一、xlsx 包介绍
虽然平时处理的文件一般都是txt 、csv文件,但其可读性不如xlsx文件,在给别人展示你的分析结果时,一般就会用到xlsx文件。
试了很多包,比如...(我也忘了叫什么名字了),但论功能,xlsx的功能最多,最好用,但安装有点麻烦。我觉得大家还是值得一试的
二、安装
1. 在Rstudio上安装:
xlsx 是可用于基于 java 写的,调用 java 的函数,所以需要系统先安装 java 。然后在R里安装rJava和xlsx两个包就行了。
- 安装 java
下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html, 需注册。
我是Window 64位,下载介个:
我的安装路径:D:\Java\jdk1.8.0_261,后面要用。
- 添加 java 环境变量
打开设置,搜索环境变量:
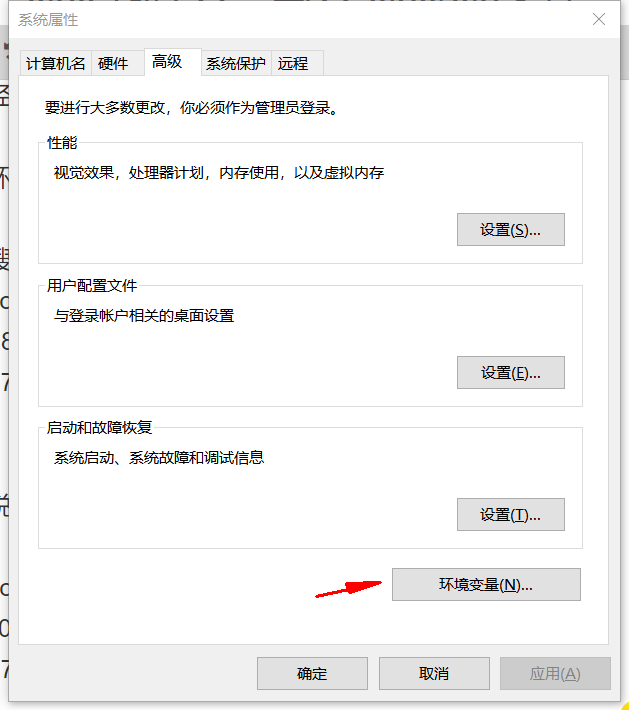
打开环境变量:

点击下方系统变量的
新建
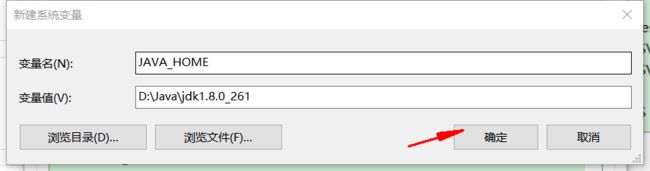
变量名设为:JAVA_HOME,咱都一样的。
变量值就是刚才说的 java 安装路径,咱可能不一样,我的是D:\Java\jdk1.8.0_261。
确定 > > 确定
重启R(需不需要我也不知道),输入:
Sys.getenv("JAVA_HOME")
结果如下图,则完成 java 环境配置。

- 安装
rJava包
在 Rstudio 里安装rJava包:
install.packages("rJava")
library("rJava")
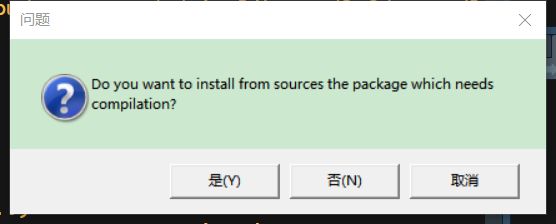
如果蹦出来个下面的框说什么需要编译,选否,反正我选是不能安装成功
- 安装
xlsx包
在 Rstudio 里安装xlsx包:
install.packages("xlsx")
library("xlsx")

warning 咱不用管哈。
到这里安装步骤就完成了。
2 在服务器上安装
- 下载jdk至服务器
-
解压:

- 添加java环境变量:
在~/.bashrc里加入:
注意把中文换成路径
export JAVA_HOME=解压的包所在路径/jdk1.8.0_261
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$JAVA_HOME/bin:$PATH
- 先安装R包
rJava
install.packages("rJava")
如果安装成功则继续安装xlsx:
install.packages("xlsx") - 如果报错,那就麻烦了,反正我捯饬了很久,没法给出普适的解决方案
我只给出可能的解决方案:- 如果在
java lib /user/bin/...这一行报错:
运行:
- 如果在
R CMD javareconf JAVAC=/sibcb2/bioinformatics2/wangjiahao/software/java/jdk1.8.0_261/bin/javac JAR=/sibcb2/bioinformatics2/wangjiahao/software/java/jdk1.8.0_261/bin/jar JAVAH=/sibcb2/bioinformatics2/wangjiahao/software/java/jdk1.8.0_261/bin/javah
注意要把我的软件路径改成你的。
继续安装rJava
- 如果又报错,我找到的解决方法是往
LD_LIBRARY_PATH里面加个server:
export LD_LIBRARY_PATH=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre/lib/amd64/server:$LD_LIBRARY_PATH
具体加哪个sever我也不知道,多试试
之后,rJava我就安装成功了,xlsx也就安装成功了
三、xlsx包的用法
用法很简单,最常用的两个函数:read.xlsx()、write.xlsx(),详情查看:https://cran.r-project.org/web/packages/xlsx/xlsx.pdf
read.xlsx()
read.xlsx(
file,
sheetIndex,
sheetName = NULL,
rowIndex = NULL,
startRow = NULL,
endRow = NULL,
colIndex = NULL,
as.data.frame = TRUE,
header = TRUE,
colClasses = NA,
keepFormulas = FALSE,
encoding = "unknown",
password = NULL,
...
)z
file:文件路径,必需
sheetIndex: [number] 要读取表中哪个 sheet,必需
rowIndex: [number vector] 要读取的行的范围
colIndex: [number vector] 要读列的列的范围
header: 是否读取表头,默认TRUE,数据有列名则设 TRUE
还有一个 col.names 选项,默认FLASE,数据有行名则设 TRUE,不知道这个选项官方文档为什么没有
write.xlsx()
write.xlsx(
x,
file,
sheetName = "Sheet1",
col.names = TRUE,
row.names = TRUE,
append = FALSE,
showNA = TRUE,
password = NULL
)
x: 要保存一个数据框,如果不是会强制转换为数据框,不过我发现强制转换会有点问题,所以最好手动转换
file: 要保存的文件名,同样这两个是必须的参数
sheetName: 指定保存的sheet名字
col.names: 是否保存列名,默认是
row.name: 是否保存行名,默认是
append: 是否追加写入,就是可以将一个sheet追加到一个已经存在的xlsx文件里,默认否
- 示例
x=matrix(c(1:12),3,4)
y=matrix(c(10:22),3,4)
dimnames(x) = list(c(1,2,3), c(1,2,3,4))
dimnames(y) = list(c(1,2,3), c(1,2,3,4))
> x
1 2 3 4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
# 写入
write.xlsx(x, "test1.xlsx", sheetName = "test1", col.names = F, row.names = F)
write.xlsx(y, "test1.xlsx", sheetName = "test2", append = T, col.names = F, row.names = F)
# 读取
data_x = read.xlsx("test1.xlsx", 1, header = F)
data_y = read.xlsx("test1.xlsx", 2, header = F)
sub_data_x = read.xlsx("test1.xlsx", 1, header = F, colIndex = c(1:2), rowIndex = c(2:3))