一般性原则
根据数据而不是凭空猜测
这是性能优化的第一原则,当我们怀疑性能有问题的时候,应该通过测试,日志,profillig来分析出哪里有问题,有的放矢,而不是凭感觉,撞运气。有可能是CPU,有可能是内存,有可能是IO(磁盘IO,网络IO),大方向的定位可以使用top以及stat系列来定位(vmstat,iostat,netstat ...),针对进程,可以使用pidstat来分析。
在此处中,主要讨论的是CPU相关的性能问题。按照80/20定律,一段时间的时间都耗费在少量的代码片段里面,发现这些代码唯一可靠的方法就是profile,我所知的编程语言,都有相关的配置文件工具,熟练使用这些配置文件工具是性能优化的第一步。
忌过早优化
真正的问题是程序员花了太多时间来担心在错误的地方和错误的时间效率。过早的优化是编程中所有邪恶(或至少是大多数邪恶)的根源。
我并不十分清楚Donald Knuth说出这句名言的某些环境,但我自己是十分认同这个观念的。在我的工作环境(以及典型的互联网应用开发)与编程模式下,追求的是快速的交替与试错,过早的优化往往是无用功。而且,过早的优化很容易拍脑袋,优化的点往往不是真正的性能指标。
忌过度优化
由于性能是程序规范的一部分,因此,速度太慢的程序不适合目标用途
性能优化的目标是追求合适的性价比。
在不同的阶段,我们对系统的性能会有一定的要求,某种程度的变形要达到一定数量。如果达不到这个指标,就需要去优化。如果能满足预期,那么就不用花费时间精力去优化,一种只有几十个人使用的内部系统,就不用遵循十万在线的目标去优化。
而且,后面也会提到,一些优化方法是“有损”的,可能引发代码的扭曲性,可维护性有替代。这个时候,就更不能过度优化。
深入理解业务
代码是服务于业务的,也许是服务于最终用户,也许是服务于其他程序员。不了解业务,很难理解系统的流程,很难引起系统设计的不足之处。业务理解的本质。
性能优化是持久战
当核心业务方向明确之后,就应该开始关注性能问题,当项目上线之后,更应该持续的进行性能检测与优化。
现在的互联网产品,不再是一锤子买卖,在上线之后还需要持续的开发,用户的涌入也会带来性能问题。因此需要自动化的检测性能问题,保持稳定的测试环境,持续的发现并解决性能问题,而不是被动地等到用户的投诉。
选择合适的指标指标,测试用例,测试环境
正因为性能优化是一个长期的行为,所以需要固定的指标,测试用例,测试环境,这样才能客观反映性能的实际情况,也能展现出优化的效果。
的性能核心指标是不一样的,首先要明确本系统的核心性能诉求,固定测试用例;其次也要兼顾其他指标,不能顾此失彼。
测试环境也很重要,有一次突然发现我们的QPS高了很多,但是程序压根儿没优化,查了半天,才发现是换了一个更牛逼的物理机做测试服务器。
性能优化的层次
(https://www.cnblogs.com/xybab ...
按照我的理解可以分为需求阶段,设计阶段,实现阶段;越上层的阶段优化效果越明显,同时也更需要对业务,需求的深入理解。
需求阶段
不战而屈人之兵,善之善者也也
程序员的需求可能来自PM,UI的业务需求(或者说是功能性需求),也可能来自Team Leader的需求。当我们拿到一个需求的时候,首先需要的是思考,讨论需求的合理性,而不是立刻去设计,去编码。
需求是能否解决某个问题,问题是本质,需求是解决问题的手段。那么需求是否能够真正的解决问题,程序员也得自己去思考,在之前的文章也提到过,产品经理(特别是知道一点技术的产品经理)的某个需求可能只是某个问题的解决方案,他认为这个方法可以解决他的问题,于是把解决方案当成为需求,而不是真正的问题。
需求讨论的前提对业务的深入了解,如果不了解业务,根本没法讨论。甚至需求已经实现了,当我们发现有性能问题的时候,首先也可以从需求出发。
需求分析对性能优化有什么帮助呢,第一,为了达到相同的目的,解决同样问题,也许可以有性能更优(消耗更小)的方法。这种优化是无损的,即不改变需求本质的同时,又能达到性能优化的效果;第二种情况,有损的优化,即在不明显影响用户的体验,稍微修改需求,放宽条件,可以大大解决性能问题。PM退步一小步,程序前进一大步。
需求讨论也有助于设计时扩展性,应对未来的需求变化,这里点击不表。
设计阶段
高手都是花80%时间思考,20%时间实现;新手写起码来很快,但后面是无穷无尽的修bug
设计的概念很宽泛,包括架构设计,技术选型,接口设计等等。架构设计约束了系统的扩展,技术选型决定了代码实现。编程语言,框架都是工具,不同的系统,业务需要选择适当的工具集。如果设计的时候做的不够好,那么后面就很难优化,甚至需要推到重来。
实现阶段
实现是把功能翻译成代码的过程,这个目标的优化,主要是针对一个调用流程,一个函数,一段代码的优化。各种配置文件工具也主要是在这个阶段实现。除了静态的代码的优化,还后两者要求就很高了,程序员可控性较弱。
代码本身,造成性能降低的原因通常是异步调用的函数,或者单次消耗非常高的函数,或者两者的结合。
下面介绍针对设计阶段与实现阶段的优化手段。
一般性方法
(https://www.cnblogs.com/xybab ...
缓存
没有什么性能问题是缓存解决不了的,如果有,那就再加一级缓存
缓存/kæʃ/ KASH,[1]是存储数据的硬件或软件组件,因此可以更快地满足对该数据的将来请求;存储在缓存中的数据可能是较早计算的结果,或者是存储在其他位置的数据的重复。
缓存的本质是加速访问,访问的数据或者是其他数据的副本-让数据离用户更近;或者是之前的计算结果-避免重复计算。
缓存需要用空间换时间,在缓存空间有限的情况下,需要优秀的替换转换来保证缓存有更高的命中率。
数据的缓存
这是我们最常见的缓存形式,将数据缓存在离用户更近的地方。诸如操作系统中的CPU缓存,磁盘缓存。对于一个Web应用,前端会有浏览器缓存,有CDN,有反向代理提供的静态内容缓存;临时则有本地缓存,分布式缓存。
数据的缓存,很多时候是设计预算的考虑。
对于数据缓存,需要考虑的是缓存一致性问题。对于分布式系统中有强一致性要求的场景,可行的解决方法有租赁,版本号。
计算结果的缓存
对于消耗同轴的计算,可以将计算结果缓存起来,下次直接使用。
我们知道,对递归归零的一个有效优化手段就是缓存中间结果,查找表,避免了重复计算。python中的方法缓存就是这种思想。
对于可能重复创建,销毁,并且创建销毁代价很大的对象,诸如此类的进展,线程,也可以缓存,对应的缓存形式如单例,资源池(连接池,线程池)。
对于计算结果的缓存,也需要考虑缓存重新存储的情况,对于纯函数,固定的输入有固定的输出,缓存是不会重复的。可能失效,某些我在前面提到的python方法缓存
并发
一个人干不完的活,那就找两个人干。并发既增加了系统的吞吐,又减少了用户的平均等待时间。
这里的并发是指广义的并发,粒度包括多台机器(例如),多进程,多线程。
对于无状态(状态是指需要维护的上下文环境,用户请求依赖于这些上下文环境)的服务,采用能够很好的扩展,增加系统的吞吐,少量挂载nginx之后的网络服务器
对于有状态的服务,也有两种形式,每个都有提供同样的数据,如mysql的读写分离;每个实例只提供部分数据,如mongodb中的分片
分布式存储系统中,分区(分片)和复制(备份)都有助于并发。
最早的网络服务器,可以使用多进程,或者使用多线程来处理用户的请求,以充分利用多核CPU,再有IO的地方,也是适合使用多线程的。比较新的协程(Python greenle, goroutine)也是一种并发。
惰性
将要计算出到必要的时刻,这样很可能避免了多余的计算,甚至根本不用计算,这个在之前的《编程中的懒惰思想》。
CopyOnWrite这个思想真牛逼!
批量,合并
在有IO(网络IO,磁盘IO)的时候,合并操作,批量操作经常能提升吞吐,提高性能。
如GFS客户会从GFS master多读取一些chunk信息;如分布式系统中,如果集中式节点,则我们最常见的是批量读:每次读取数据的时候多读取一些,以备不时之需。复杂的ID生成,俺么应用就可以一次请求资助id。
特别是系统中有单点存在的时候,缓存和批量本质上来说减少了与单点的相互作用,是还原单点压力的经济有效的方法
在前端开发中,经常会有资源的压缩和合并,也是这种思想。
当涉及到网络请求的时候,网络传输的时间可能远大于请求的处理时间,因此合并网络请求就很有必要,例如,mognodb的批量操作,redis的管道。写文件的时候也可以批量写,以减少IO支出,GFS中就是这么干的
更高效的实现
同一个算法,肯定会有不同的实现,那么就会有不同的性能;有的实现可能是时间换空间,有的实现可能是空间换时间,那么就需要根据自己的实际情况权衡。
程序员都喜欢早轮,用于练手无可厚非,但在项目中,使用成熟的,通过验证的车轮经常比自己造的轮子性能更好。当然不管使用别人的轮子,还是自己的工具,当出现性能的问题的时候,或者优化它,替换替换他。
例如,我们有一个场景,有大量复杂的嵌套对象的序列化,反序列化,开始的时候是使用python(Cpython)自带的json模块,即使发现有性能问题也没法优化,网上一查,替换为ujson,性能好了过多。
上面这个例子是无损的,但一些更高效的实现也可能是有损的,某种对于python,如果发现性能有问题,那么很可能会考虑C扩展,但也会带来维护性与降低的丧失,面临崩溃的风险。
缩小解空间
缩小解空间的意思是说,在一个更小的数据范围内进行计算,而不是遍历全部数据。最常见的就是索引,通过索引,能够很快定位数据,对数据库的优化最多时候都是对索引的优化。
如果,本地缓存,那么使用索引也会大大加快访问速度。不过,索引比较适合读多写少的情况,毕竟索引的生成也是需要有消耗的。
另外在游戏服务端,使用的分线和AOI(格子算法)也都是缩小解空间的方法。
性能优化与代码质量
(https://www.cnblogs.com/xybab ...
对于Python,pythonic的代码通常效率都不错,如使用交替器而不是列表(python2.7 dict的iteritems(),而不是items())。
分辨率代码质量的标准是预测性,可维护性,可扩展性,但性能优化有可能会违背这些特性,从而为了屏蔽实现细节与使用方式,我们会可能会加入接口层(虚拟层),这样预期性,可维护性,可扩展性会好很多,但是额外增加了一个函数调用,如果这个地方调用替换,那么也是一笔费用;又如前面提到的C扩展,也是会降低可维护性,
这种有损代码质量的优化,应该放到最后,不得已而为之,同时写清楚注释与文档。
为了追求可扩展性,我们经常会约会一些设计模式,如状态模式,策略模式,模板方法,装饰器模式等,但这些模式不一定是性能友好的。所以,为了性能,我们可能写出一些反模式的,定制化的,不那么优雅的代码,这些代码实际上是脆弱的,需求的一点点变化,对代码逻辑可能有严重的影响,所以还是回到前面说,不要过早优化,不要过度优化。
总结
(https://www.cnblogs.com/xybab ...
来张脑图总结一下
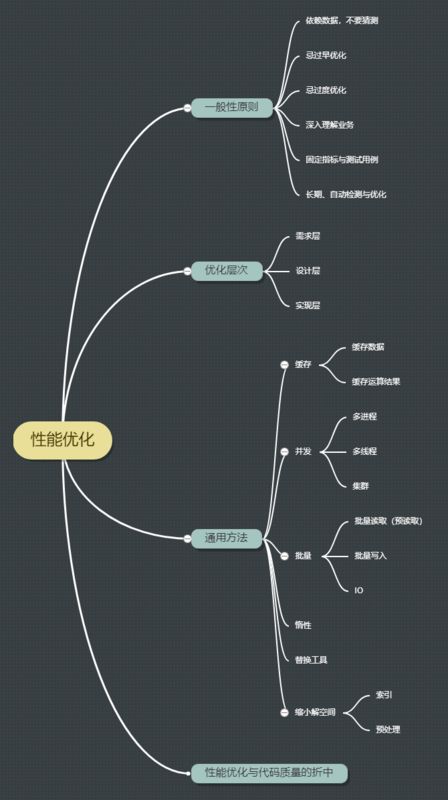
推荐阅读:
TCP的三次握手,四次挥手加IP,SOCKET全景图,面试有备无患!https://www.bilibili.com/video/BV1HQ4y1M7oe/
资深架构师马士兵读解多线程,线程池原理,给Java程序员职业把脉,让你薪资翻一翻!https://www.bilibili.com/video/BV1BE411A78Z/
阿里P9架构师120分钟带你掌握线程池,不在为线程而烦恼
https://www.bilibili.com/video/BV1GE411N7sc/