深度学习R(1):从零开始建立完全连接的神经网络
作者:PENG ZHAO
我要感谢Feiwen, Neil和所有其他的技术评论家和读者,他们为本文提出了宝贵的意见和建议。
背景
深度神经网络(DNN)近年来取得了在图像识别、自然语言处理和自动驾驶领域取得了巨大成就,如图1所示,从2012至2015年IMAGNET的识别准确度由80%以内提高到95%以内,这远远超过了传统的计算机视觉识别(CV)方法。
图1 – 来自NVIDIA CEO 黄仁勋在2016年国际消费类电子产品展览会上的演讲
在这篇文章中,我们将关注于完全连接的神经网络——通常在数据科学中被称为DNN。DNN的最大优点是能够通过深层结构自动提取和学习特征,尤其是对这些工程师不能轻易捕捉到的复杂高维特征的数据,例如Kaggle。因此,DNN也对数据科学家很有吸引力,有许多成功案例,如分类、时间序列和推荐系统,如Nick的文章和DNN信用评分。在CRAN和R的社区,有几个比较成熟的DNN包,包括神经网络,nerualnet,H2O,DARCH,deepnet和mxnet,我强烈推荐《H2O DNN algorithm and R interface》。
那么,我们到底如何从头开始建立DNN呢?
-理解神经网络是如何工作的
利用现有的DNN的包,在大多数时候您建立DNN模型只需要一行R代码,而且还有神经网络实例。但对于没有经验的用户,处理过程和结果可能是难以理解的。因此,它将是一个有价值的实践,有助于您完善自己的网络以便于从结构和算法的角度了解更多的细节。
-用你的新想法建立特定的网络
DNN是一个迅速发展的领域。每周都会有大量的新发现和研究成果发表在顶级期刊和互联网上。DNN用户也有其特定的神经网络结构以针对他们的问题,例如不同的激活、损失函数、正规化和连通图的问题。另一方面,新的研究成果出来之前,几乎所有现有的包都是用C/C++,Java写的,所以它们不能适用于一些最新升级,也不能通过修改把你的思维加进去。
-网络和数据的训练和可视化
正如我们提到的,现有的DNN包是高度集中的,并且是一些低等级语言编写的,所以我们需要逐层或逐节点训练网络,这是一场噩梦。即使是不容易在每一层中将结果可视化,监视数据或权重在训练中一直是变化的,并显示在网络中发现的模式。
基本概念和组成部分
完全连接神经网络,在数据科学中称为DNN,是相邻的网络层是完全相互连接。网络中的每个神经元都与相邻层中的每一个神经元相连。
如下图所示是一个非常简单的和典型的神经网络,有1个输入层,2个隐藏层,和1个输出层。最主要的是,当研究人员谈论网络的体系结构时,它指的是DNN的配置,如整个网络有多少层,每层有多少神经元,正在应用什么类型的激活、损失函数、正则化。
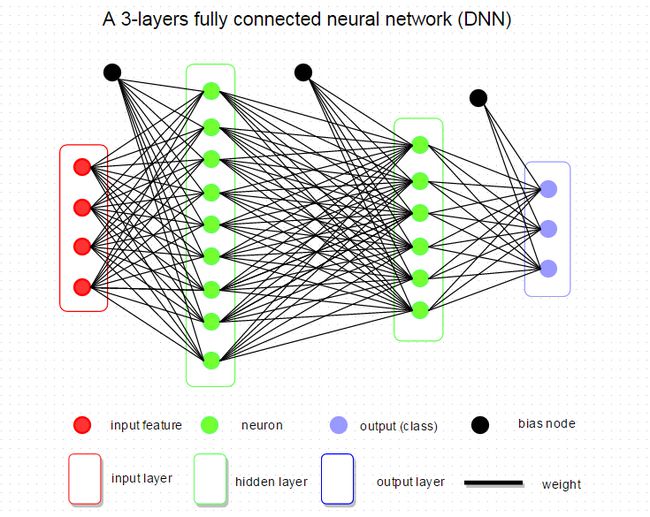
现在,我们将通过DNN的基本组件,向你展示它如何在R中实现。
权重和偏差值
以上述DNN架构为例,从输入层到第一隐藏层、第一到第二隐藏层、第二隐藏层到输出层有3组权重。偏差单元连接到每个隐藏节点并影响着输出分数,但不与实际数据进行接触。在我们的R研究中,我们通过矩阵展示了权重和偏差。权重大小的计算公式是:
(神经元层数 M) X (每层中的神经元数量 M+1)
并且权重值通过rnorm公式的随机数而被初始化。偏差值只是一个一维矩阵,和神经元相同大小,并且值被设定为0。其他的初始化方法,如校准1 / sqrt(N)和稀疏初始化的差异,在斯坦福大学CS231n的weight initialization部分中介绍过。
其R代码为:
另一种常见的实现方法,将权重和偏差值结合起来,使输入的维数是N+1,表明N输入特征偏差值为1,如下面的代码:
神经元
神经元是DNN的基本单位,它是人类神经元的仿生模型。一个独立的神经元扮演着权重,并且输入乘法和加法(FMA),这和数据科学中的线性回归是一样的,然后FMA的结果传递给激活函数。
常用的激活函数包括sigmoid、ReLu、Tanh和Maxout。在这篇文章中,我将采取纠正线性单元(ReLu)作为激活函数,f(x)= max(0,x)。对于其他类型的激活功能,您可以参考这里。
在R中,我们可以通过多种方法操作神经元,比如sum(xi*wi)。但是通过矩阵乘法能够更有效的实现。
其R代码为:
实施提示
在实践中,我们为了性能考虑总是以一批实例去更新一层中的所有神经元。因此,上述代码将无法正常工作。
1)矩阵乘法和加法
如以下代码所示,input %*% weights 和bias 是不同的dimension,也不能直接被添加。这里提供两种解决方案。第一种重复bias的ncol次数。但是,它会在大量数据输入时浪费很多存储空间,因此,第二种方案更好
2)一个矩阵的元素级最大值
另一个小方法就是通过pmax代替max来获得元素级最大值而不是一个全程的值,注意pmax里的顺序。
层
-输入层
输入层是相对固定的,只有1层,其数字单位相当于输入数据的特征数量。
-隐藏层
隐藏层种类很多,是DNN的核心部件。但在一般情况下,需要更多的隐藏层捕捉请求的模式,以解决更复杂的问题(非线性)。
-输出层
在输出层中的单元通常没有激活,因为它通常是在分类中表示类的分数和回归中的任意实数值。对于分类,输出单元的数目与预测的类别数相匹配,而只有一个输出节点进行回归。
构建神经网络:体系结构、预测和训练
到目前为止,我们已经了解了深层神经网络的基本概念,我们将建立一个神经网络,其中包括确定网络体系结构,训练网络,然后预测新的数据与学习网络。为了简化步骤,我们使用一个小的数据集——埃德加安德森的虹膜数据(IRIS),通过DNN做分类。
网络架构
IRIS是众所周知的内置数据集,在机器学习的存量的R中。所以你可以直接通过下面的控制台总结来了解这个资料组。
其R代码为:
概要里有四个特征和三个类别的Species。所以我们可以设计一个DNN架构如下。
然后,我们将我们的DNN模型保存在一个列表里,可用于培训或预测,如下。实际上,我们可以在模型中保留更多的感兴趣的参数,这具有很大的灵活性。
其R代码为:
预测
预测,也被称为机器学习领域的分类或推理,比测试更为简洁,它通过矩阵乘法,从输入到输出来逐层穿越网络层。在输出层,不需要激活功能。在分类上,概率将由SOFTMAX进行计算而在回归上,输出代表实际的值的预测。这个过程被称为前馈或反馈传播。
其R代码为:
训练
训练是在既定的网络体系结构下,搜索优化参数(权重和偏差),并将分类错误或差值最小化。这个过程包括两个部分:前馈和反向传播。前馈是通过输入数据(如预测部分),通过网络,然后计算数据损失的输出层的损失函数(成本函数)。“数据损失度量预测(例如分类中的分类)和地面实况标签之间的相容性。”在我们的示例代码中,我们选择交叉熵函数来评估数据损失,点击这里查看。
在获取数据丢失后,我们需要通过改变权重和偏差来减少数据丢失。通常流行的方法是通过梯度下降或随机梯度下降的损失,这需要每个数据损失的参数的倒数(W1, W2, b1, b2)。反馈会根据不同的激活功能而不同,这是他们的导数公式。这里是斯坦福大学CS231N的更多的训练技巧。
在我们的例子中,RELU逐点导数是:
其R代码为:
测试和可视化
我们已经建立了简单的二层DNN模型,现在我们可以测试我们的模型了。首先将数据集分为训练和测试的两个部分,然后利用训练集训练模型,测试集来测量模型的泛化能力。
其R 代码为:
在测试设定中的数据丢失和测试精度如下所示:
然后我们比较我们的DNN模型和“nnet”包,代码如下:
总结
在这篇文章中,我们已经展示了如何实现从零开始的神经网络。但是代码只是实现了DNN的核心概念,读者可以做进一步的实践:
解决其他分类问题,如玩具箱
选择不同的隐藏层大小,激活函数,损失函数
扩展单隐层网络到多隐层
调整网络解决回归问题
在接下来的文章中,我将介绍如何通过多核CPU和NVIDIA GPU为这个代码加速。