本文作者
Yuanli,来自 Shopee Data Infra OLAP 团队。
摘要
Apache Druid 是一款高性能的开源时序数据库,它适用于交互式体验的低延时查询分析场景。本文将主要分享 Apache Druid 在支撑 Shopee 相关核心业务 OLAP 实时分析方面的工程实践。
随着 Shopee 业务不断发展,越来越多的相关核心业务愈加依赖基于 Druid 集群的 OLAP 实时分析服务,越来越严苛的应用场景使得我们开始遇到开源项目 Apache Druid 的各种性能瓶颈。我们通过分析研读核心源码,对出现性能瓶颈的元数据管理模块和缓存模块做了相关性能优化。
同时,为了满足公司内部核心业务的定制化需求,我们开发了一些新特性,包括整型精确去重算子和灵活的滑动窗口函数。
1. Druid 集群在 Shopee 的应用
当前集群部署方案是维护一个超大集群,基于物理机器部署,集群规模达 100+ 节点。Druid 集群作为相关核心业务数据项目的下游,可以通过批任务和流任务写入数据,然后相关业务方可以进行 OLAP 实时查询分析。

2. 技术优化方案分享
2.1 Coordinator 负载平衡算法效率优化
2.1.1 问题背景
我们通过实时任务监控报警发现,很多实时任务因为最后一步 segment 发布交出(Coordinate Handoff)等待超时失败,随后陆续有用户跟我们反映,他们的实时数据查询出现了抖动。
通过调查发现,随着更多业务开始接入 Druid 集群,接入的 dataSource 越来越多,加上历史数据的累积,整体集群的 segment 数量越来越大。这使得 Coordinator 元数据管理服务的压力加大,逐渐出现性能瓶颈,影响整体服务的稳定性。
2.1.2 问题分析
Coordinator 一系列串行子任务分析
首先我们要分析这些串行是否可以并行,但分析发现,这些子任务存在逻辑上的前后依赖关系,因此需要串行执行。通过 Coordinator 的日志信息,我们发现其中一个负责平衡 segment 在历史节点加载的子任务执行超级慢,耗时超过 10 分钟。正是这个子任务拖慢了整个串行任务的总耗时,使得另一个负责安排 segment 加载的子任务执行间隔太长,导致前面提到的实时任务因为发布阶段超时而失败。
通过使用 JProfiler 工具分析,我们发现负载平衡算法中使用的蓄水池采样算法的实现存在性能问题。分析源码发现,当前的蓄水池采样算法每次调用只能从总量 500 万 segment 中采样一个元素,而每个周期需要平衡 2000 个 segment。也就是说,需要遍历 500 万的列表 2000 次,这显然是不合理的。

2.1.3 优化方案
实现批量采样的蓄水池算法,只需要遍历一次 500 万的 segment 元数据列表,就能完成 2000 个元素的采样。优化之后,这个负责 segment 负载平衡的子任务的执行耗时只需要 300 毫秒。Coordinator 串行子任务的总耗时显著减少。
Benchmark 结果
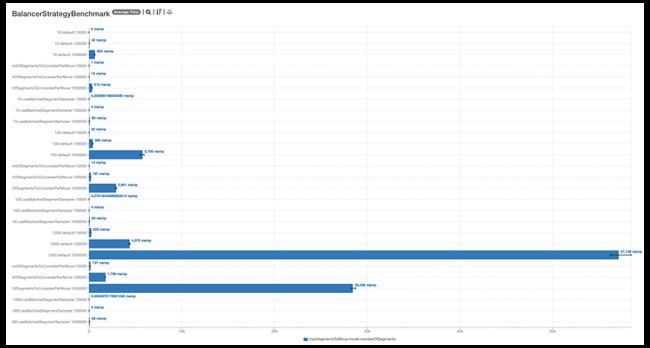
Benchmark 结果对比发现,批量采样的蓄水池算法性能显著优于其他选项。
社区合作
我们已经把这个优化贡献给 Apache Druid 社区,详见 PR。
2.2 增量元数据管理优化
2.2.1 问题背景
当前 Coordinator 进行元数据管理的时候,有一个定时任务线程默认每隔 2 分钟从元数据 MySQL DB 中全量拉取 segment 记录,并在 Coordinator 进程的内存中更新一个 segment 集合的快照。当集群中 segment 元数据量非常大时,每次全量拉取的 SQL 执行变得很慢,并且反序列化大量的元数据记录也需要很大的资源开销。Coordinator 中一系列 segment 管理的子任务都依赖于 segment 集合的快照更新,所以全量拉取 SQL 的执行太慢会直接影响到整体集群数据(segment)可见性的及时性。
2.2.2 问题分析
我们首先从元数据增删改的角度,分 3 种不同的场景分析 segment 元数据的变化情况。
元数据增加
dataSource 的数据写入会生成新的 segment 元数据,而数据写入方式主要分为批任务和 Kafka 实时任务。Coordinator 的 segment 管理子任务及时感知并管理这些新增加的 segment 元数据,对于 Druid 集群写入数据的可见性非常关键。通过 Druid 内部自带 metric 指标,分析发现 segment 单位时间内的增量远远小于总量 500w 的记录数。
元数据删除
Druid 可以通过提交 kill 类型的任务来清理 dataSource 在指定时间区间内的 segment。kill 任务会首先清理元数据 DB 中的 segment 记录,然后删除 HDFS 中的 segment 文件。而已经 download 到历史节点本地的 segment,则由 Coordinator 的 segment 管理子任务负责通知清理。
元数据更改
Coordinator 的 segment 管理子任务中有一个子任务会根据 segment 的版本号,标记清除版本号比较旧的 segment。这个过程会更改相关元数据记录中代表 segment 是否有效的标志位,而已经 download 到历史节点本地的旧版本 segment,也是由 Coordinator 的 segment 管理子任务负责通知清理。
2.2.3 优化方案
通过对 segment 元数据增删改 3 种情况的分析,我们发现,对新增加的元数据进行及时感知和管理非常重要,它会直接影响新写入数据的及时可见性。而元数据的删除和更改主要影响数据清理,这块的及时性要求相对低一些。
综上分析,我们的优化思路是:实现一种增量的元数据管理方式,只从元数据 DB 中拉取最近一段时间新增加的 segment 元数据,并与当前的元数据快照合并得到新的元数据快照,进行元数据管理。同时,为了保证数据的最终一致性,完成优先级相对低一些的数据清理,每隔较长一段时间会进行一次全量拉取元数据。
原来全量拉取的 SQL 语句:
SELECT payload FROM druid_segments WHERE used=true;增量拉取的 SQL 语句:
-- 为了保证SQL执行效率,提前在元数据DB中为新加的过滤条件创建索引
SELECT payload FROM druid_segments WHERE used=true and created_date > :created_date;增量功能属性配置
# 增量拉取最近5分钟新加的元数据
druid.manager.segments.pollLatestPeriod=PT5M
# 每隔15分钟全量拉取元数据
druid.manager.segments.fullyPollDuration=PT15M上线表现
通过监控系统指标发现,启用增量管理功能之后,拉取元数据和反序列化耗时显著降低。同时也降低了元数据 DB 的压力,用户反应的写入数据可读性慢的问题也得到了解决。

2.3 Broker 结果缓存优化
2.3.1 问题背景
在查询性能调优过程中,我们发现,很多查询应用场景不能很好地利用 Druid 提供的缓存功能。当前 Druid 里面存在两种缓存方式,分别是结果缓存和 segment 级别的中间结果缓存。第一种结果缓存只能应用于 Broker 进程,而 segment 级别的中间结果缓存可以应用于 Broker 和其他数据节点。但是当前这两种缓存功能都存在明显的局限性,如下方表格所示。
| 缓存方案/使用场景/是否可用 | 场景一:使用 group by v2 引擎 | 场景二:仅扫描历史 segment | 场景三:同时扫描历史 segment 和实时 segment | 场景四:高效缓存大量 segment 的结果 |
|---|---|---|---|---|
| segment 级别缓存 | ✗ | ✓ | ✓ | ✗ |
| 结果缓存 | ✗ | ✓ | ✗ | ✓ |
2.3.2 问题分析
使用 group by v2 引擎的情况下缓存不可用
group by v2 引擎在过去很长时间的很多稳定版本中,都是 groupBy 类型查询的默认引擎,在可预见的未来很长一段时间也一样。而且 groupBy 类型的查询又是最常见的查询类型之一,另外两种类型是 topN 和 timeseries。group by v2 引擎不支持缓存的问题直到 0.22.0 版本依然存在,见缓存不支持场景。
通过跟踪社区的变更记录,我们发现 group by v2 引擎不支持缓存的原因是,segment 级别的中间结果没有排序可能会导致查询合并结果不正确,具体细节见社区的这个 issue。
下面简单总结一下,为什么 Druid 社区选择通过禁用功能来修复这个 Bug:
- 如果排序 segment 级别的中间结果,然后再把排序结果缓存起来的话,当 segment 数量很多的时候,会增加历史节点的负载;
- 如果不排序 segment 级别的中间结果直接缓存,那么 Broker 需要对每个 segment 的中间结果进行重新排序,会增加 Broker 的负担;
- 如果直接禁用这个功能的话,那么不仅历史节点不会受到任何影响,而且 Broker 合并结果不对的 bug 也解决了。 :)
社区修复方案同时还误伤了结果缓存的功能,使得修复之后的版本使用 group by v2 引擎时,Broker 上面的结果缓存也不可用了,见缓存不支持场景。
结果缓存的局限性
结果缓存要求查询每次扫描的 segment 集合一致,并且所有 segment 都是历史 segment。也就是说,只要查询条件需要查询最新的实时数据,那么结果缓存就不可用。
对于 Druid 这种实时查询分析应用场景见长的服务来说,结果缓存的这个局限显得尤为突出。很多业务场景的查询面板都是查询最近一天/一周/一月的时序聚合结果,包括最新实时数据,但是这些查询都不支持结果缓存。
segment 级别中间结果缓存的局限性
segment 级别中间结果缓存的功能可以同时在 Broker 和其他数据节点上面启用,主要适用于历史节点。
Broker 上启用 segment 级别中间结果缓存,当扫描 segment 数量很大的情况下,存在如下局限性:
- 提取缓存结果的反序列化过程会给 Broker 增加额外开销;
- 增加 Broker 节点合并中间结果的开销,没法利用历史节点来合并部分中间结果。
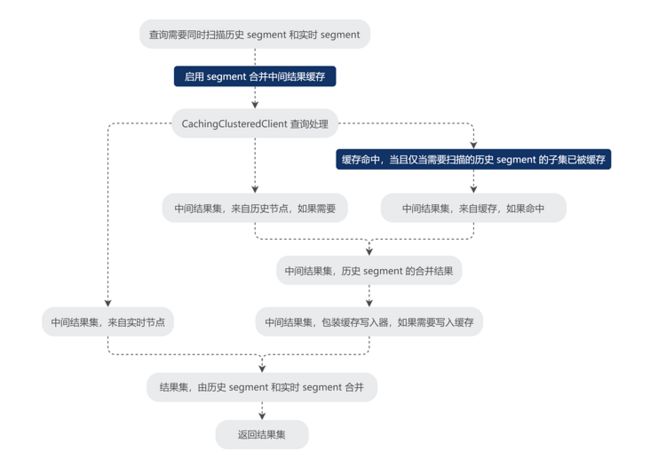
在历史节点上启用 segment 级别中间结果缓存,其工作流程图如下:

在实际应用场景中,我们发现,当 segment 的中间缓存结果很大的时候,序列化和反序列化缓存结果的开销也不可忽视。
2.3.3 优化方案
通过上述分析,我们发现当前两种缓存功能都存在明显的局限性。为了更好地提高缓存效率,我们在 Broker 上面设计并实现了一种新的缓存功能,该功能会缓存历史 segment 的中间合并结果,能很好地弥补当前两种缓存的不足。
新缓存属性配置
druid.broker.cache.useSegmentMergedResultCache=true
druid.broker.cache.populateSegmentMergedResultCache=true适用场景对比
| 缓存方案/使用场景/是否可用 | 场景一:使用 group by v2 引擎 | 场景二:仅扫描历史 segment | 场景三:同时扫描历史 segment 和实时 segment | 场景四:高效缓存大量 segment 的结果 |
|---|---|---|---|---|
| segment 级别缓存 | ✗ | ✓ | ✓ | ✗ |
| 结果缓存 | ✗ | ✓ | ✗ | ✓ |
| segment 合并中间结果缓存 | ✓ | ✓ | ✓ | ✓ |
工作原理
Benchmark 结果

通过 benchmark 结果可以发现,segment 合并中间结果缓存功能不仅初次查询不存在明显额外开销,而且缓存效率明显优于其他缓存选项。
上线表现
启用新的缓存功能后,集群总体查询延迟降低约 50%。

社区合作
我们准备把这个新的缓存功能贡献给社区,当前该 PR 还在等待更多的社区反馈。
3. 定制化需求开发
3.1 基于位图的精确去重算子
3.1.1 问题背景
不少关键的业务需要统计精确的订单量和 UV,而 Druid 自带几种去重算子都是基于近似算法实现,在实际应用中存在误差。因此,相关业务都希望我们能提供一种精确的去重实现。
3.1.2 需求分析
去重字段类型分析
通过分析收集到的需求,发现急切需求中的订单 ID 和用户 ID 都是整型或者长整型,这就使得我们可以考虑省掉字典编码的过程。
3.1.3 实现方案
由于 Druid 社区缺少这块的实现,于是我们选用常用的 Roaring Bitmap 来定制新的算子(Aggregator)。针对整形和长整型分别开发相应的算子,都支持序列化和反序列化用于 rollup 导入模型。于是我们很快发布了这个功能的第一个稳定版,它能很好地解决数据量比较小的需求。
算子 API
// native JSON API
{
"type": "Bitmap32ExactCountBuild or Bitmap32ExactCountMerge",
"name": "exactCountMetric",
"fieldName": "userId"
}-- SQL support
SELECT "dim", Bitmap32_EXACT_COUNT("exactCountMetric") FROM "ds_name" WHERE "__time" >= CURRENT_TIMESTAMP - INTERVAL '1' DAY GROUP BY key局限性分析和优化方向
当前的简单实现方案,面对数据量很大的需求,它的性能瓶颈也暴露出来了。
中间结果集太大导致的性能瓶颈
新的算子内存空间占用过大,缓存写入和提取都存在明显的开销,并且这类算子主要用于 group by 查询,所以当前现有的缓存都不能发挥应有的作用。这也进一步驱动我们设计开发了一个新的缓存选项,segment 合并中间结果,详见前文所述。
通过有效缓存 segment 合并的中间结果,大大降低了 segment 级别中间结果太大带来的序列化和反序列化开销。另外,未来也会考虑通过重新编码的方式,降低数据分布的离散程度,提高 bitmap 对整型序列的压缩率。
内存估算困难的问题
由于 Druid 查询引擎主要通过堆外内存 buffer 处理中间结算结果来减少 GC 影响,这就要求算子内部数据结构支持比较准确的内存估算。但是这类基于 Roaring bitmap 的算子不仅难以估算内存,而且在运算过程中只能在堆内存中构造对象实例。这使得这类算子在查询中内存开销不可控,极端查询情况下甚至可能出现 OOM 的情况。
针对这类问题,短期内我们主要通过结合上游数据处理来缓解,比如重新编码,合理分区分片等等。
3.2 灵活的滑动窗口函数
3.2.1 问题背景
Druid 核心查询引擎仅支持固定窗口大小的聚合函数,缺少对灵活滑动窗口函数的支持。一些关键业务方希望每日统计近 7 天的 UV,这就要求 Druid 支持滑动窗口聚合函数。
3.2.2 需求分析
社区 Moving Average Query 扩展的局限性
通过调查,我们发现社区已有的扩展插件 Moving Average Query 支持一些基本类型的滑动窗口计算,但是缺少对其他复杂类型(对象类型)的 Druid 原生算子的支持,比如广泛应用的 HLL 类型近似算子等。同时,这个扩展也缺少对 SQL 的支持适配。
3.2.3 实现方案
通过研读源码,我们发现这个扩展还可以更加通用和简洁。我们增加了一个 default 类型的算子实现,它能根据基础字段的类型,实现对基础字段的滑动窗口聚合。也就是说,通过这一个 default 类型的算子就可以让所有 Druid 原生算子(Aggregator)支持滑动窗口聚合。
同时,我们为这个通用的算子适配了 SQL 函数支持。
算子 API
// native JSON API
{
"aggregations": [
{
"type": "hyperUnique",
"name": "deltaDayUniqueUsers",
"fieldName": "uniq_user"
}
],
"averagers": [
{
"name": "trailing7DayUniqueUsers",
"fieldName": "deltaDayUniqueUsers",
"type": "default",
"buckets": 7
}
]
}-- SQL support
select TIME_FLOOR(__time, 'PT1H'), dim, MA_TRAILING_AGGREGATE_DEFAULT(DS_HLL(user), 7) from ds_name where __time >= '2021-06-27T00:00:00.000Z' and __time < '2021-06-28T00:00:00.000Z' GROUP BY 1, 2社区合作
我们准备把这个新功能贡献给社区,当前该 PR 还在等待更多的社区反馈。
4. 未来架构演进
为了更好地从架构层面解决稳定性问题,实现降本增效,我们开始探索和落地 Druid 的云原生部署方案。后续我们还会分享关于这一块的实践经验,敬请期待!
参考链接
- Apache Druid
- Reduce method invocation of reservoir sampling
- Add segment merged result cache for broker
- Scenarios where caching does not increase query performance
- groupBy v2: Results not fully merged when caching is enabled on the broker#3820
- Moving Average Query
- Add default averager to support general trailing aggregates #11387