1.SSD-Tensorflow-master仓库创建:
从GitHub下载资源;SSD-tensorflow——github下载地址:SSD-Tensorflow
2.环境检查测试:
到“checkpoints”文件夹下解压“ssd_300_vgg.ckpt.zip”到“checkpoints”文件夹下.运行“./notebooks/ssd_notebook”,看看能否进行检测,正常检测;
./checkpoints
unzip ssd_300_vgg.ckpt.zip
jupyter notebook notebooks/ssd_notebook.ipynb
3.Datasets--数据生成:
运行“./tf_convert_data.py”,在“/tfrecords”文件夹下生成数据文件(数据用VOC2007);
方法一:
DATASET_DIR=./VOC2007/test/
OUTPUT_DIR=./tfrecords
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=voc_2007_train \
--output_dir=${OUTPUT_DIR}
方法二:
Windows环境,在cmd中,进入当前仓库路径,运行:
python tf_convert_data.py --dataset_name=pascalvoc --dataset_dir=./VOC2007/ --output_name=voc_2007_train --output_dir=./tfrecords
方法三:
可直接修改“tf_convert_data.py”中的设置,如:
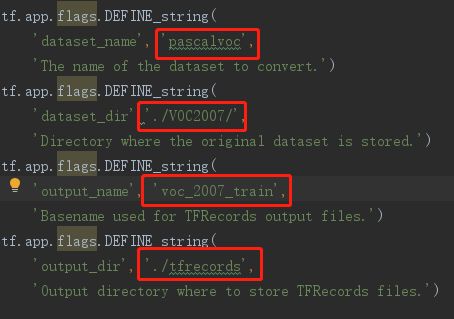
注:
1.关于报错:tensorflow.python.framework.errors_impl.NotFoundError: Failed to create a NewWriteableFile:
问题来源:创建文件失败
处理方法:提前手动创建文件“tfrecords”
2.关于报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
问题来源:读取编码错误,需二进制
处理方法:“./datasets/pascalvoc_to_tfrecords.py”中第83行,“image_data = tf.gfile.FastGFile(filename, 'r').read()”修改为“image_data = tf.gfile.FastGFile(filename, 'rb').read()”
4.Training--使用VOC2007数据进行训练模型
运行“/train_ssd_network.py”进行训练;
运行参数:
DATASET_DIR=./tfrecords
TRAIN_DIR=./logs/
CHECKPOINT_PATH=./checkpoints/ssd_300_vgg.ckpt
python train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=32
注:可直接在“train_ssd_network.py”脚本中修改对应的“tf.app.flags”对应定义参数。
关于报错:
1.Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
处理方法:修改运行参数为--gpu_memory_fraction=0.33