总结下常用的几个集群,大概会涉及SolrCloud、Redis、FastDFS、Dubbo、消息中间件(ActiveMq,RocketMq)。
——吹雪
SolrCloud部分
SolrCloud环境:zookeeper-3.4.10,solr-7.0.1-2
SolrCloud架构图为下图左侧,右侧为Solr的Master-Slave。

SolrCoud原理:
1、基于zk的分布式集群协调功能来监视整个集群中各节点的状态,当节点出现问题时,通知其他节点,再利用zk的临时节点特性来注册watcher选举出leader节点;基于zk的各节点数据的一致性来保证solr配置文件在整个集群中的数据一致性和高可用,注册对配置文件节点的watcher,可以感知配置文件发生变化与否,可以达到启用最新配置的目的。
2、索引分片,由于索引可能会很大,所以采取分而存之,将索引分成多个shard,每一个shard还可以有自己的备份。(副本:中文对于副本的解释,一个复制物,我的理解是不包括本体,比如说副本有1个,那共有几个,就是副本+本体=2个,但是好多从英文翻译过来的资料,在统计副本个数时,都会包括本体,比如说副本是2,已经包含了本体,所以在语言文化上会导致一些不统一)
搭建SolrCloud需要的机器数:
SolrCloud集群实际包括zookeeper和solr两个集群。
对于zookeeper集群,根据奇数原则和过半原则,2*n+1,n取最小值:2*1+1=3,所以最少就是3个机子。
对于SolrCloud,由于是分片机制+备份机制,如有1个分片,那至少需要1个备份,就是2台,这做到了高可用,但对于索引的大小变化,如索引越来越大一台机子装不下时,需要水平扩展。如有2个分片,每个分片至少一个备份,就是需要4台机子。所以solr的数目在不分片时,至少是2台。如果分片,至少是4台。网上好多搭建环境时用3台,这如何分片?分2片,那其中1片就没有备份,分1片,只多出了一个副本,用处不大。到这里,你可能会不同意,你会想到zookeeper的集群3台就可以。这是由于zookeeper的选举leader算法是zab协议,过半原则,而solr的leader选择是利用了zookeeper的临时节点特性,简单理解就是:solr主节点挂掉时,剩余从节点(也就是副本节点)会感知到这个事件,然后去创建zk的临时节点,谁先创建成功谁就成为主节点。
综上所述,我的理解,如果不分片,至少需要3台zk+2台solr=5台(做到了高可用)。如果分片,至少需要3台zk+4台solr=7台(做到了分布式和高可用)。
网上有不少文章,比如下图中的搭建方式,在搭建SolrCloud时,用了3台机子,分了2个片,3个副本,两个片都是同一台机子上,这样做意义何在?既然都在同一台机子,那分片干什么,分布式集集群,难道不是分而治之,分而存之?可以为一个分片规划N(最好大于1)个副本,但不同的分片最好是存不同的机子。这是我的理解。
安装:
非源码包,解压即可。
提示: (如果是源码包安装,即安装包名称中有src的,解压只是第一步,在linux下,安装之前需要yum instal环境,然后.configure 检查编译环境,make对源代码进行编译,make insall 将生成的可执行文件安装到当前计算机中,最后修改配置文件。redis、fastDFS、dubbo、nginx、keepalived、activeMq、RocketMq安装都大同小异,基本上都这几个步骤。)
我的solr是安装在windows 7 64位机子上:

4个内容完全一致的solr,每一个启动后都是一个solr实例,
端口号规划:8986,8987,8988,8989
配置略过…
需要注意的是,在liux的.sh脚本和windows的.cmd脚本中,设置变量的区别:
.sh是
SOLR_JAVA_HOME="C:\Java\jdk1.8.0_60"
ZK_HOST="127.0.0.1:2181/solr"
SOLR_HOST="127.0.0.1"
SOLR_TIMEZONE="UTC+8"
而.cmd是
set SOLR_JAVA_HOME="C:\Java\jdk1.8.0_60"
set ZK_HOST="127.0.0.1:2181/solr"
set SOLR_HOST="127.0.0.1"
set SOLR_TIMEZONE="UTC+8"
启动zk
……
上传配置文件至zk:
以下是常用的4个命令:
solrstart -cloud -p 8989 //启动
solr stop-cloud -p 8989 //停止
solr zkupconfig -z 127.0.0.1:2181/solr -n store_config -d D:\solrhome\solr1\store_solr_config //往zk上传配置文件
solr zk rm -z 127.0.0.1:2181 -r /solr/configs/store_config //删zk上的节点
上传成功后,如下图:
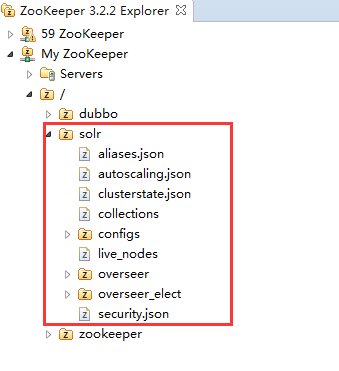
Solr节点对应整个集群在zk上的根节点(是solrCloud的根,不是zk的根)。
从zk的zNode可以看出,solrCloud的大致设计思路,比如clusterstat.json存集群的状态信息,collections目前是个叶子节点,其下什么都没有,configs存放配置文件,live_nodes节点下是集群中活动的机子,由于我们还没启动solr,所以目前该节点还是个叶子节点,启动solr后,每一个solr实例都会在该节点下建立一个子节点。除此之外集群中还有一个重要的角色——监控者,在集群中任何机子都有资格精选监控者,监控者信息在overseer_elect,监控者用来监控整个集群的状态,overseer下是监控者用来工作时的一些资源,比如队列。
而SolrCloud正是利用了zk的特性从而做到了分布式协调:集群有多少机子,每个机子的状况,机子之间的互相通信,主从节点的切换。
启动SolrCloud

启动成功后,solr告诉我们,Happysearching!开始快乐的搜索旅程吧!
启动失败后,在solr的日志文件中可以找到详细出错信息,进行调试。
再查看zk节点的变化:

在live_nodes下有4个节点。在electon节点下也有4个节点,还有一个leader节点,leader节点的内容:

这说明,监控者是8986端口的节点。在启动solrCloud时,我就是最先启动的8986节点,启动后,8986端口的solr实例会先在/solr/overseer_celc/election节点下创建一个临时节点顺序节点,然后向/solr/overseer_celct/leader节点写入内容,其他的节点启动后,也同样会在/solr/overseer_celc/election节点下创建一个临时节点顺序节点,然后会发现/solr/overseer_celct/leader节点已经有了信息,而且查看信息内容,8986已经注册成为监控者。
(这里值的思考的是,对于监控者节点的选择,为什么不是在/solr/overseer_celct/leader下建立一个子节点,而是采用了在leader节点中写入内容?根据zk的特性,多个客户端向zk请求创建节点时,只会有一个创建成功,谁创建成功,谁就会有特殊的地位(在solrClound中便是监控者),但solr为什么不这样做?根据上图中/solr/overseer_celct/leader节点的内容{"id":"99492852084441148-127.0.0.1:8986_solr-n_0000000015"},注意最后的数字0000000015,再查看election节点的子节点,发现0000000015是最小的编号,而拥有这个编号的8986节点在election节点下是存在的,所以承认8986的地位,这是利用了zk的顺序节点的特性。对于solrCloud而言,谁编号最小谁就是监控者,而8986最先到达,创建顺序节点时的编号最小,因此成为了监控者。由此也可见,solr的监控者选举是通过election节点和leader两个节点共同控制来完成的。这也给我们提供了一种选举的思路,加上之前的提到过的临时节点创建方式,以后有业务需要时也可以借鉴这两种选举做法。)
创建collection
我们有四个solr服务,访问任意一个都可以,这正是集群的好处,负载均衡+高可用,性能也很好。

创建一个collection,shard分片我2,就是我们把这个索引分成两份,放到两台机子上,进行分布式存储,然后再为每一个shard加一个备份,加上本体,副本数一共是2。
导入索引
在solr监控台,导入即可
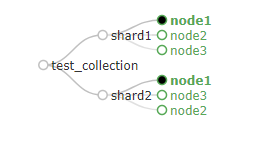
查看cloud图

8987和8988为shard1下的主从,8987为leader节点。
8986和8989位shard2下的主从,8986位leader节点。
根据上边启动solr时的顺序,8986-8987-8988-8989,可见8986和8987先启动的两台率先分别注册成为了两个主节点。即使8988和8988都down掉,这个集群还是可以工作的,只是没有了备份。为了验证,我们先关掉
8989节点。
此时cloud图如下:

可以看到shard2只剩下了8986主节点。
查询一下数据:
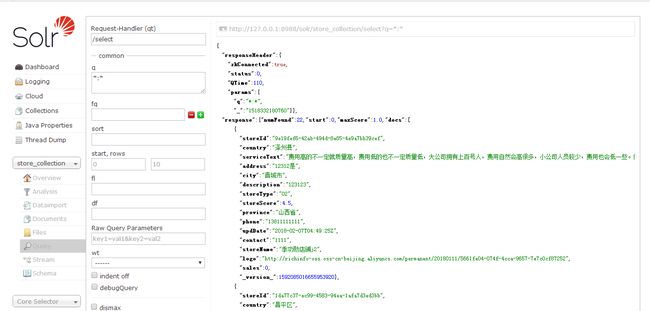
集群可以工作。
再关掉8989后,cloud图如下:

观察zk
把关掉的8989和8988节点启动,查看zk节点状态

可以看出,shard下主节点也是利用zk的临时顺序节点特性来选举出来的。
做个搜索的小测试
两条数据,第一条数据的店铺名称storeName为权重,第二条数据的擅长领域goodArea为权重,在搜索时,我们输入关键词是权重,q为[storeName:权重OR goodArea:权重]返回的字段中加入score(相关度得分)。可以发现是storeName为权重的数据排在了第一行,这条数据的相关度得分为2.25大于第二条数据的1.89。

现在,如何做才能让第二条数据,就是goodAre为权重的数据排在前边?
根据solr语法的,“^”可以用来提升相关度得分。将q改为[storeName:权重OR goodArea:权重^2],查询结果如下:

可以看到goodArea为权重的数据排在了前边,它的相关度得分变为了3.78,是之前得分1.89的2倍。
SolrCloud部分完。