公司的老项目要改造多租户,于是进入了大坑,本文写点遇到的坑以及解决方案,每次遇到问题在网上搜了好久,记录下来,防止以后忘掉。
(一).方案
网上有很多方案,本文只写最后一种,即:表增加租户id,实现数据隔离
方案一:增加租户id,在每一个mapper调用的地方,都手工加上租户id
例如:
LambdaQueryWrapperlambdaQueryWrapper = new LambdaQueryWrapper<>(); lambdaQueryWrapper.eq(Entity::getTenantId,"tenantId"); entityMapper.selectList(lambdaQueryWrapper);
这种方式复杂,工作量大,且容易漏。没有采用
方案二:使用mp官方的多租户插件,此处代码省略,自行去官方文档上查询
(二).官方多租户的方案的优化和坑
采用了官方文档的多租户插件后,前期调试很顺利,crud 都自测过了,以为没有问题了,于是就发测试环境了,但是随着测试的深入,发现了好多问题和需要改动的地方,此处列举:
1.分析哪些需要加多租户,哪些不需要加
(1)租户id的重写
官方的默认重写方法是:
@Override
public Expression getTenantId() {
return null;
}
此处需要定义你的租户id的获取方法
(2)租户字段的定义
private static final String TENANT_ID = "tenant_id";
@Override
public String getTenantIdColumn() {
return TENANT_ID;
}
(3)租户拦截
@Override
public boolean ignoreTable(String tableName) {
return TenantLineHandler.super.ignoreTable(tableName);
}
此处我采用的方案是 表名拦截,代码如下:
@Override
public boolean ignoreTable(String tableName) {
/**
* 此处的list,临时用作拦截
* 原因是:下面的表解析方法,用的是大驼峰转下划线,再跟sql拦截器拦截到的表名对比,如果匹配到了,则认为该表需要多租户拼接
* 但是有的表没有严格的按照大驼峰转下划线,所以这些表需要额外定义
* @TableName 这个注解能否完成该职责,目前还未测试,以后再说。
*/
List list = new ArrayList<>();
list.add("das_standard_operation");
list.add("t_expert");
list.add("t_nominate_dict");
list.add("t_nominate_dict_history");
list.add("t_order");
list.add("t_standard_sort");
list.add("t_task");
list.add("t_task_confirm");
list.add("das_view");
if (list.contains(tableName)) {
return false;
}
EntityTableCache instance = EntityTableCache.getInstance();
if (null == instance || null == instance.getCacheData(tableName)) {
//如果未初始化到,不拼接租户id
return true;
}
String entityPath = EntityTableCache.getInstance().getCacheData(tableName).toString();
//该方法会将大驼峰转为下划线,并完成初始化
return !EntityUtils.isHaveAttr(entityPath, COLUMN_TENANTID);
}
EntityUtils 方法代码如下 (github上的一位小伙子写的,侵权联系我删)
/**
* 判断实体是否有某个属性
*
* @param entityPath 实体全路径
* @param attrName 属性名字
* @return boolean
*/
public static boolean isHaveAttr(String entityPath, String attrName) {
Optional epOptional = Optional.ofNullable(entityPath);
if (!epOptional.isPresent()) {
return false;
}
try {
Class aClass = Thread.currentThread().getContextClassLoader().loadClass(epOptional.get());
Field[] fields = aClass.getDeclaredFields();
for (Field field : fields) {
if (attrName.equals(field.getName())) {
return true;
}
}
return false;
} catch (ClassNotFoundException e) {
// log.error("SystemSqlParser->isHaveAttr类加载异常:" + e.getMessage());
return false;
}
}
2.jsqlparser 这个包与pagehelper 版本不对
在自测的时候,发现update语句拦不住,结果发现jsqlparser的版本号是1.2 而1.2与2.0(mp3.4.1 的jspparser版本是2.0),通过debug发现,进到了1.2的update方法
如图:
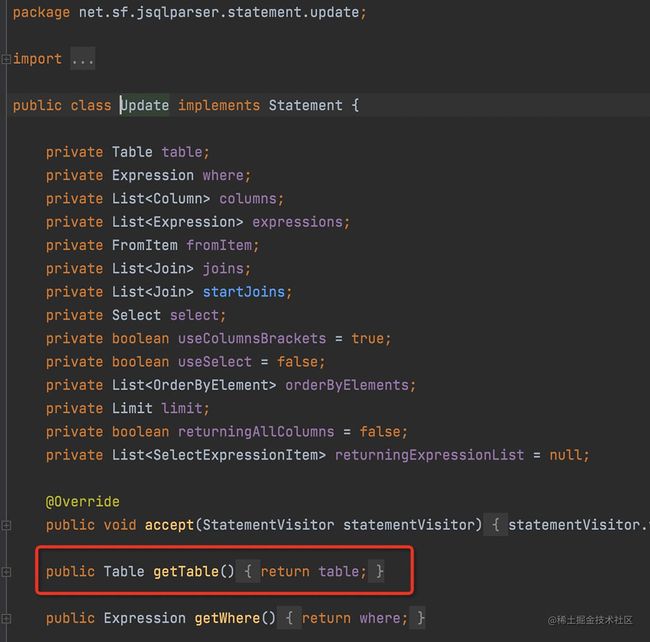
1.2版本是getTables(),而2.0是如图的getTable()
解决方法:
父pom强制规定版本
com.github.jsqlparser
jsqlparser
2.0
com.github.pagehelper
pagehelper
5.1.10
3.sql解析失败
1.regexp
目前发现使用到了regexp > 0 的sql 语句,解析器会报错
2.replace into 语句
这个语句目前我发现也是不支持的
上述的两个问题到现在还没有解决,翻阅了一些资料,问了一些同事,对这块接触的都比较少,目前mp最新版本使用的3.4.3.4中使用的com.github.jsqlparser:jsqlparser 是4.2版本,目前对上述的两条仍然不支持(如果有哪位大神解决了,麻烦评论指导一下!)
解决方法
既然你失败,那我就不用你好了,手动拼接,见下面忽略方法⬇️
4.忽略多租户不生效
我们都知道通过注解:@InterceptorIgnore(tenantLine = "on") 可以达到该mapper语句不进行sql解析,和不进行多租户的改造。但是在实际应用场景中发现有一个特殊的场景该注解不生效。
例如:
Pagepage = PageHelper.startPage(param.getPageNumber(), param.getPageSize()); List experts = expertMapper.queryExpertList(page);
这个问题真的是浪费了我好久的时间,后来通过查阅资料,我发现@InterceptorIgnore在有分页的时候,是会失效的,但是我又想,都是mp的东西,你自己都冲突,那怎么能行。
然后我就发现PageHelper 这个东西,看着很奇怪。然后我就给去掉了,不进行分页,果然可以了!注解生效了。完美,同时,mp都已经提供了分页的东西,为什么还要借助com.github的呢。
然后改造如下:
IPagepage = new com.baomidou.mybatisplus.extension.plugins.pagination.Page<>(param.getPageNumber(),param.getPageSize()) List experts = expertMapper.queryExpertList(expertMapping.dtoToEntity(param));
总结
到此这篇关于Mybatis plus多租户方案实战踩坑的文章就介绍到这了,更多相关Mybatis plus多租户方案内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!