| 类 | 容器类型 | 线程安全实现方式 | 是否支持阻塞 | 是否针对并发有性能优化 | 其他 |
|---|---|---|---|---|---|
| CopyOnWriteArrayList | List | 数组拷贝+互斥锁 | 否 | 是,支持并发读 | |
| CopyOnWriteArraySet | Set | 数组拷贝+互斥锁 | 否 | 是,支持并发读 | 基于CopyOnWriteArrayList实现 |
| ConcurrentHashMap | Map | 锁分段 | 否 | 是,支持并发读操作并且支持不同分段下的并发写操作 | 基于多个子哈希表实现 |
| ConcurrentSkipListMap | Map | CAS操作 + 自旋 | 否 | 是,不需要加锁操作 | 基于跳表实现 |
| ConcurrentSkipListSet | Set | CAS操作 + 自旋 | 否 | 是,不需要加锁操作 | 基于ConcurrentSkipListMap实现 |
| ConcurrentLinkedQueue | Queue | CAS操作 + 自旋 | 否 | 是,不需要加锁操作 | |
| ArrayBlockingQueue | Queue | 互斥锁 | 是 | 否 | |
| LinkedBlockingQueue | Queue | 互斥锁 | 是 | 否 | |
| LinkedBlockingDeque | Deque | 互斥锁 | 是 | 否 |
一、CopyOnWriteArrayList
1. 类型
Collection - List
2. 数据结构
动态数组
3. 重要实现
a. 读写分离
内部使用“volatile数组”来存储数据。在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile数组”。由于在“添加/修改/删除”数据时,都会新建数组,所以涉及到修改数据的操作,CopyOnWriteArrayList效率很低;但是单单只是进行遍历查找的话,效率比较高。
b. 线程安全
通过volatile和互斥锁来实现的。
- 通过volatile数组保存数据。一个线程读取volatile数组时,总能看到其它线程对该volatile变量最后的写入;就这样,通过volatile提供了“读取到的数据总是最新的”这个机制的保证。
- 通过互斥锁来保护数据。在“添加/修改/删除”数据时,会先“获取互斥锁”,再修改完毕之后,先将数据更新到“volatile数组”中,然后再“释放互斥锁”;这样,就达到了保护数据的目的。
4. 特点
- 读操作不需要加锁等同步措施,运行速度快
- 修改操作需要新建一个数组并将原有数据拷贝到新数组中,效率较低。并且在数组元素较多的情况下需要占用的内存空间较大
5. 适用场景
CopyOnWriteArrayList适合用在“读多,写少”的“并发”应用中,换句话说,它适合使用在读操作远远大于写操作的场景里。
二、CopyOnWriteArraySet
1. 类型
Collection - Set
2. 数据结构
基于CopyOnWriteArrayList实现,即动态数组
3.重要实现
基于CopyOnWriteArrayList实现,因此实现原理同CopyOnWriteArrayList。
a. 元素不重复
通过调用CopyOnWriteArrayList的addIfAbsent()和addAllAbsent()两个方法,保证没有重复元素。
4.特点
同CopyOnWriteArrayList,读操作时运行速度快,“添加、删除、修改”操作时效率低
5.适用场景
同CopyOnWriteArrayList
三、ConcurrentHashMap
1. 类型
Map
2. 数据结构
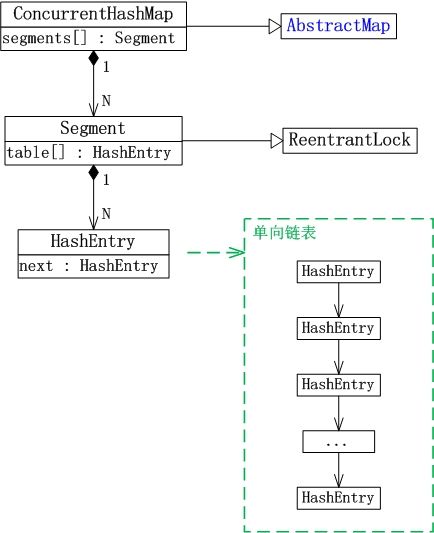
Segment是ConcurrentHashMap中的内部类,1个ConcurrentHashMap对象包含若干个Segment对象。
HashEntry是ConcurrentHashMap的内部类,是单向链表节点,存储着key-value键值对。Segment类中存在“HashEntry数组”成员。
3. 重要实现
a. 线程安全实现原理
对于添加,删除等操作,通过“锁分段”实现。ConcurrentHashMap中包括了“Segment数组”,每个Segment就是一个哈希表,而且也是可重入的互斥锁。在操作开始前,会先获取Segment的互斥锁;操作完毕之后,才会释放。
对于读取操作,通过volatile去实现的。HashEntry数组是volatile类型的,而volatile能保证“即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入”,即我们总能读到其它线程写入HashEntry之后的值。
以上这些方式,就是ConcurrentHashMap线程安全的实现原理。
4. 特点
- 对于读操作,不需要加锁等操作,访问速度快
- 对于“添加、删除、修改”等操作,如果是不同segment,支持并发访问,如果是同一segment,需要同步访问
5. 适用场景
ConcurrentHashMap对并发的控制较为细腻,适应于高并发场景。
6. ConcurrentHashMap和HashTable的区别
Hashtable是线程安全的哈希表,通过synchronized来保证线程安全的;即,多线程通过同一个“对象的同步锁”来实现并发控制。Hashtable在线程竞争激烈时,效率比较低,因为当一个线程访问Hashtable的同步方法时,其它线程就访问Hashtable的同步方法时,可能会进入阻塞状态。
ConcurrentHashMap是线程安全的哈希表,通过“锁分段”来保证线程安全的。ConcurrentHashMap将哈希表分成许多片段(Segment),每一个片段除了保存哈希表之外,本质上也是一个“可重入的互斥锁”(ReentrantLock)。多线程对同一个片段的访问,是互斥的;但是,对于不同片段的访问,是可以并发进行的。
四、ConcurrentSkipListMap
1. 类型
Map
2. 数据结构
跳表
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
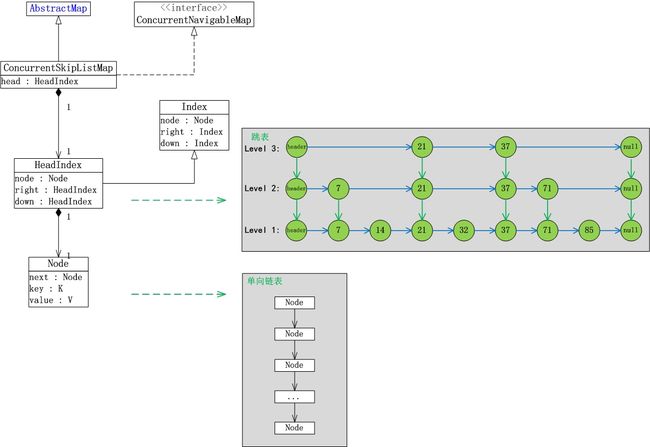
查找方式:
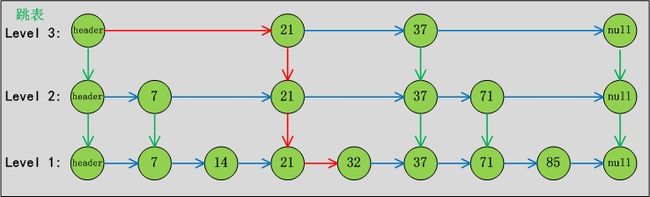
普通链表查找方式,如下图顺序查找,查找到“32”共需要4步。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找,如下图,查找到“32”共需要2步(不包括垂直的跳跃)。
复杂度分析:
参考文档:http://blog.sina.com.cn/s/blog_68f6d5370102uykh.html
每个跳表需要确定一个概率因子,表明对于每一层来说每添加一个节点,把这个节点添加到上层的概率。概率因子一般用1/2或1/e ,下面使用P代替。
空间复杂度:S = n + n/P + n/(P^2) + ... + n/(P^n) < n(1 + 1/P + 1/(P^2) + ... + 1/P∞) =2n,因此空间复杂度为 2n = O(n)
高度:对每层来说,它会向上增长的概率为1/P,则第m层向上增长的概率为1/(P^m);n个元素,则在m层元素数目的期待为Em = n/(P^m);当Em = 1,m = logp(n)即为层数的期待。故其高度期待为 Eh = O(logn)。
查询复杂度:为高度/p,即O(logn)
插入/删除复杂度: 插入和删除都由查找和更新两部分构成。查找的时间复杂度为O(logn),更新部分的复杂度又与跳跃表的高度成正比,即也为O(logn)。
所以,插入和删除操作的时间复杂度都为O(logn) 。
3. 重要实现
线程安全实现原理
利用底层的插入、删除的CAS原子性操作,通过死循环不断获取最新的结点指针来保证不会出现竞态条件。
4. ConcurrentSkipListMap和TreeMap的区别
- 线程安全性不同
- 实现有序的数据结构不同,TreeMap使用红黑树实现、ConcurrentSkipListMap使用跳表实现
五、ConcurrentSkipListSet
1. 类型
Collection - Set
2. 数据结构
基于ConcurrentSkipListMap实现
3.重要实现
基于CopyOnWriteArrayList实现,因此实现原理同CopyOnWriteArrayList。
六、ArrayBlockingQueue
1. 类型
Collection - Queue
2. 特点
数组实现的线程安全的有界的阻塞队列
3. 数据结构
数组
4. 重要实现
a. 线程安全实现原理
使用“互斥锁”ReentrantLock实现线程安全。在public方法中都使用ReentrantLock加锁,实现线程安全。
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
b. block实现原理
ReentrantLock两个锁,notEmpty用来表示是否为空列表,notFull用来表示队列是否已满。
notEmpty = lock.newCondition();
notFull = lock.newCondition();
ArrayBlockingQueue中put/take方法为阻塞方法。
put:若队列已满,notFull.await(),当元素被消耗或者删除时,notFull.signal()。
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await(); //如果队列已满,则wait,并放弃目前得到锁。
enqueue(e);
} finally {
lock.unlock();
}
}
take:若队列为空,notEmpty.wait(),当元素被添加时,notEmpty.signal()。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await(); //如果队列为空,则wait,并放弃目前得到锁。
return dequeue();
} finally {
lock.unlock();
}
}
5. 其他
take/put
阻塞方法
add/remove/element
非阻塞方法,当队列已满或队列为空导致执行失败时,抛出IIIegaISlabEepeplian/NoSuchElementException异常
offer/poll/peek
非阻塞方法,当队列已满或队列为空导致执行失败时,返回false/null表示执行失败。
七、LinkedBlockingQueue
1. 类型
Collection - Queue
2. 特点
单向链表实现的线程安全的无界的阻塞队列
3. 数据结构
单向链表
4. 重要实现
a. 线程安全实现原理
使用“互斥锁”ReentrantLock实现。由于链表的插入和删除不会影响整个数据结构(对于数组实现的ArrayBlockingQueue,插入和删除都要修改整个数据结构),因此使用takeLock和putLock两个锁,获取数据时使用takeLock,添加数据时使用putLock。
private final ReentrantLock takeLock = new ReentrantLock();
private final ReentrantLock putLock = new ReentrantLock();
5. 阻塞实现原理
两个ReentrantLock,两个condition,notEmpty用来表示是否为空列表,notFull用来表示队列是否已满。
-- 若某线程(线程A)要取出数据时,队列正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向队列中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。 此外,线程A在执行取操作前,会获取takeLock,在取操作执行完毕再释放takeLock。
-- 若某线程(线程H)要插入数据时,队列已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 此外,线程H在执行插入操作前,会获取putLock,在插入操作执行完毕才释放putLock。
take:
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly(); //加锁
try {
while (count.get() == 0) { //数量为0
notEmpty.await(); //等待并释放锁
}
x = dequeue(); //put方法notEmpty.signal(),唤醒并获取数据
c = count.getAndDecrement(); //数量减1,此时拿到的c是减之前的数据
if (c > 1) //c >= 2,表示拿完数据以后还有数据,继续唤醒其他的消费者
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity) //原先的数量是满的,此时消耗了一个,通知其他生产者可以生产了
signalNotFull();
return x;
}
put:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node node = new Node(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
notFull.await(); //等待并释放锁
}
enqueue(node); //添加到队列里
c = count.getAndIncrement(); //增加数量
if (c + 1 < capacity) //还有容量,通知其他生产者继续生产
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0) //从无变有,通知消耗者可以消耗了
signalNotEmpty();
}
八、LinkedBlockingDeque
1. 类型
Collection - Queue - Deque
2. 特点
双向链表实现的双向并发阻塞队列
3. 数据结构
双向链表
4. 重要实现
包括一个“互斥锁”和两个“Condition”
final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
private final Condition notFull = lock.newCondition();
线程安全实现原理
所有public方法使用ReentrantLock包括,保证其线程安全性。
阻塞实现原理
使用notEmpty和notFull实现阻塞。
注意:
- LinkedBlockingDeque使用单锁,getSize()时加锁并返回count,count为普通int型,通过锁保证数据正确性
- LinkedBlockingQueue使用双锁,getSize()时直接返回count,count为AtomicInteger类型,通过自动保证数据正确性
九、 ConcurrentLinkedQueue
1. 类型
Collection - Queue - Deque
2. 特点
基于双向链表的无界线程安全队列,按照 FIFO(先进先出)原则对元素进行排序。队列元素中不可以放置null元素(内部实现的特殊节点除外)。
3. 数据结构
双向链表
4. 重要实现
a. 线程安全
利用底层的插入、删除的CAS原子性操作,通过死循环不断获取最新的结点指针来保证不会出现竞态条件。
b. 并发优化
入队列
从源代码角度来看整个入队过程主要做二件事情。第一是定位出尾节点,第二是使用CAS算法能将入队节点设置成尾节点的next节点,如不成功则重试。
hops的设计意图。使用hops变量来控制并减少tail节点的更新频率,并不是每次节点入队后都将 tail节点更新成尾节点,而是当 tail节点和尾节点的距离大于等于常量HOPS的值(默认等于1)时才更新tail节点,tail和尾节点的距离越长使用CAS更新tail节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对volatile变量的读操作来减少了对volatile变量的写操作,而对volatile变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
出队列
并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,出队操作才会更新head节点。这种做法也是通过hops变量来减少使用CAS更新head节点的消耗,从而提高出队效率。
首先获取头节点的元素,然后判断头节点元素是否为空,如果为空,表示另外一个线程已经进行了一次出队操作将该节点的元素取走,如果不为空,则使用CAS的方式将头节点的引用设置成null,如果CAS成功,则直接返回头节点的元素,如果不成功,表示另外一个线程已经进行了一次出队操作更新了head节点,导致元素发生了变化,需要重新获取头节点。