Tensorflow【branch-官网代码实践-Eager/tf.data/Keras/Graph】_8.19
Tensorflow有low-level和high-level两种APIs,
low-level如:tensors的编辑、variables的编辑、graphs and sessions的管理,model的save and restore。
high-level如:tflearn、Keras、Eager Execution、Estimators框架。
简言之,high-level是对底层low-level的直接封装,目前身边大多同学的代码都是基于high-level APIs开发,因此对照着tutorials将high-level的APIs复现并理解一遍。
官网地址:https://tensorflow.google.cn/get_started/
1. Eager Execution 使用入门
- 传统的TF使用的是 Graph Execution
- TensorFlow 的 Eager Execution 是一种命令式编程环境,可立即评估操作,无需构建图:操作会返回具体的值,而不是构建以后再运行的计算图。
- 启用 Eager Execution 会改变 TensorFlow 操作的行为方式 - 现在它们会立即评估并将值返回给 Python。tf.Tensor 对象会引用具体值,而不是指向计算图中的节点的符号句柄。由于不需要构建稍后在会话中运行的计算图,因此使用 print() 或调试程序很容易检查结果。(本质是在这种模式下默认开启interactive模式,可以直接print。)
- Eager Execution 适合与 NumPy 一起使用。
- NumPy 操作接受 tf.Tensor 参数。
- TensorFlow 数学运算将 Python 对象和 NumPy 数组转换为 tf.Tensor 对象。
- tf.contrib.eager 模块包含可用于 Eager Execution 和 Graph Execution 环境的符号,对编写处理图的代码非常有用:tfe = tf.contrib.eager
- 构建神经网络时建议基于基类: tf.keras.layers.Layer
- 将层构建成模型时
- 可以使用 tf.keras.Sequential 表示由层线性堆叠的模型
- 通过继承 tf.keras.Model 将模型划分为不同类别
- 梯度计算:tf.GradientTape 是一种选择性功能,可在不跟踪时提供最佳性能。由于在每次调用期间都可能发生不同的操作,因此所有前向传播操作都会记录到“磁带”中。要计算梯度,请反向播放磁带,然后放弃。
- https://tensorflow.google.cn/api_docs/python/tf/GradientTape
- 常用方法
- with tf.GradientTape() as g: –定义g为梯度tape
- g.watch(x) –g的求导对象是x,(Trainable Variables会自动watched,如果是在函数定义中需要显示表达)
- g.gradient(target, sources)
- tf.assign_add(tensor, value) = tensor.assign_add(value)
- 一个线性回归的梯度下降实例

- python str.format() 格式化输出:
- https://www.cnblogs.com/zyq-blog/p/5946905.html
- ‘{:.2f}’.format(321.33345) = 321.33
- 冒号 :冒号后带填充的字符,只能说一个字符,若未指定的话默认用空格填充
- .2 :表示保留小数点后2位
- f :表示浮点类型
- python 下划线的意义:
- https://blog.csdn.net/jiaoyongqing134/article/details/78180674
- 变量名_xxx被看作是“私有 的”,在模块或类外不可以使用。
- 为了让方法或者特性变为私有(从外部无法访问),只要在它的名字前面加上双下划线即可。
- 有的名称在前后都加双下划线,是一种特殊命名。由这些名字组成的集合所包含的方法称为魔法方法。如果对象实现了这些方法中的某一个,那么这个方法会在特殊的情况下被Python调用。而没有直接调用它们的必要。
- 与Graph Execution的区别:使用GE时程序状态存储在全局集合中,它们的生命周期由 tf.Session 对象管理。相反,在Eager Execution期间,状态对象的生命周期由其对应的 Python 对象的生命周期决定。
- 使用checkpoint可以缓存对象,并读取
- 缓存变量

- 缓存模型
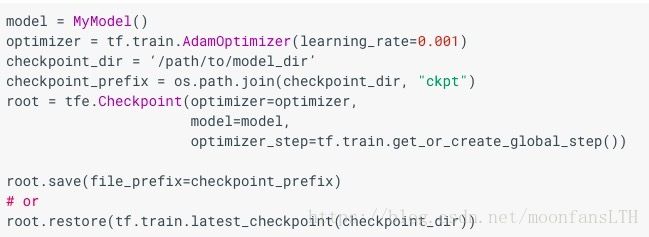
- 计算梯度的其他函数
- tfe.gradients_function:返回一个函数,该函数会计算其输入函数参数相对于其参数的导数。输入函数参数必须返回一个标量值。当返回的函数被调用时,它会返回一个 tf.Tensor 对象列表(tensor list,输入函数的每个参数各对应list的一个元素)。
- tfe.value_and_gradients_function:与tfe.gradients_function 相似,但是当返回的函数被调用时,除了输入函数相对于其参数的导数列表之外,它还会返回输入函数的值。
- 求函数的N阶导,返回对于参数的tensor list

- 自定义梯度:就是自己把梯度函数写出来
- 性能
- 将计算分流到GPU/CPU,控制计算运行的位置。
- tf.device(‘/cpu:0’)
- if tfe.num_gpus() > 0: tf.device(‘/gpu:0’)
- 将对象赋值到不同设备:
- x.cpu()
- x.gpu()
- 和GraphExecution的兼容性
- 虽然 Eager Execution 增强了开发和调试的交互性,但 TensorFlow Graph Execution 在分布式训练、性能优化和生产部署方面具有优势。不过,编写图形代码不同于编写常规 Python 代码,并且更难以调试。
- 为 Eager Execution 编写的相同代码在 Graph Execution 期间也会构建图。在未启用 Eager Execution 的新 Python 会话中运行相同的代码便可实现此目的。
- 一旦通过 tf.enable_eager_execution 启用了 Eager Execution,就不能将其关闭。要返回到 Graph Execution,需要启动一个新的 Python 会话。
- 最好同时为 Eager Execution 和 Graph Execution 编写代码。这样,既可以获得 Eager Execution 的交互式实验和可调试性功能,又能拥有 Graph Execution 的分布式性能优势。
- 在图环境中使用Eager

#命令汇总
#启动 Eager Execution
tf.enable_eager_execution()
#查看是否启动 =>True
tf.executing_eagerly()
#可以通过print查看tensor的值
a=tf.constant([[1,2],[3,4]])
print a
# => tf.Tensor([[1 2]
# [3 4]], shape=(2, 2), dtype=int32)
#将tensor转换为numpy的matrix
print a.numpy()
# => [[1 2]
# [3 4]]
#基于对象的保存 tfe.Checkpoint将tfe.Variable保存到检查点并从中恢复
2. 导入数据 tf.data
- tf.data.Iterator 提供了两个操作:
- Iterator.initializer,初始化迭代器的状态
- Iterator.get_next(),此操作返回对应于有符号下一个元素的 tf.Tensor 对象
- tf.data API 在 TensorFlow 中引入了两个新的抽象类:
- tf.data.Dataset 表示一系列元素,其中每个元素包含一个或多个 Tensor 对象。可以通过两种不同的方式来创建数据集:
- 创建来源(例如 Dataset.from_tensor_slices()),以通过一个或多个 tf.Tensor 对象构建数据集。
- 应用转换(例如 Dataset.batch()),以通过一个或多个 tf.data.Dataset 对象构建数据集。
- tf.data.Iterator 提供了从数据集中提取元素的主要方法。Iterator.get_next() 返回的操作会在执行时生成 Dataset 的下一个元素,并且此操作通常充当输入管道代码和模型之间的接口。最简单的迭代器是“单次迭代器”,它与特定的 Dataset 相关联,并对其进行一次迭代。要实现更复杂的用途,您可以通过 Iterator.initializer 操作使用不同的数据集重新初始化和参数化迭代器。
- tf.data.Dataset 表示一系列元素,其中每个元素包含一个或多个 Tensor 对象。可以通过两种不同的方式来创建数据集:
- 数据集结构
- 一个数据集包含多个元素,每个元素的结构都相同。
- 一个元素包含一个或多个 tf.Tensor 对象,这些对象称为组件。
- 每个组件都有一个 tf.DType,表示张量中元素的类型。
- 以及一个 tf.TensorShape,表示每个元素(可能部分指定)的静态形状。
- 创建数据集
- tf.data.Dataset.from_tensors()
- tf.data.Dataset.from_tensor_slices()
- 元素转换
- 单元素转换,为每个元素应用一个函数:Dataset.map()
- 多元素转换,为多个元素应用一个函数:Dataset.batch()
- 访问数据集
- 构建迭代器对象(单次、可初始化、可重新初始化、可馈送)
- 单次:只支持对数据集进行一次迭代,无需显示初始化
- dataset = tf.data.Dataset.range(100)
- iterator = dataset.make_one_shot_iterator()
- next_element = iterator.get_next()
- 可初始化:显示对迭代器进行初始化,一般是用在有参数依赖情形
- dataset = tf.data.Dataset.range(max_value) 其中 max_value=tf.placeholder(tf.int64, shape=[]) 是个变量,因此需要initialize
- iterator = dataset.make_initializable_iterator()
- next_element = iterator.get_next()
- 初始化:sess.run(iterator.initializer, feed_dict={max_value:10})
- 可重新初始化:可以通过多个不同的 Dataset 对象进行初始化(一般是训练集和验证集,share相同的结构。)
- 可以把具有相同结构的dataset定义在一个iterator中,通过不同的初始化读取不同的内容
- 定义相同的iterator,但在graph execution中initialize不同的dataset,得到不同的结果。即在迭代器之间切换时需要从数据集迭代器的初始化开始

- 可馈送迭代器:与 tf.placeholder 一起使用,通过熟悉的 feed_dict 机制选择每次调用 tf.Session.run 时所使用的 iterator。它提供的功能与可重新初始化迭代器的相同,但在迭代器之间切换时不需要从数据集的开头初始化迭代器。
- 通过把不同dataset的iterator initialize关联到handle里,在sess.run时给handle feed_dict,选择不同的初始化对象。

- 单次:只支持对数据集进行一次迭代,无需显示初始化
- 构建迭代器对象(单次、可初始化、可重新初始化、可馈送)
消耗迭代器中的值
- iterator.get_next() 方法返回一个或多个 tf.Tensor 对象,这些对象对应于迭代器有符号的下一个元素。每次评估这些张量时,它们都会获取底层数据集中下一个元素的值。你必须使用 TensorFlow 表达式中返回的 tf.Tensor 对象,并将该表达式的结果传递到 tf.Session.run(),以获取后续元素并使迭代器进入下个状态。)
- 迭代器的本质是每次读取dataset的新的值(每次get_next()就是读取iterator里新的值),如果dataset已经读取完则抛 tf.errors.OutOfRangeError 的error。需要重新初始化iterator
- 常见模式是将训练循环封装在try-except模块中

读取输入数据
- 消耗Numpy数组
- 将dataset关联的numpy数组设定为placeholder,在sess.run时通过feed_dict导入。
- 消耗TFRecord数据
- TFRecord 文件格式是一种面向记录的简单二进制格式,很多 TensorFlow 应用采用此格式来训练数据。通过 tf.data.TFRecordDataset 类,您可以将一个或多个 TFRecord 文件的内容作为输入管道的一部分进行流式传输。
- 将 filenames 视为 tf.Tensor,因此您可以通过传递 tf.placeholder(tf.string) 来进行参数化。
- 消耗文本数据
- tf.data.TextLineDataset 提供了一种从一个或多个文本文件中提取行的简单方法。

- 消耗Numpy数组
- 预处理数据:Dataset.map()
- 常见的几种解析方式:
- 解析 tf.Example 协议缓冲区消息
- 解码图片数据并调整其大小
- 使用 tf.py_func() 应用任意 Python 逻辑
- 常见的几种解析方式:
- 批处理数据集元素
- 简单的批处理(Dataset.batch):将数据集中的 n 个连续元素堆叠为一个元素,适合处理相同形状的tensor
- 使用填充批处理张量(Dataset.padded_batch):指定一个或多个会被填充的维度,从而批处理不同形状的tensor
- 训练工作流程
- 处理多个周期:迭代数据集多个周期,Dataset.repeat()
- 随机重排输入数据:Dataset.shuffle() 转换会使用类似于 tf.RandomShuffleQueue 的算法随机重排输入数据集。
#通过 Dataset.output_types 和 Dataset.output_shapes 属性检查数据集元素各个组件的推理类型和形状。
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10]))
print(dataset1.output_types) # ==> "tf.float32"
print(dataset1.output_shapes) # ==> "(10,)"3. 使用Keras构建模型和层
- The Sequential model is a linear stack of layers
- Being able to go from idea to result with the least possible delay is key to doing good research.
- model = Sequential()
- Keras API:https://keras.io/models/sequential/
- Keras 中文API:https://keras-cn.readthedocs.io/en/latest/
- Keras Example:https://github.com/keras-team/keras/tree/master/examples
- the first layer in a Sequential model (and only the first, because following layers can do automatic shape inference) needs to receive information about its input shape.
- 在定义层时通过 input_shape, input_dim(2D), input_length(3D)控制input_shape
- 通过 batch_size 定义batch大小
- batch_shpe = batch_size + input_shape
- Model Compilation(模型的编译):compile(optimizer, loss_function,metrics)
- Model Training(模型的训练),fit(x, y, batch_size)
- 总结:Keras把神经网络的构建变得非常直白,神经网络看成是一层层网络的叠加(add),在keras.layers中有对各种神经网络构建的模板(dense、dropout、embedding、Conv1D、Conv2D、LSTM等)
- 构建模型的几步
- model=Sequential()
- model.add
- model.compile
- model.fit
- socre=model.evaluate
- 构建模型的几步
- 问题:如何确定神经网络的层数及其参数?

4. Graph Execution
- Graph Execution使用入门:
- https://tensorflow.google.cn/get_started/get_started_for_beginners
- Tensorflow 编程堆栈
- tf
- 其他
- tf.run.app/ tf.app.flags.FLAGS 的用法
- https://blog.csdn.net/TwT520Ly/article/details/79759448
- tf.run.app/ tf.app.flags.FLAGS 的用法
