- Hashmap多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
参考 HashMap多线程下死循环分析 - HashTable 使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
参考 HashMap分析
1.预备知识
1.1 Hash
散列,哈希:把任意长度的输入通过一种算法(散列),变换成为固定长度的输出,这个输出值就是散列值。属于压缩映射,容易产生哈希冲突。Hash算法有直接取余法等。
产生哈希冲突时解决办法:开放寻址;2、再散列;3、链地址法(相同hash值的元素用链表串起来)。
ConcurrentHashMap在发生hash冲突时采用了链地址法。
md4,md5,sha-hash算法也属于hash算法,又称摘要算法。
1.2 位运算——Modifier.java中修饰符是使用位来表示的
参考hash码的二进制显示
Java实际保存int型时 正数 第31位 =0 负数:第31位=1
常用位运算有:
位与 & (1&1=1 1&0=0 0&0=0)
位或 | (1|1=1 1|0=1 0|0=0)
位非 ~ ( ~1=0 ~0=1)
位异或 ^ (1^1=0 1^0=1 0^0=0)
<<有符号左移 >>有符号的右移 >>>无符号右移 例如:8 << 2 = 32 8>>2 = 2
取模的操作 a % (Math.pow(2,n)) 等价于 a&( Math.pow(2,n)-1)
位运算适用:权限控制,对象的属性非常多时的保存
2.JDK1.7 ConcurrentHashMap
2.1 JDK1.7数据结构

ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment实际继承自可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,每个Segment里包含一个HashEntry数组,我们称之为table,每个HashEntry是一个链表结构的元素。
问题: ConcurrentHashMap实现原理是怎么样的或者问ConcurrentHashMap如何在保证高并发下线程安全的同时实现了性能提升?
答:ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,只要多个修改操作发生在不同的段上,它们就可以并发进行。
2.2 JDK1.7 主要方法
2.2.1 初始化
- initialCapacity:初始容量大小 ,默认16,这个容量是指所有segment连接的HashEntry[cap]加起来的总容量
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 2;
while (cap < c)
cap <<= 1;
- loadFactor, 扩容因子,默认0.75。
- concurrencyLevel 并发度,默认16。并发度可以理解为程序运行时能够同时更新ConccurentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
- ssize才是Segment[]数组的长度,只不过ssize是根据concurrencyLevel计算的后面table的大小
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
Segment[] ss = (Segment[])new Segment[ssize];
- segmentShift/segmentMask
用于定位元素所在segment。segmentShift表示偏移位数,通过前面的int类型的位的描述我们可以得知,int类型的数字在变大的过程中,低位总是比高位先填满的,为保证元素在segment级别分布的尽量均匀,计算元素所在segment时,总是取hash值的高位进行计算。
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment s0 =
new Segment(loadFactor, (int)(cap * loadFactor),
(HashEntry[])new HashEntry[cap]);
Segment[] ss = (Segment[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
2.2.2 元素索引定位
对于某个元素而言,一定是放在某个segment元素的某个table元素中的,所以在定位上:
- 定位segment:取得key的hashcode值进行一次再散列(通过Wang/Jenkins算法),拿到再散列值后,以再散列值的高位进行取模得到当前元素在哪个segment上。


-
定位table:同样是取得key的再散列值以后,用再散列值的全部和table的长度进行取模,得到当前元素在table的哪个元素上。

2.2.3 get()方法
public V get(Object key) {
Segment s; // manually integrate access methods to reduce overhead
HashEntry[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
定位segment和定位table后,依次扫描这个table元素下的的链表,要么找到元素,要么返回null。
-
在高并发下的情况下如何保证取得的元素是最新的?
答:用于存储键值对数据的HashEntry,在设计上它的成员变量value等都是volatile类型的,这样就保证别的线程对value值的修改,get方法可以马上看到。

2.2.4 put方法和putIfAbsent方法
public V putIfAbsent(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, true);
}
public V put(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
private Segment ensureSegment(int k) {
final Segment[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment seg;
if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry[] tab = (HashEntry[])new HashEntry[cap];
if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment s = new Segment(lf, threshold, tab);
while ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
1、首先定位segment,当这个segment在map初始化后,还为null,由ensureSegment方法负责填充这个segment。
2、 对Segment 加锁

3、定位所在的table元素,并扫描table下的链表,找到时:
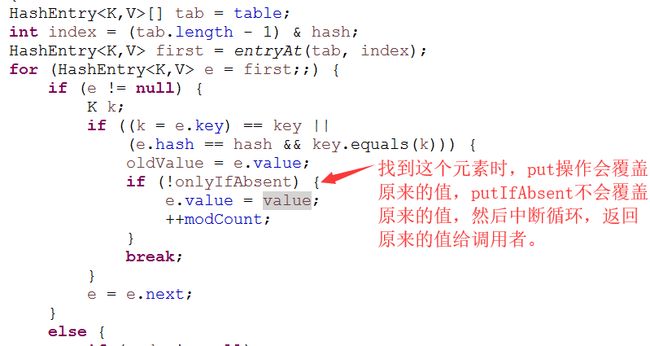
没有找到时:

2.2.5 扩容操作rehash
Segment 不扩容,扩容下面的table数组,每次都是将数组翻倍。
private void rehash(HashEntry node) {
/*
* Reclassify nodes in each list to new table. Because we
* are using power-of-two expansion, the elements from
* each bin must either stay at same index, or move with a
* power of two offset. We eliminate unnecessary node
* creation by catching cases where old nodes can be
* reused because their next fields won't change.
* Statistically, at the default threshold, only about
* one-sixth of them need cloning when a table
* doubles. The nodes they replace will be garbage
* collectable as soon as they are no longer referenced by
* any reader thread that may be in the midst of
* concurrently traversing table. Entry accesses use plain
* array indexing because they are followed by volatile
* table write.
*/
HashEntry[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry[] newTable =
(HashEntry[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry e = oldTable[i];
if (e != null) {
HashEntry next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry lastRun = e;
int lastIdx = idx;
for (HashEntry last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry n = newTable[k];
newTable[k] = new HashEntry(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
2.2.6 size()
size的时候进行两次不加锁的统计,两次一致直接返回结果,不一致,重新加锁再次统计。
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
2.2.7 弱一致性
get方法和containsKey方法都是通过对链表遍历判断是否存在key相同的节点以及获得该节点的value。但由于遍历过程中其他线程可能对链表结构做了调整,因此get和containsKey返回的可能是过时的数据,这一点是ConcurrentHashMap在弱一致性上的体现。
3.JDK1.8以后 ConcurrentHashMap
- 与1.7相比的重大变化
1、 取消了segment数组,直接用table保存数据,锁的粒度更小,减少并发冲突的概率。
2、 存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为O(logn),性能提升很大。什么时候链表转红黑树?当key值相等的元素形成的链表中元素个数超过8个的时候。
3.1 JDK1.8 数据结构

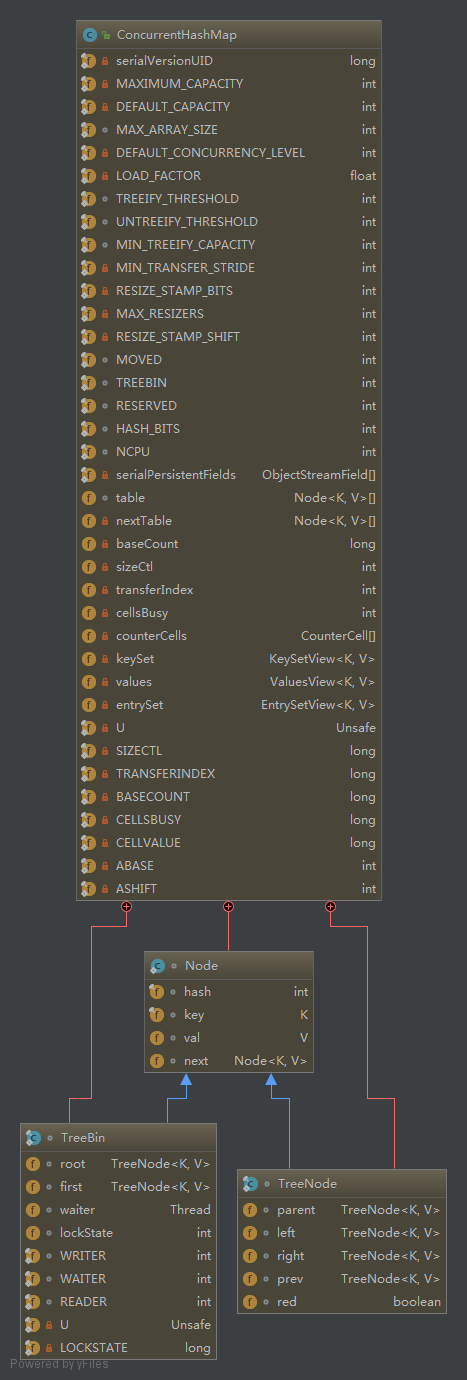
- Node类存放实际的key和value值。
- sizeCtl:
负数:表示进行初始化或者扩容,-1表示正在初始化,-N,表示有N-1个线程正在进行扩容
正数:0 表示还没有被初始化,>0的数,初始化或者是下一次进行扩容的阈值 - TreeNode 用在红黑树,表示树的节点, TreeBin是实际放在table数组中的,代表了这个红黑树的根。
3.2 JDK1.8 主要方法
3.2.1 初始化
只是给成员变量赋值,put时进行实际数组的填充。
3.2.2 元素索引定位
根HashMap是一样的。

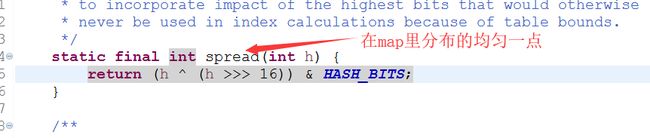
step1. h = key.hashCode()获取key的hash值
step2. (h = key.hashCode()) ^ (h >>> 16)将h的高位与h的地位异或,即高位参与运算
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。step3. i = (n - 1) & hash,即hash与table.length - 1相与。
HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。也是为什么长度是2的n次方。
a % (Math.pow(2,n)) 等价于 a&( Math.pow(2,n)-1)
3.2.3 get()方法
这里关键在eh < 0的理解:
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final class ForwardingNode extends Node {
final Node[] nextTable;
ForwardingNode(Node[] tab) {
super(MOVED, null, null);
this.nextTable = tab;
}
TreeBin(TreeNode b) {
super(TREEBIN, null, null);
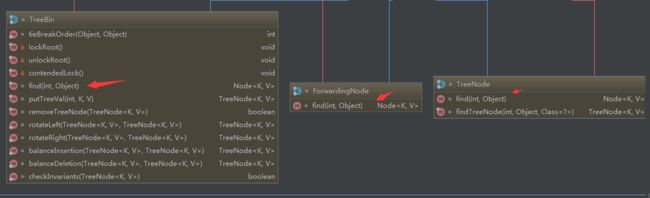
这两种类型的特殊结点TreeBin和ForwardingNode均有find函数,多以这里find可以在并发扩容或者是树结点时进行查询。
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
3.2.4 put方法和putIfAbsent方法
public V put(K key, V value) {
return putVal(key, value, false);
}
public V putIfAbsent(K key, V value) {
return putVal(key, value, true);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
Node f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
-
真正初始化
在这也可以看出ConcurrentHashMap的初始化只能由一个线程完成。如果获得了初始化权限,就用CAS方法将sizeCtl置为-1,防止其他线程进入。
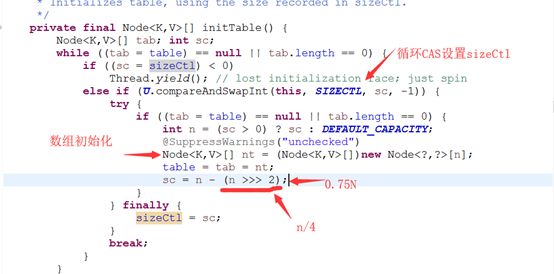
1)U.compareAndSetInt(this, SIZECTL, sc, -1) 将sizeCtl设置为-1,标识为初始化
2)初始化完成后,sizeCtl变为了 扩容的阈值:sizeCtl = 0.75n 扩容
如果插入位置的结点头正在扩容,则帮助完成扩容,完成扩容后再次进入循环,然后插入指定的位置。
而且并发扩容可以与put/get并发进行,因为这里所有分支都能确保并发安全!
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
- 加锁处理之前,需要判断i索引定位的第一个元素 是否还是 f,如果不是,需要重新循环获取到新值,因为这个外面并没有加锁。
synchronized (f) {
if (tabAt(tab, i) == f) {
- 链表的插入
if (fh >= 0) {
- 红黑树的插入
else if (f instanceof TreeBin)
- 链表插入是,如果结点超过了8,则转为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
- addCount(1L, binCount),检查是否需要扩容
3.2.5 扩容操作
并发扩容操作的行为请参考:Intellij IDEA多线程调试——ConcurrentHashMap并发扩容
1)检查是否需要扩容 addCount(1L, binCount)
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSetLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSetLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSetInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
private final void transfer(Node[] tab, Node[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode fwd = new ForwardingNode(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSetInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSetInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node lastRun = f;
for (Node p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node(ph, pk, pv, ln);
else
hn = new Node(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin t = (TreeBin)f;
TreeNode lo = null, loTail = null;
TreeNode hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode p = new TreeNode
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
2)如果还在进行扩容操作就先进行扩容helpTransfer(tab, f)
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
final Node[] helpTransfer(Node[] tab, Node f) {
Node[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
- MOVED在哪里赋值?
/**
* A node inserted at head of bins during transfer operations.
*/
static final class ForwardingNode extends Node {
final Node[] nextTable;
ForwardingNode(Node[] tab) {
super(MOVED, null, null);
this.nextTable = tab;
}
3.2.6 size()
估计的大概数量,不是精确数量
3.2.7 弱一致性
弱一致
参考
- 1)享学课堂Mark老师笔记
- 2)【JAVA秒会技术之ConcurrentHashMap】JDK1.7与JDK1.8源码区别
- 3)谈谈ConcurrentHashMap1.7和1.8的不同实现![TIM截图20180825054450.png]