不确定性程度的度量,也可以理解为一个事件集的平均信息量
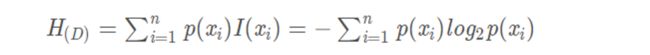
例如:已知小明及格的概率为0.2, 不及格的概率为0.8, 那么小明成绩的不确定性如何度量呢?
H(小明成绩)=−0.2∗(log20.2)+(−0.8∗(log20.8))=0.7219
这就是信息熵的公式,那么假如小明的及格的概率是:0.5,不及格的概率也是:0.5,那么它的信息熵就是:1
条件熵(Conditional Entropy)
条件熵:是为解释信息增益而引入的概念,即在给定条件X的情况下Y的信息熵。以下是公式定义:
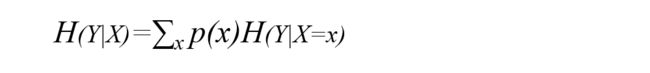
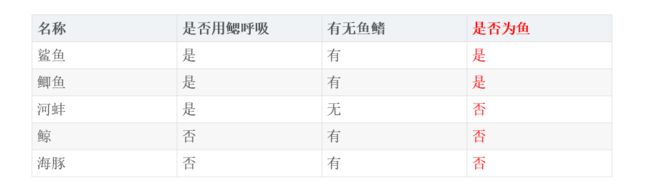
这是一个典型的二分类问题:是否为鱼
信息熵:H(是否为鱼)=-P(是鱼)*log2P(是鱼)-P(不是鱼)*log2P(不是鱼)=-2/5*log22/5-3/5*log23/5=0.971
条件熵:H(是否为鱼|是否用鳃呼吸)=P(用鳃呼吸)*H(是否为鱼|用鳃呼吸)+P(不用鳃呼吸)*H(是否为鱼|不用鳃呼吸)=3/5*(-2/3*log22/3-1/3*log21/3)+2/5(0-1log21)=0.551
H(是否为鱼|是否有鳍)=P(有鳍)*H(是否为鱼|有鳍)+P(没有鳍)*H(是否为鱼|没有鳍)=4/5*(-1/2*log21/2-1/2*log21/2)+1/5(0-1log21)=0.8
信息增益(Information Gain,ID3算法使用)
信息增益: 事件中某一影响因素的不确定性度量对事件信息不确定性减少的程度,即得知特征X的信息而使得类Y的信息不确定性减少的程度。
如果H(D)为集合D的信息熵,H(D|A)为集合D在特征A下的条件熵,则信息增益可表述为如下数学公式:
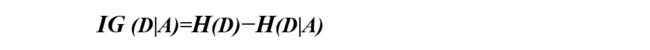
即集合D的信息熵H(D)与D在特征A下的条件熵H(D|A)之差
ID3算法中选取最优分裂属性的策略
首先计算未分裂前当前集合D的信息熵H(D)
然后计算当前集合D对所包含的所有属性A的条件熵H(D|A)
然后计算每个属性的信息增益IG(D|A):
IG (D|A)=H(D)−H(D|A)
选取信息增益最大的属性AIG=max作为决策树进行分裂的属性
信息增益总结
优点:
1)考虑了特征出现与不出现的两种情况,比较全面。
2)使用了所有样例的统计属性,减小了对噪声的敏感度。
3)容易理解,计算简单。
缺点:
1)信息增益考察的是特征对整个系统的贡献,没有到具体的类别上,所以一般只能用来做全局的特征选择,而没法针对单个类别做特征选择
2)算法天生偏向选择分支多的属性,容易导致过拟合(overfitting)
极端的例子:如果ID被当成一个属性,那么ID属性的信息增益会最大。因为按照ID划分数据集合可以得到最纯的子集,即每一个ID所在样例都会归属于单一类别,故其条件熵为0。
信息增益率: 因为信息增益会倾向于取值最多的属性,会导致过拟合问题,所以需要引入一个惩罚参数,即数据集D以特征A作为随机变量的信息熵的倒数:

存在与信息增益相反的缺点,即偏向于取值最少的属性,因为属性A取值越少,H(A)也越小,导致IGA(D|A)越大。
基尼指数(Gini Index,CART算法使用)
基尼指数: 是一种与信息熵类似的做特征选择的指标,可以用来表征数据的不纯度。其计算公式为:
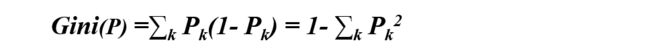
1、Pk表示选中的样本属于k类别的概率,不属于K类别的概率则为(1− Pk)
2、样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3、当为二分类时,Gini(p)=2p(1−p)
基尼指数解读
基尼指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之集合越不纯。即:基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
样本集合D的Gini指数:假设集合中有K个类别,则:
![]()
基于特征A划分样本集合D之后的基尼指数:
![]()
CART算法中选取最优分裂属性的策略
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合时只会有两个子集合:1. 等于给定的特征值的样本集合D1 ;2. 不等于给定的特征值的样本集合D2。CART二叉树实际上是对拥有多个取值的特征的二值处理。
首先对样本集合D包含的每个特征属性A根据其取值构造系列二分子集
然后计算D基于该属性A的每一种取值划分所获得的二分子集的Gini指数
然后选取Gini指数最小的属性取值作为最优划分点
重复上述过程
代码实现
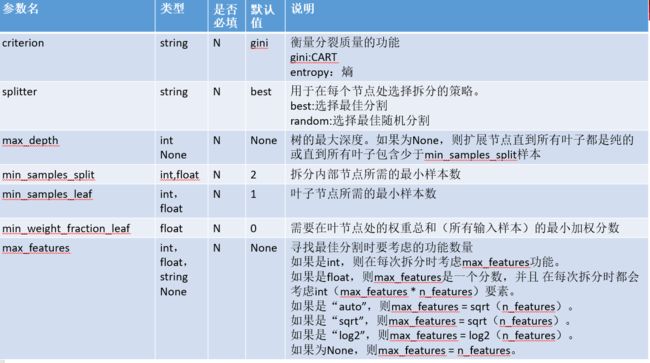
参数介绍
sklearn.tree.DecisionTreeClassifier(
criterion=’gini’,
splitter=’best’,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
class_weight=None,
presort=False)
特征的重要性
前期我们也介绍了,特征选取的重要性,详情点击下面的文章即可查看详细的解说:
特征选取之单变量统计、基于模型选择、迭代选择
clf.feature_importances_ 返回特征的重要性 以后可以用决策树对特征进行选择
我通过反复的的测试和迭代,发现决策树选好特征数量,可以高效的提升模型的效果和各项评估指标,前面的KNN算法,我们通过了特征选取之后,反而对模型的效果造成了干扰,但是决策树不一样。
机器学习需要灵活的转变,不一定是按照某一种固定的思维来,比如网格搜索出来的参数一定是完美的吗?不一定哦,有时手动调参出来的参数,比网格搜索要好,因为网格搜索一般加入了一些不需要的参数进去。
参数splitter
- splitter也是用来控制决策树中的随机选项的,有两种输入值:
- 输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看)
- 输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这也是防止过拟合的一种方式。
- 当你预测到你的模型会过拟合,用splitter和random_state这两个参数来帮助你降低树建成之后过拟合的可能性。
剪枝参数
- 在不加限制的情况下,一棵决策树会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。这样的决策树 往往会过拟合,这就是说,它会在训练集上表现很好,在测试集上却表现糟糕。我们收集的样本数据不可能和整体 的状况完全一致,因此当一棵决策树对训练数据有了过于优秀的解释性,它找出的规则必然包含了训练样本中的噪 声,并使它对未知数据的拟合程度不足。
- 为了让决策树有更好的泛化性,我们要对决策树进行剪枝。剪枝策略对决策树的影响巨大,正确的剪枝策略是优化 决策树算法的核心。sklearn为我们提供了不同的剪枝策略:
- max_depth:限制树的最大深度,超过设定深度的树枝全部剪掉
- 这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所 以限制树深度能够有效地限制过拟合。在集成算法中也非常实用。实际使用时,建议从=3开始尝试,看看拟合的效 果再决定是否增加设定深度。
- min_samples_leaf & min_samples_split:
- min_samples_leaf限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分 枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生。一般搭配max_depth使用。这个参数的数量设置得太小会引 起过拟合,设置得太大就会阻止模型学习数据。一般来说,建议从=5开始使用。
- min_samples_split限定,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则 分枝就不会发生。
代码案例
导入第三方库
#导入所需要的包
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV #网格搜索
import matplotlib.pyplot as plt#可视化
import seaborn as sns#绘图包初次导入数据,不加入任何参数进行训练
# 加载模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
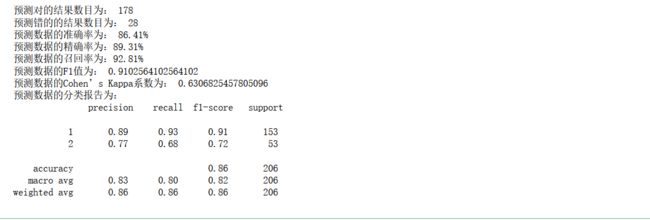
print('预测数据的分类报告为:','\n',
classification_report(y_test,y_pred))
效果一般般,下面进行改进措施
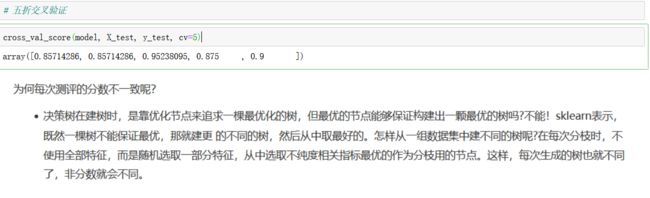
手动对max depth 进行调参
def cv_score(d):
clf = DecisionTreeClassifier(max_depth=d)
clf.fit(X_train, y_train)
return(clf.score(X_train, y_train), clf.score(X_test, y_test))
depths = np.arange(1,10)
scores = [cv_score(d) for d in depths]
tr_scores = [s[0] for s in scores]
te_scores = [s[1] for s in scores]
# 找出交叉验证数据集评分最高的索引
tr_best_index = np.argmax(tr_scores)
te_best_index = np.argmax(te_scores)
print("bestdepth:", te_best_index+1, " bestdepth_score:", te_scores[te_best_index], '\n')
# 可视化
%matplotlib inline
from matplotlib import pyplot as plt
depths = np.arange(1,10)
plt.figure(figsize=(6,4), dpi=120)
plt.grid()
plt.xlabel('max depth of decison tree')
plt.ylabel('Scores')
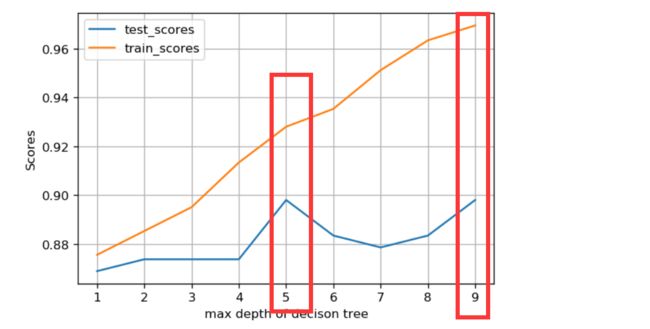
plt.plot(depths, te_scores, label='test_scores')
plt.plot(depths, tr_scores, label='train_scores')
plt.legend()
取到5和9的时候,看起来还不错,但是一般是不会取到9,因为可能会造成过拟合
下面对其中的某一个参数进行调优,主要是介绍这种思想
min_impurity_decrease调参
def minsplit_score(val):
clf = DecisionTreeClassifier(criterion='gini',max_depth=5, min_impurity_decrease=val)
clf.fit(X_train, y_train)
return (clf.score(X_train, y_train), clf.score(X_test, y_test), )
# 指定参数范围,分别训练模型并计算得分
vals = np.linspace(0, 0.2, 100)
scores = [minsplit_score(v) for v in vals]
tr_scores = [s[0] for s in scores]
te_scores = [s[1] for s in scores]
bestmin_index = np.argmax(te_scores)
bestscore = te_scores[bestmin_index]
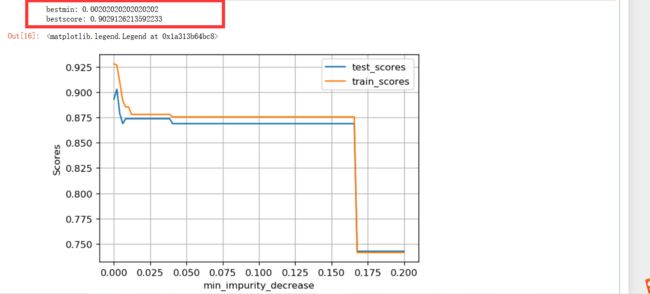
print("bestmin:", vals[bestmin_index])
print("bestscore:", bestscore)
plt.figure(figsize=(6,4), dpi=120)
plt.grid()
plt.xlabel("min_impurity_decrease")
plt.ylabel("Scores")
plt.plot(vals, te_scores, label='test_scores')
plt.plot(vals, tr_scores, label='train_scores')
plt.legend()
这里看起来效果有了提升
通过手动调参,主要确定了两个参数的范围
网格搜索
import numpy as np from sklearn.model_selection import GridSearchCV parameters = {'splitter':('best','random') ,'criterion':("gini","entropy") ,"max_depth":[np.arange(4,10,1)] ,"max_depth":[*range(1,10)] ,'min_samples_leaf':[*range(1,50,5)] } clf = DecisionTreeClassifier(random_state=25) GS = GridSearchCV(clf, parameters, cv=5) # cv交叉验证 GS.fit(X_train,y_train) GS.best_params_
又确定了几个主要的参数

带入最佳参数进行训练
# 加载模型
model = DecisionTreeClassifier(criterion='gini',max_depth=5, splitter= 'random')
# 训练模型
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\n',
classification_report(y_test,y_pred))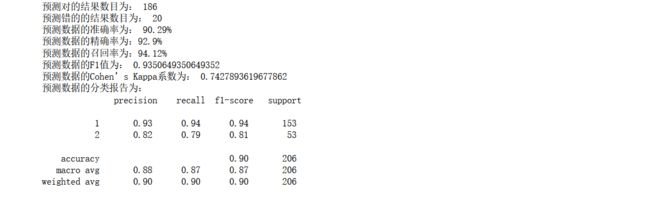
效果还是一般,总的来说有了提升,但是不够明显,需要进一步
下面进行特征选取,在决策树里面,特征选取重要性还是比较的强,下面进行多方面的特征选取,看看是否可以提升模型的效果
决策树模型特征选取
feature_weight = model.feature_importances_
feature_name = df.columns[:-1]
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
plt.figure(figsize=(10,8))
sns.barplot(feature_sort.values,feature_sort.index, orient='h')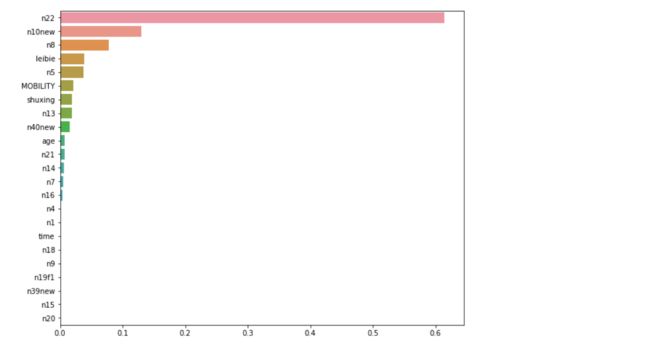
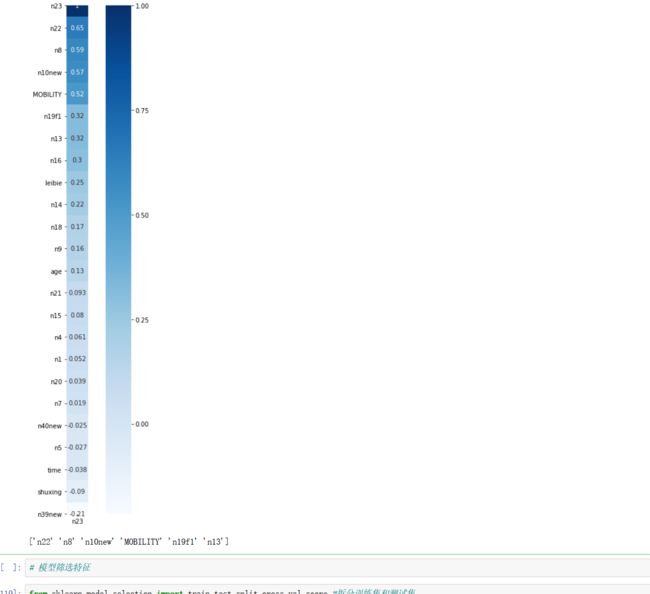
相关系数
plt.subplots(figsize=(10, 15))
sns.heatmap(df.corr()[['n23']].sort_values(by="n23",ascending=False), annot=True, vmax=1, square=True, cmap="Blues")
plt.rcParams['axes.unicode_minus']=False
# plt.rcParams['font.sans-serif']=['HeiTi']
plt.show()
X_name=df.corr()[["n23"]].sort_values(by="n23",ascending=False).iloc[1:7].index.values.astype("U")
print(X_name)
这种方法是基于数学理论知识进行匹配的,一共选取了6种重要的特征
轻量级的高效梯度提升树特征选取
from sklearn.model_selection import train_test_split,cross_val_score #拆分训练集和测试集
import lightgbm as lgbm #轻量级的高效梯度提升树
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
lgbm_class = lgbm.LGBMClassifier(max_depth=5,num_leaves=25,learning_rate=0.005,n_estimators=1000,min_child_samples=80, subsample=0.8,colsample_bytree=1,reg_alpha=0,reg_lambda=0)
lgbm_class.fit(X_train, y_train)
#选择最重要的20个特征,绘制他们的重要性排序图
lgbm.plot_importance(lgbm_reg, max_num_features=14)
##也可以不使用自带的plot_importance函数,手动获取特征重要性和特征名,然后绘图
feature_weight = lgbm_class.feature_importances_
feature_name = lgbm_class.feature_name_
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
# plt.figure(figsize=(10,8))
# sns.barplot(feature_sort.values,feature_sort.index, orient='h')
lgbm_name=feature_sort.index[:8].tolist()
lgbm_name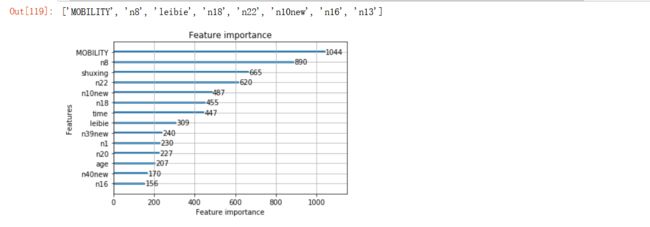
再次带入模型进行训练
把刚刚用相关系数所选取的6个特征带入模型进行训练,再次查看效果
# 加载模型
model = DecisionTreeClassifier(criterion='gini',max_depth=5, splitter= 'random')
# 训练模型
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\n',
classification_report(y_test,y_pred))
现在发现,效果明显的提升了,准确率达到了93%,召回率也比较的高

决策树可视化
import graphviz
from IPython.display import Image
dot_data = tree.export_graphviz(model
,feature_names= ["签署知情同意书","认知功能","自理能力三级","行动能力","有无管道","身体攻击行为"]
#'n22' 'n8' 'n10new' 'MOBILITY' 'n19f1' 'n13'
,class_names=["不需要","需要"]
,filled=True
,rounded = True
,out_file =None#图片保存路径
)
graph = graphviz.Source(dot_data.replace('helvetica','"Microsoft YaHei"'), encoding='utf-8')
graph.view()
这就是决策树模型下的可视化,可以高效率的展示出分类过程,其中

ROC曲线AUC
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 预测正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,返回两列,第一列代表类别0,第二列代表类别1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真阳性标签,就是说是分类里面的好的标签,这个要看你的特征目标标签是0,1,还是1,2
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()
这就是决策树下的预测分类,在本次模型中,首先采取的模型参数调优,然后进行的特性选取,一般来说首先应该进行特征选取然后去进行参数调优,通过验证,本次数据集下的模型效果一致。
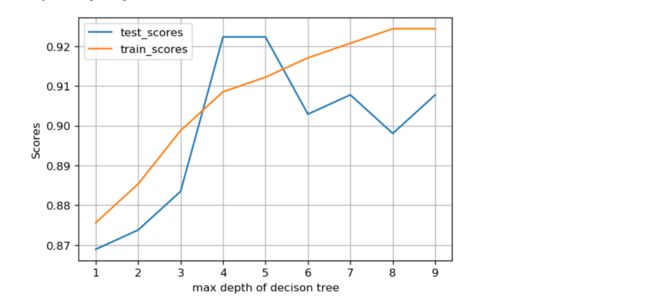
主要的max depth=5,是符合模型的最优选择的
总结
如前所述,控制决策树模型复杂度的参数是预剪枝参数,它在树完全展开之前停止树的构造。通常来说,选择一种预剪枝策略(设置 max_depth、 max_leaf_nodes 或 min_samples_leaf)足以防止过拟合。
与前面讨论过的许多算法相比,决策树有两个优点:一是得到的模型很容易可视化,非专家也很容易理解(至少对于较小的树而言);二是算法完全不受数据缩放的影响。由于每个特征被单独处理,而且数据的划分也不依赖于缩放,因此决策树算法不需要特征预处理,比如归一化或标准化。特别是特征的尺度完全不一样时或者二元特征和连续特征同时存在时,决策树的效果很好。
决策树的主要缺点在于,即使做了预剪枝,它也经常会过拟合,泛化性能很差。因此,在
大多数应用中,往往使用后续的随机森林,介绍的集成方法来替代单棵决策树。
每文一语
要拿的起,也要放得下