1.Java是一种强类型语言
在JAVA中,所有的数据类型所占的字节数量与平台无关。Java没有任何无符号(unsigned)形式的int、long、short或byte类型。
2.基本类型(8种)
-
整型 - (4种)
类型 大小 取值范围 int4字节 -2 147 483 648 ~ 2 147 483 647(正好超过20亿) short2字节 -32 768 ~ 32 767 long8字节 -9 223 372036 854 775 808 ~ 9 223 372 036 854 775 807 byte1字节 -128 ~ 127 -
L或l: 长整型(40000000L) -
0x或0X: 十六进制数(0xCAFE) -
0: 八进制数(010 -> 十进制数8) -
0b或0B: 二进制数(0b1001 -> 十进制数9)*Jdk7+
-
-
浮点类型 - (2种)
类型 大小 取值范围 float4字节 大约±3.402 823 47E+38F(有效位数为6 ~ 7位) double8字节 大约±1.797 693 134 862 315 70E+308(有效位数为15位) - 绝大部分应用程序都采用double类型。
-
表示Unicode编码的字符单元的字符类型(char) - (1种)
- 原本用于表示单个字符。
- 有些Unicode字符可以用一个char值描述,另外一些Unicode字符则需要两个char值。
- 在Java中,char类型描述了UTF-16编码中的一个代码单元。
强烈建议不要在程序中使用char类型,除非确实需要处理UTF-16代码单元
表示真值(boolean) - (1种)
true 、 false
3.变量
- 常量
利用关键字final指示常量 - 构建字符串
- StringBuilder : 效率高,线程不安全
- StringBuffer : 效率低,线程安全
- switch语句
case标签可以是:
- 类型为char、byte、short或int的常量表达式。
- 枚举常量。
- 字符串字面量(jdk7+) - 大数值(类)
-
BigInteger: 实现任意精度的整数运算 -
BigDecimal: 实现了任意精度的浮点数运算
-
- 数组拷贝
Arrays.copyOf() - 数组排序
Arrays,sort()
4.对象与类
类设计技巧
- 一定要保证数据私有
- 一定要对数据初始化
- 不要在类中使用过多的基本类型
- 不是所有的域都需要独立的域访问器和域更改器
- 将职责过多的类进行分解
- 类名和方法名都要 能够体现它们的职责
- 优先使用不可变的类
5.继承
-
阻止继承:final类和方法
- 修饰类:阻止定义类的子类
- 修饰方法: 阻止子类重写方法
-
强制类型转换
- 只能在继承层次内进行类型转换
- 在将超类转换成子类之前,应该使用instanceof进行检查
-
抽象类
- 使用abstract关键字
-
可见性控制修饰符
-
private: 仅对本类可见 -
public: 对所有类可见 -
protected: 对本包和所有子类可见 -
默认: 对本包可见
-
参数可变的方法
eg: method(Object ...args)-
枚举类
/** * @author chenchao * @Date 2018/6/20 下午6:37 */ public enum EnumTest { SMALL("s"),MEDIUM("m"); EnumTest(String s) { } } //System.out.println(EnumTest.MEDIUM.toString()); -
反射
- 功能
- 在运行时分析类的能力
- 在运行时查看对象,例如,编写一个toString方法供所有类使用
- 实现通用的数组操作代码
- 利用Method对象,这个对象很像C++中的函数
- class类
- 调用静态方法forName获得类名对应Class对象
String classname = "java.util.Random"; Class cl = Class.forName(classname); Object o = Class.forName(classname).newInstance();
- 调用静态方法forName获得类名对应Class对象
- 利用反射分析类的能力
-
Field、Method、Constructor: 域、方法、构造器 - setAccessible(boolean flag)
- 为反射对象设置可访问标志
- 方法调用
public Object invoke(Object implicitParametter,Object[] explicitParamenters)
-
- 功能
-
继承的设计技巧
- 将公共操作和域放在超类
- 不要使用受保护的域
- 使用继承实现‘is-a’关系
- 除非所有继承的方法都有意义,否则不要使用继承
- 在覆盖方法时,不要改变预期的行为
- 使用多态,而非类型信息
- 不要过多地使用反射
6.接口、lambda表达式于内部类
接口(
interface)-
lambda表达式
(arg0, arg1 ...) -> { //do soming } -
函数式接口(
functional interface)- 对于只有一个抽象方法的接口,需要这种接口的对象时,就可以提供一个lambda表达式。这种接口称为函数式接口。
eg:Arrays.sort(words, (first, second) -> first.length() - second.length() ); //lambda表达式可以转换为接口 -
方法引用
有时,可能会已经有现成的方法可以完成你想要传递到其他代码的某个动作。
eg://Timer t = new Timer(1000, event -> System.out.priontln(event)); Timer t = new Timer(1000, System.out::println);表达式System.out.println是一个方法引用(method regerence), 它等价于lambda表达式:x -> System.out.println(x)
-
要用::操作符分隔方法名于与对象或类名。主要有3种情况:
- object::instanceMethod
- Class::staticMethod
- Class::instanceMethod
eg:
System.out::println 等价于 x -> System.out.println(x) math::pow 等价于 (x,y) -> Math.pow(x,y) //第三种, 第一个参数会成为方法的目标。 String::compareToIgnoreCase 等同于 (x,y) -> x.compareToIgnoreCase(y)类似于lambda表达式,方法引用不能独立存在,总会转换为函数式接口的实例 -
构造器引用
构造器引用与方法引用很类似,只不过方法名为new。
Person::new 是Person构造器的一个引用。
java ArrayListnames = .....; Stream stream = names.stream().map(Person::new); List people = stream.collect(Collectors.toLiost());
- 内部类
- new内部类示例: OuterClass.InnerClass object = OuterClass.new IbnnerClass();
被编译成的文件:Outer$Inner.class
- 内部类可以访问外部类的私有数据。
- 只有内部类可以是私有类,而常规类只可以具有包可见性,或者共有可见性。
-内部类中声明的所有静态域都必须是final
-内部类不能有static方法-
局部内部类
 image
image局部内部类不能用public或private访问说明符进行声明,它的作用域被限制在了声明它的块中。- 与其他内部类相比,局部类还有一个优点,不仅能够访问包含它们的外部类,还可以访问局部变量,不过那些局部变量必须实事上为final。
-
匿名内部类
 image
image- ActionListener是接口。
Person queen = new Person("Mary"); //a Person object Person count = new Person("Dracula"){....}; // an object of an inner class extending Person***
现在有更好的办法使用Lambda表达式 -
静态内部类
有时候,使用内部类只是为了把一个类隐藏在另外一个类内部,并不需要内部类引用外围类对象。为此,可以将内部类声明为static,以便取消产生的引用。
```java
ArrayAlg.Pair p = ArrayAlg.minmax(d);//类定义
class ArrayAlg{
public static class Pair{
....
}//用来返回两个参数 public static Pair minmax(double[] d){ ... return new Pair(min, max); }}
- 在内部类不需要访问外部类对象时,应该使用静态内部类。 - 与常规内部类不同,静态内部类可以有静态域和方法 - 声明在接口中的内部类,自动成为static和public类。
-
-
代理
利用代理可以在运行时创建一个实现了一组给定接口的新类。(程序设计人员使用机会较少)
- (未完成)
7. 异常、断言和日志
异常处理的任务就是将控制权从错误产生的地方转移给能够处理这些情况的错误处理器。
异常分类
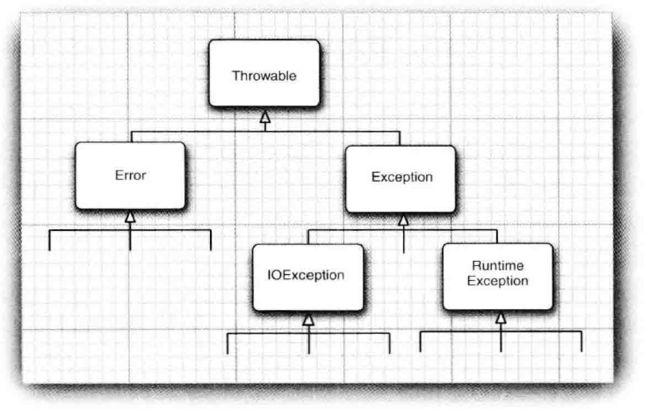 image
image所有的异常都是由Throwable继承而来。但在下一层分解为两个分支:Error 和 Ecxeption。
- Error 类层次结构描述了Java运行时系统的内部错误和资源耗尽错误。
- Exception层次结构,在设计Java程序时需要关注
- RuntimeException:由程序错误导致的异常。
- 其他异常:程序本身没有问题,但由于像I/O错误这类问题导致的异常。
声明受查异常:
在下面四中情况下应该抛出异常
调用一个抛出受检查异常的方法,例如,FileInputStream构造器。
程序运行过程中发现错误,并且利用throw语句抛出一个受检查异常。
程序出现错误,例如a[-1]=0会抛出一个ArrayIndexOutOfBoundsException这样的非受查异常。
Java虚拟机和运行时库出现内部错误。
出现前两种之一,就必须告诉调用这个方法的程序员有可能抛出异常。
声明方法可能抛出的异常:
Class MyAnimation{ ... public Image loadImage(String s) throws FileNotFoundException, EOFException{ } }抛出异常:
throw new EOFException();
创建异常类
//定义一个派生于Exception的类,或者派生于Exception子类的类 //例如,定义一个派生于IOException的类 Class FileFormatException extends IOException{ public FileFormatException(){} public FileFormatException(String gripe){ super(gripe); } } // 习惯上,定义的类应该包含两个构造器,一个是默认的构造器; // 另一个是带有详细信息描述的构造器。
捕获异常
try{ .... }catch(Exception e){ handler for this type }如果try语句块中的任何代码抛出一个在catch子句中说明的异常类:
- 程序将跳过try语句块的其余代码
- 程序将执行catch子句中的处理代码
finally子句:
不管是否有异常被捕获,finally子句中的代码都被执行。
- try语句可以只有finally语句,而没有catch子句。
带资源的try语句(Java SE 7)
try-with-resourcestry(Resource res = ...){ work with res }try块退出时,会自动调用res.close()。
-
使用异常机制的技巧:
-
异常处理不能代替简单的测试
捕获异常耗时,应该只在异常情况下使用异常机制。
-
不要过分地细化异常
代码量急剧膨胀
利用异常层次结构(应该寻找更加适合的异常子类,或自己创建异常类)
不要压制异常
在检测错误时,“苛刻”比放任更好
不要羞于传递异常
(早抛出,晚捕获)
-
8. 泛型程序设计
- 泛型类
public class Pair{ private T first; public T getFirst(){ return this.first; } } - 泛型方法
class ArrayAlg{ public staticT getMiddle(T...a){ return a[a.length/2] } } //调用 String moddle = ArrayAlg. getModdle("John", "H", "public"); //编译器可推断出 String moddle = ArrayAlg.getModdle("John", "H", "public"); - 类型变量的限定
//限制T实现了Comparable接口 public staticT min(T[] a){} // - 通配符概念
-
Pair: 表示任何泛型Pair类型,它的类型参数是Employee的子类,如Pair
-
- 通配符的超类型限定
? super Manager
这个通配符限制为Manager的所有超类型(包含Manager) - 反射和泛型
- 泛型类的实例,得不到太多信息,因为他们会被擦除。
- 可以获得泛型类的信息
-
泛型Class类
//反射获取泛型类型 public class TestServiceBase{ private Class clazz; public void print(){ //当前对象的直接超类的 Type Type genericSuperclass = getClass().getGenericSuperclass(); System.out.println(genericSuperclass.getTypeName()); if(genericSuperclass instanceof ParameterizedType){ //参数化类型 ParameterizedType parameterizedType= (ParameterizedType) genericSuperclass; //返回表示此类型实际类型参数的 Type 对象的数组 Type[] actualTypeArguments = parameterizedType.getActualTypeArguments(); this.clazz= (Class )actualTypeArguments[0]; }else{ this.clazz= (Class )genericSuperclass; } System.out.println(this.clazz.getName()); } }
-
9. 集合
-
Java库中的具体集合
 image
image
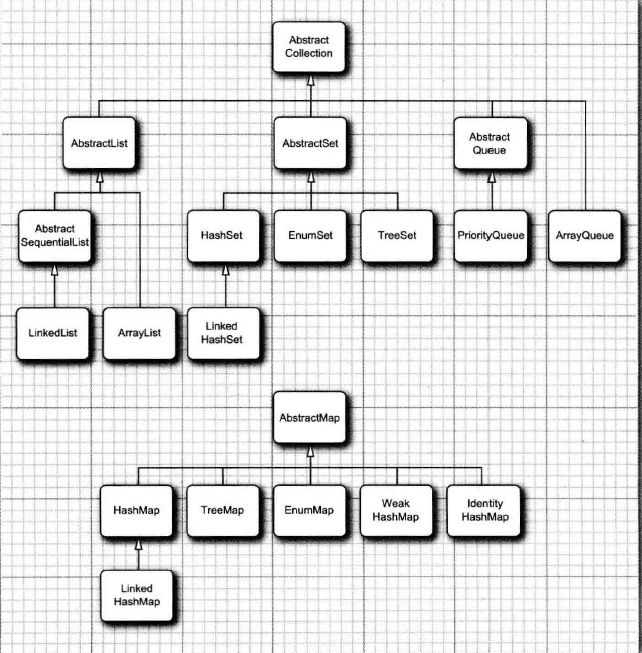 image
image Vector所有的方法为同步方法(安全,耗时),ArrayList方法不是同步的。-
迭代器
Setset = new HashSet<>(); for (int i = 0; i < 100; i++) { set.add(i + ""); } System.out.println(set.size()); //100 Iterator iterator = set.iterator(); while (iterator.hasNext()){ if(Integer.parseInt(iterator.next()) % 2 == 0){ iterator.remove(); //删除上一次next的数据 iterator.remove(); //Error /* *iterator.remove(); *iterator.next() *iterator.remove(); //OK! */ } } System.out.println(set.size()); //50
-
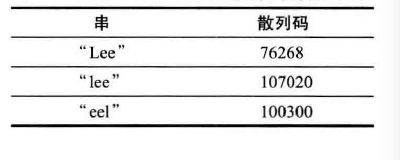
散列集
链表和数组可以按照人们的意愿排列元素的次序。但是,如果想要查看某个指定的元素,却又忘记了它的位置,就需要访问所有元素,直到找到为止-
散列表
 image
image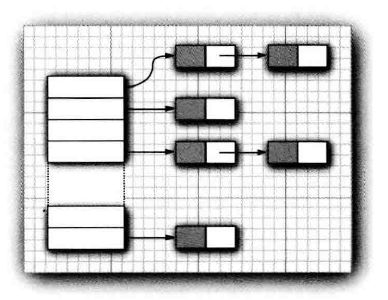 image
image例如,某个对象的散列码是76268,并且有128个桶,对象应该存在第108号桶(76268除以128余108)。
-
-
树集
TreeSet 类与散列集十分相似,不过,它比散列集有所改进。树集是一个
有序集合。按照任意顺序插入,遍历时,每个值将按照排序后的顺序呈现。
排序是用树结构完成的(目前使用的是红黑树)。
-
将一个元素加到树中要比加到散列中慢。
 image
image 要使用树集,必须能够比较元素(元素实现Comparable接口, 或者构造集时必须提供一个Comparator)
-
队列与双端队列
Java SE 6加入Deque接口, 并由ArrayDeque 和 LinkedList实现, 这两个类都提供了双端队列。
-
优先级队列
PriorityQueue元素按照任意顺序插入,按照排序的顺序检索。——>也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。
然而,优先级队列并没有对所有元素进行排序。
优先级队列使用了一个优雅且高效的数据结构,称为堆(heap)。堆时一个可以自我调整的二叉树,对树执行添加(add)和删除(remove)操作,可以让最小的元素移动到根,而不必话费时间对元素进行排序。
与TreeSet中的迭代不同,这里的迭代并不是按照元素的排列顺序访问的。而删除却总是删除掉剩余元素中优先级数最小的那个元素。
-
映射
映射(map)用来存放键/值对。
-
Java类库为映射提供了两个通用的实现:HashMap 和 TreeMap。这两个类都实现了Map接口。
散列映射对键进行散列。
树映射用键的整体顺序对元素进行排序,并将其组织成搜索树。
散列稍微快一些
-
-
链接散列集与映射
LinkedHashSet和LinkedHashMap类用来记住插入元素项的顺序。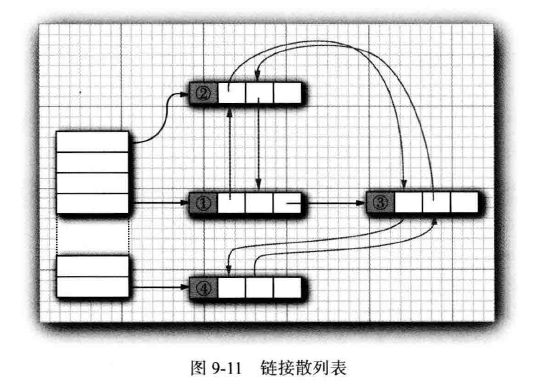 image
imageMap
-
枚举集与映射
EnumSet 是一个枚举类型元素集的高效实现。由于枚举类型只有有限个实例,所以EnumSet内部用位序列实现。如果对应的值在集中,则相应的位被置为1。
-
使用静态工厂方法构造这个集:
 image
image
-
EnumMap是一个键类型为枚举类型的映射。它可以直接且高效地用一个数值组实现。在使用时,需要在构造器中指定键类型:
EnumMap personInCharge = new EnumMap<>(Weekday.class);
-
标识散列映射
IdentutyHashMap有特殊的作用。在这个类中,键的散列值不是用hashCode函数计算的,而是用System.identityHashCode方法计算的。(也就是说,不同的键对象,即使内容相同,也被视为是不同的对象。) -
视图与包装器
-
轻量级集合包装器
-
Arrays类的静态方法asList将返回一个爆炸股了普通Java数组的List包装器。
Card[] cardDeck = new Card[52]; ... ListcardList = Arrays.asList(cardDeck); 发那会的对象不是 ArrayList 。他是一个视图对象,带有访问底层数组的方法。
-
-
- 子范围
```java
List group2 = staff.subList(10, 20);
group2.clear();//staff reduction
//现在,元素自动地从staff列表中清除了,并且group2为空。
```
- 同步视图
如果由多个线程访问集合,就必须确保集不会被意外地破坏。
类库的设计者使用视图机制来确保常规集合的线程安全,而不是实现线程安全的集合类。
eg: `Collections类的静态synchronizedMap`
```java
Map mapl = Collections.synchronizedMap(new HashMap());
```
通常,视图有一些局限性,即可能只可以读、无法改变大小、只支持删除而不支持插入,这些与映射的键视图情况相同。如果试图进行不恰当的操作,受限制的视图就会抛出一个UnsupportedOperationException。
-
算法
-
排序与混排
-
排序
Liststaff = new LinkedList<>(); Collections.sort(staff); //或者 staff.sort(Comparator.comparingDouble(Employee::getSalary));//使用List接口的sort方法,并传入一个Comparator对象。 staff.sort(Comparator.comparingDouble(Employee::getSalary).reversed());//按工资逆序排序 排序算法实现:Java语言直接将所有元素转入一个数组中,对数组进行排序,然后再将排序后的序列复制回列表。
-
混排
ArrayListcards = ...; Collections.shuffle(cards); 如果提供的列表没有实现RandomAccess接口,shuffle方法将元素复制到数组中,然后打乱数组元素的顺序,最后再将打乱顺序后的元素复制回列表。
-
-
二分查找
Collections类的binarySearch方法实现了这个算法。注意,
集合必须是排好序的。
-
-
简单算法
Collections.max()
Collections.replaceAll()
Collections.removeIf()
(Java SE 8)-
List.replaceAll()
(Java SE 8)eg:words.removeIf(w -> w.length() <= 3); words.replaceAll(String::toLowerCase);。。。
-
批操作
coll1.removeAll(coll2); //从coll1中删除coll2中出现的所有元素 coll1.retainAll(coll2); //从coll中删除所有未在coll2中出现的元素。(例如,生成交集)
-
集合与数组转换
数组 ---> 集合:
Arrays.asList包装器-
集合 ——> 数组:
复杂一点
Integer[] nums = new Integer[1024]; Listlist = Arrays.asList(nums); Integer[] integers = list.toArray(new Integer[0]); //提供一个所需类型而且长度为0的数组,返回的数组就会创建为相同的数组类型。 System.out.println(integers.length);//1024 list.toArray(); //返回Object[]数组 //如果愿意,可以创造一个指定大小的数组: list.toArray(new Integer[list.size()]); //这样不会创建新数组
-
遗留集合
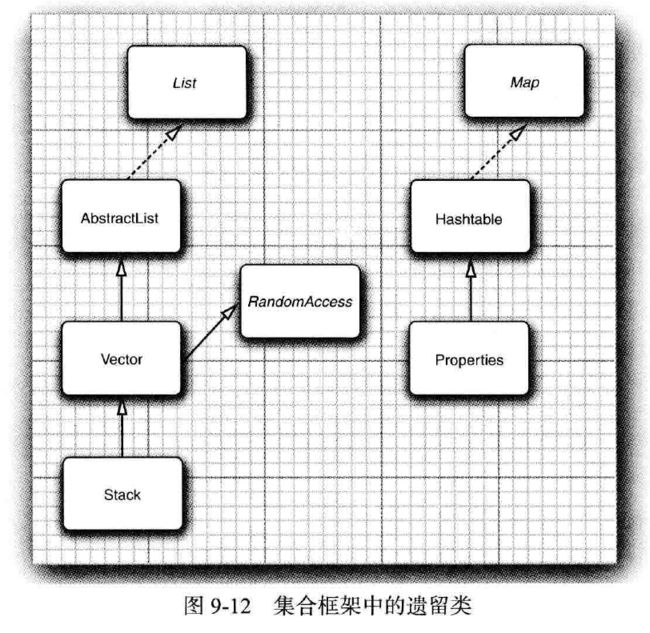 image
image-
Hashtable
与Vector类的方法一样。Hashtable的方法也是同步的。
应该使用 HashMap. 需要并发访问,则使用ConcurrentHashMap 枚举 Enumneration
属性映射 Properties
栈 Satck
位集 BitSet
-
10. 部署Java 应用程序
-
创建jar文件
jar cvf JARFILENAME file1 file2 ....
 image
image -
清单文件
除了类文件、图像和其他资源外,每个JAR文件还包含一个用于描述归档特征的清单文件(manifest)
清单文件被命名为MANIFEST,位于JAR文件的一个特殊MATA-INF子目录中。
11.并发
-
中断线程
没有可以强制线程终止的方法。然而, interrupt方法可以用来请求终止线程。对一个线程调用interrupt方法时,线程的中断状态将被置位。
但是,如果线程被阻塞,就无法检测中断状态。这是产生InterruptedException异常的地方。- interrput() : 向线程发送中断请求。
- Interrupted: 测试当前线程是否被中断,并清除线程的中断状态(副作用)。
- isInterrupted: 是一个静态方法,它检测当前的线程是否被中断。
- 在中断状态被置位时调用sleep方法,它不会休眠。相反,它将清除这一状态(!)并抛出InterruptionException。
-
线程状态
getState方法。获取线程当前状态。
- New(新建)
- Runnable(可运行)
- Blocked(被阻塞)
- Waiting(等待)
- Timed waiting (计时等待)
- Terminated(被终止)
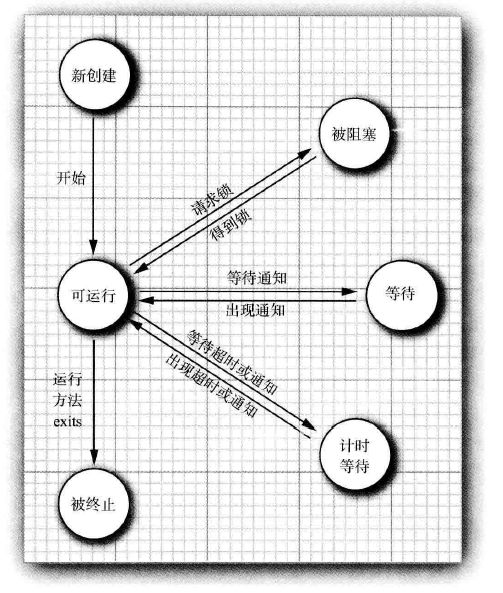 image
image
-
线程属性
-
线程优先级
setPriority():
- MIN_PRIORITY (1)
- MAX_PRIORITY (10)
- NORM_PRIORITY (5)
-
守护线程
t.setDaemon(true);
必须在线程启动之前调用-
当只剩下守护线程,虚拟机退出。
守护线程应该永远不去访问 固有资源,如文件、数据库,因为他会在任何时候甚至在一个操作的中间发生中断。
-
-
未捕获异常的处理器
线程run 方法不能抛出任何受检查异常, 但是, 非受检查会导致线程终止。在这种情况下,线程就死亡了。
-
-
同步
-
同时被两个线程访问
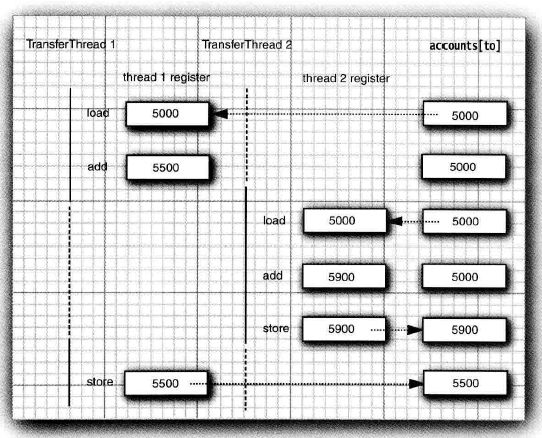 image
image
-
锁对象
有两种机制防止代码块受并发访问的干扰。
java 语言提供一个synchronized关键字。
-
Java SE 5.0引入了 ReentrantLock类。
myLock.lock(); //a ReentrantLock object try{ ... }finally{ myLock.unlock();//make sure the lock is unlocked even if an exception is thrown } //这一结构确保任何时刻只有一个线程进入临界区。一旦一个线程封锁了锁对象,其他任何线程都无法通过lock语句。当其他线程调用lock时,它们被阻塞,直到第一个线程释放锁对象。/** * @author chenchao * @Date 2018/7/4 下午2:38 */ public class bank { private Lock bankLock = new ReentrantLock(); public void transfer(){ bankLock.lock(); try{ System.out.println(Thread.currentThread()); }finally { bankLock.unlock(); } } }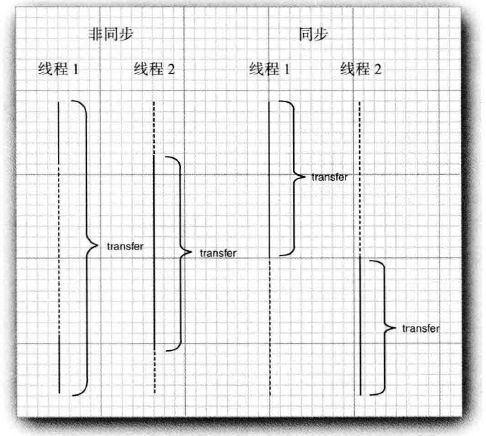 image
image
-
条件对象
/** * @author chenchao * @Date 2018/7/4 下午2:38 */ public class bank { private Lock bankLock = new ReentrantLock(); //获取条件对象 private Condition sufficientFunds = bankLock.newCondition(); public void transfer(int from, int to, int amount){ bankLock.lock(); 。。。 //如果transfer发现余额不足,它调用await try { while(accounts[from] < amount){ sufficientFunds.await(); //当前线程被阻塞, 并放弃锁 //直到另一线程调用同一条件上的signalAll方法时为止 : sufficientFunds.signalAll(); } } catch (InterruptedException e) { e.printStackTrace(); } try{ System.out.println(Thread.currentThread()); }finally { bankLock.unlock(); } } }sufficientFunds.signalAll();这一调用重新激活因为这一条件而等待的所有线程.在while 循环中能够确保条件满足,执行下面的转账任务。
-
> #### 锁和条件的关键:
>
> - 锁用来保护代码片段,任何时刻只能由一个县城执行该被保护的代码。
> - 锁可以管理试图进入被保护代码段的线程。
> - 锁可以拥有一个或多个相关的条件对象。
> - 每个条件对象管理那些已经进入被保护的代码段但还不能运行的线程。
-
synchronized关键字从1.0版本开始,Java中每个对象都有一个内部锁。如果一个方法用synchronized关键字声明。那么对象的锁将保护整个方法。----------》要调用该方法,线程必须获得内部的对象锁。
- wait(): 添加一个线程到等待集中。
- notify()/notifyAll() : 解除等待线程的阻塞状态
内部锁和条件存在一些局限性:
不能中断一个正在试图获得锁的线程。
试图获得锁时不能设定超时。
每个锁仅有单一的条件,可能是不够的。
##### 使用Lock和Condition对象还是同步方法?下面一些建议:
- 最好既不使用Lock/Condition也不使用synchronized关键字。
- 如果synchronized关键字适合你的程序,那么请尽量使用它,这样可以减少编写的代码数量,减少出错的几率。
- 如果特别需要Lock/Condition结构提供的独有特性时,才使用Lock/Condition。
-
同步阻塞每个Java对象拥有一个锁。线程可以通过调用同步方法获得锁。还有另一种机制也可以获得锁,通过进入一个同步阻塞。
synchronized(obj){ //this is a syntax for a synchronized block .... } //获得obj的锁//有时会发现"特殊的"锁 public class Bank{ private Object object = new Object(); public void transfer(int from, int amount){ synchronized(object){ //add ad-hoc lock .... } } }
-
Volatitle域-
多处理器的计算能够暂时在寄存器或本地内存缓存中保存内存中的值。结果是,运行在不同处理器上的线程可能同一时间在同一内存位置取到不同的值。
编译器可以改变指令执行的顺序以使吞吐量最大化。这种顺序上的变化不会改变代码语义,但是编译器假定内存的值仅仅在代码中有显式的修改指令时才会改变。然而,内存的值可以被另一个线程改变。
-
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatitle修饰之后:
1. 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2. 禁止进行指令重排序。
可见性只能保证每次读取的是最新的值,但是volatitle没办法保证对变量的操作的原子性。
-
final变量除非使用锁或volatitle修饰符,否则无法从多个线程安全地读取一个域。
还有一种方法可以安全地访问一个共享域,即这个域声明为final时
-
原子性可以保证即使是对个线程并发地访问同一个实例,也会计算并返回正确的值(例:获取自增值 )
-
Java.util.concurrent.atomic包中有很多类使用很高效的机器级指令(而不是使用锁)来保证其他操作的原子性。
eg:
AtomicInteger类提供了方法incrementAndGet和decrementAndGet,它们分别以原子方式将一个整数自增或自减。public static AtomicLong largest = new AtomicLong(); largest.updateAndGet(x -> Math(x, observed)); //或 largest.accumulateAndGet(obversed, Math::max);
-
- `如果有大量线程要访问相同的原子值,性能会大幅下降,因为乐观锁更新需要太多次重试。`
- java SE 8提供了`LongAdder`和`LongAccumulator`类来解决这个问题。
- 如果认为有大量竞争,只需使用LongAdder而不是AtomicLong.
-
线程局部变量有时可能要避免共享变量,使用
ThreadLocal辅助类为各个线程提供各自的实例。public static final ThreadLocaldatteFormat = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyy-MM-dd")); //使用 String dateStamp = dateFormat.get().format(new Date());
-
线程安全的集合
-
高效地映射、集和队列
ConcurrentHashMap : 可以被多线程安全访问的散列映射表
ConcurrentSkipListMap :
ConcurrentSkipListSet : 可以被多线程安全访问的有序集
-
ConcurrentLinkedQueue : 可以被多线程安全访问的无边界非阻塞队列
这些集合使用复杂的算法,通过允许并发访问数据结构的不同部分来使竞争极小化。
-
-
写数组的拷贝
CopyOnWriteArrayList和CopyOnWriteArraySet是线程安全的集合所有的修改线程对底层数组进行复制。
(如果在集合上进行迭代的线程数超过修改线程数,这样的安排是很有用的。)构建迭代器时,包含一个对当前数组的引用。如果数据被修改,迭代器仍然引用旧数组,但是集合数组已经被替换了。(因此,旧的迭代器拥有一致的
(可能过时)的视图, 访问它无需任何同步开销)。
-
较早的线程安全
任何集合类都可以使用同步包装器(synchronization wrapper)变成变成安全的:
ListsynchArrayList = Collections.synchronizedList(new ArrayList ()); Map 最好使用java.util.concurrent包中定义的集合,不适用同步包装器中的。
-
Callable与Future
Callable与Runnable类似,但是有返回值。
-
Future保存返回值的类型
FutureTaskfutureTask = new FutureTask<>(new Callable () { @Override public Integer call() throws Exception { Thread.sleep(5000); return 1; } }); Thread thread = new Thread(futureTask); thread.start(); while (!futureTask.isDone()){ //判断线程是否执行完 try { System.out.println(futureTask.get()); //直接get()会阻塞知道线程执行完成 } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } }
-
执行器
-
线程池
如果程序中创建了大量的生命期很短的线程,应该使用线程池(thread pool)执行器(Executor)类有许多静态工厂方法来构建线程池:
 image
image image
image -
预定执行
ScheduledExecutorService接口具有为预定执行 ( Scheduled Execution ) 或 重 复 执 行 任
务而设计的方法 。 它是一种允许使用线程池机制的 java. util . Timer 的泛化 。 Executors 类的
newScheduledThreadPool和newSingleThreadScheduledExecutor方法将返回实现了 Scheduled
ExecutorService 接口 的对象 。//预定在指定的时间之后执行任务 scheduledExecutorService.schedule(()-> System.out.println(Thread.currentThread().getId()), 5, TimeUnit.SECONDS); //预定在初始的延迟结束后 , 周期性地运行给定的任务 , 周期长度是 period scheduledExecutorService.scheduleAtFixedRate(()-> System.out.println(Thread.currentThread().getId()), 5, 2, TimeUnit.SECONDS); //预定在初始的延迟结束后周期性地运行给定的任务 , 在一次调用完成和下一次调用开始之间有长度为 delay 的延迟 scheduledExecutorService.scheduleWithFixedDelay(()-> System.out.println(Thread.currentThread().getId()), 5, 2, TimeUnit.SECONDS);
-
-
控制任务组
// invokeAny 方法提交所有对象到一个 Callable 对象的集合中, 并返回某个已经完成了的任务的结果 Listresult : results) processFurther(result.get()); //这个方法的缺点是如果第一个任务恰巧花去了很多时间,则可能不得不进行等待。 将结果按可获得的顺序保存起来更有实际意义 。 可以用
ExecutorCompletionService来进行排列 。ExecutorCompletionServiceservice = new ExecutorCompletionService<>(executor); for(Callable task : tasks) service.submit(task); for(int i = 0; i < tasks.size(); i++){ processFurther(service.take().get()); }
-
Fork-Join框架
在后台,fork-join框架使用了一种有效的只能方法来平衡可用线程的工作负载,这种方法称为
工作密取(work stealing)。每个工作线程都有一个双端队列(deque)来完成工作。一个工作线程将子任务压入其双端队列的对头。(只有一个线程可以访问队头,所以不需要加锁)一个工作线程空闲时,它会从另一个双端队列的队尾“密取”一个任务。由于大的子任务都在队尾,这种密取很少出现。/** * @author chenchao * @Date 2018/8/2 下午2:33 */ public class ForkJoinTest { public static void main(String[] args) { final int SIZE = 1000000; double[] numbers = new double[SIZE]; for (int i = 0; i < SIZE; i++) { numbers[i] = Math.random(); } Counter counter = new Counter(numbers, 0, numbers.length, x -> x>0.5); ForkJoinPool forkJoinPool = new ForkJoinPool(); forkJoinPool.invoke(counter); System.out.println(counter.join()); } } class Counter extends RecursiveTask{ public static final int THRESHOLD = 1000; private double[] values; private int from; private int to; private DoublePredicate filter; public Counter(double[] values, int from, int to, DoublePredicate filter){ this.values = values; this.from = from; this.to = to; this.filter = filter; } @Override protected Integer compute() { if(to - from < THRESHOLD){ int count = 0; for (int i = from; i < to; i++) { if(filter.test(values[i])){ count++; } } return count; }else { int mid = (from + to)/2; Counter first = new Counter(values, from, mid, filter); Counter second = new Counter(values, mid, to, filter); invokeAll(first, second); return first.join() + second.join(); } } }
-
可完成Future
Java SE8 的
CompletableFutureeg: 从一个页面抽取所有链接来建立一个爬虫。
CompletableFuturecontents = readPage(url); CompletableFuture 利用可完成future,可以指定你希望做什么,以及希望以什么顺序执行这些工作