本文以CentoS 7 系统环境为基础,从创建用户开始,使用Zookeeper作为协调集群基础,详细介绍了从环境配置到Hadoop安装的详细过程。
一、系统环境配置
1.增加用户和用户组
新增一个hadoop用户和Hadoop用户组,并为hadoop用户设置密码
[root@localhost local]# groupadd hadoop #添加Hadoop用户组
添加hadoop用户
[root@localhost local]# useradd hadoop # 添加hadoop用户
指定hadoop用户在hadoop用户组
[root@localhost local]# usermod -g hadoop hadoop
设定hadoop用户密码
[root@localhost local]# passwd hadoop
查看已添加的用户组
[root@localhost local]# groups hadoop
hadoop : hadoop
授权hadoop用农户root系统权限,编辑/etc/sudoers 文件,增加授权信息
[root@localhost local]# vim /etc/sudoers
在root相关信息下,追加内容,如
root All=(ALL) ALL
hadoop ALL=(ALL) ALL
hadoop 用户需要使用root系统权限,命令之前追加sudo即可
修改主机名信息
[root@localhost hadoop]# vim /etc/hosts
增加一下hostname 信息
192.168.159.20 hadoop01
192.168.159.21 hadoop02
192.168.159.22 hadoop03
192.168.159.23 hadoop04
192.168.159.24 hadoop05
此IP主机信息应该根据具体的虚拟机集群规划灵活填写
二、基础环境的安装
1.安装gcc-c 编译工具
[root@localhost local]# yum install -y gcc
2.安装lrzsz文件传输工具
[root@localhost local]# yum install -y lrzsz
3.手动安装JDK
查找已经存在的JDK版本
[root@localhost local]# rpm -qa|grep java
卸载开源openJDK
[root@localhost local]# yum remove -y java-1.*
上传JDK tar包,解压安装包
[root@localhost java]# tar -zxvf jdk-8u144-linux-x64.tar.gz
创建软连接
[root@localhost java]# ln -s /home/hadoop/apps/java/jdk1.8.0_144/ /usr/local/java
配置环境变量
vim /etc/profile
文件末尾增加如下内容
export JAVA_HOME=/usr/local/java
export PATH=${JAVA_HOME}/bin:$PATH
重新加载环境变量
[root@localhost java]# source /etc/profile
4.安装telnet
[root@localhost java]# yum install xinetd telnet telent-server -y
三、Zookeeper集群安装
1.下载Zookeeper集群安装包
下载地址:Zookeeper-3.4.10
2.Zookeeper 集群规划
| 主机名称 | IP | 部署软件 |
|---|---|---|
| hadoop01 | 192.168.159.20 | zookeeper |
| hadoop02 | 192.168.159.21 | zookeeper |
| hadoop03 | 192.168.159.22 | zookeeper |
一共部署三台机器,每台机器启动一个zookeeper进程
3.上传Zookeeper并解压安装
解压安装包
[hadoop@hadoop01 zookeeper]$ tar -zxvf zookeeper-3.4.10.tar.gz
退出hadoop用户,切换到root用户,创建Zookeeper软连接
[root@hadoop01 zookeeper-3.4.10]# ln -s /home/hadoop/apps/zookeeper/zookeeper-3.4.10 /usr/local/zookeeper
4.配置Zookeeper环境变量
使用Root用户修改 /etc/profile文件,添加如下内容:
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin
生效环境变量
[root@hadoop01 zookeeper-3.4.10]# source /etc/profile
修改zookeeper软链接属主为hadoop
[root@hadoop01 zookeeper-3.4.10]# chown -R hadoop:hadoop /usr/local/zookeeper
切换到hadoop用户,修改zookeeper配置文件,目录位置: /usr/local/zookeeper/conf
[root@hadoop01 zookeeper-3.4.10]# exit
exit
[hadoop@hadoop01 zookeeper]$ cd /usr/local/zookeeper/conf/
[hadoop@hadoop01 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@hadoop01 conf]$ cp zoo_sample.cfg zoo.cfg
编辑zoo.cfg文件内容,添加内容如下:
dataDir=/usr/local/zookeeper/data #快照文件存储目录
dataLogDir=/usr/local/zookeeper/log #事务日志文件目录
#注意hadoop01、hadoop02、hadoop03是安装zookeeper的主机名,根据自己的虚拟机自行修改
server.1=hadoop01:2888:3888 # (主机名, 心跳端口、数据端口)
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
==TIPS: 请删除配置的注释内容, 确保zookeeper启动配置文件正确==
根据配置信息,创建2个对应目录的文件夹,只有hadoop用户具有写权限
[hadoop@hadoop01 zookeeper]$ mkdir -m 755 data
[hadoop@hadoop01 zookeeper]$ mkdir -m 755 log
在data文件夹下新建myid文件,myid的文件内容为该节点的编号
[hadoop@hadoop01 zookeeper]$ cd data/
[hadoop@hadoop01 data]$ ls
[hadoop@hadoop01 data]$ touch myid
[hadoop@hadoop01 data]$ echo 1 > myid
5.分发安装包到各zookeeper节点上
通过scp将安装包拷贝到其他两个节点hadoop02和hadoop03的/home/hadoop/apps/zookeeper目录下,提前在hadoop02和hadoop03创建好/home/hadoop/apps/zookeeper目录
[hadoop@hadoop01 zookeeper]$ scp -r /home/hadoop/apps/zookeeper/zookeeper-3.4.10 hadoop@hadoop02:/home/hadoop/apps/zookeeper
[hadoop@hadoop01 zookeeper]$ scp -r /home/hadoop/apps/zookeeper/zookeeper-3.4.10 hadoop@hadoop03:/home/hadoop/apps/zookeeper
修改data目录下的myid文件,hadoop02的myid内容为2,hadoop03的myid内容为3。
使用Root用户,按zookeepr安装方式,创建软连接,修改文件夹属主、配置环境变量。
6.创建脚本,使zookeeper集群一键启动。
创建启动脚本zkStart-all.sh内容如下:
#!/bin/bash
echo "start zkserver..."
for i in 1 2 3
do
ssh hadoop0$i "source /etc/profile;/usr/local/zookeeper/bin/zkServer.sh start"
done
echo "zkServer started!"
创建关闭一键关闭脚本zkStop-all.sh内容如下:
#!/bin/bash
echo "stop zkserver..."
for i in 1 2 3
do
ssh hadoop0$i "source /etc/profile;/usr/local/zookeeper/bin/zkServer.sh stop"
done
echo "zkServer stoped!"
7.配置免密钥SSH登录
使用Hadoop用户,在hadoop01节点创建SSH密钥信息,步骤如下:
[hadoop@hadoop01 local]$ ssh-keygen -t rsa
一路回车即完成了密钥信息的创建,拷贝密钥信息到hadoop01,hadoop02,hadoop03上:
[hadoop@hadoop01 local]$ ssh-copy-id -i hadoop01
[hadoop@hadoop01 local]$ ssh-copy-id -i hadoop02
[hadoop@hadoop01 local]$ ssh-copy-id -i hadoop03
将密钥拷贝完成后,验证从hadoop01 登录到hadoop02 没问题免密登录即可:
[hadoop@hadoop01 bin]$ ssh hadoop02
8.启动Zookeeper集群
将zkStart-all.sh脚本和ZkStop-all.sh脚本放置到Hadoop01节点的zookeer安装目录,如:
/usr/local/zookeeper/bin
修改脚本的可执行权限,使脚本可执行
[hadoop@hadoop01 bin]$ chmod -R +x zkStart-all.sh
[hadoop@hadoop01 bin]$ chmod -R +x zkStopt-all.sh
在zookeeper bin目录下启动Zookeeper集群
[hadoop@hadoop01 bin]$ ./zkStart-all.sh
查看启动结果,如各节点出现QuorumPeerMain进程,则说明集群启动成功。
[hadoop@hadoop01 bin]$ jps
7424 Jps
7404 QuorumPeerMain
四、Hadoop集群安装
下面表格为Hadoop集群规划示意图:
| 主机名 | IP | 安装软件 | 运行进程 |
|---|---|---|---|
| hadoop01 | 192.168.159.20 | JDK、Hadoop、zookeeper | NameNode(Active) DFSZKFailoverController(zkfc) 、ResourceManager(Standby)、QuorumPeerMain(zookeeper)、 |
| hadoop02 | 192.168.159.21 | JDK、Hadoop、Zookeeper | NameNode(Standby)、DFSZKFailoverController(zkfc)、ResourceManager(Active)、QuorumPeerMain(zookeeper)、Jobhistory |
| hadoop03 | 192.168.159.22 | JDK、Hadoop、Zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain(zookeeper) |
| hadoop04 | 192.168.159.23 | JDK、Hadoop | DataNode、NodeManager、JournalNode |
| hadoop05 | 192.168.159.24 | JDK、Hadoop | DataNode、NodeManager、JournalNode |
1.安装hadoop
使用hadoop用户上传hadoop压缩包,并实现解压
[hadoop@localhost hadoop]$ tar -zxvf hadoop-2.7.6.tar.gz
使用root用户创建软连接
[root@localhost hadoop-2.7.6]# ln -s /home/hadoop/apps/hadoop/hadoop-2.7.6 /usr/local/hadoop
使用root用户修改软连接属主
[root@localhost hadoop-2.7.6]# chown -R hadoop:hadoop /usr/local/hadoop
2.配置Hadoop环境变量
添加hadoop环境变量
[root@localhost hadoop-2.7.6]# vim /etc/profile
添加内容如下:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
保存后,使用命令生效配置
[root@localhost hadoop-2.7.6]# source /etc/profile
3.配置HDFS
使用hadoop用户进入到Hadoop配置文件路径
[hadoop@localhost hadoop]$ cd /usr/local/hadoop/etc/hadoop/
修改hadoop-env.sh文件
[hadoop@localhost hadoop]$ vim hadoop-env.sh
修改JDK路径
export JAVA_HOME=/usr/local/java
- 配置core-site.xml
具体配置内容如下:
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/usr/local/hadoop/hdpdata/
需要手动创建hdpdata目录
ha.zookeeper.quorum
hadoop01:2181,hadoop02:2181,hadoop03:2181
zookeeper地址,多个用逗号隔开
手动创建hddata目录
[hadoop@hadoop01 hadoop]$ mkdir hdpdata
- 配置hdfs-site.xml 文件信息,内容如下:
dfs.nameservices
ns
指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致
dfs.ha.namenodes.ns
nn1,nn2
ns命名空间下有两个NameNode,逻辑代号,随便起名字,分别是nn1,nn2
dfs.namenode.rpc-address.ns.nn1
hadoop01:9000
nn1的RPC通信地址
dfs.namenode.http-address.ns.nn1
hadoop01:50070
nn1的http通信地址
dfs.namenode.rpc-address.ns.nn2
hadoop02:9000
nn2的RPC通信地址
dfs.namenode.http-address.ns.nn2
hadoop02:50070
nn2的http通信地址
dfs.namenode.shared.edits.dir
qjournal://hadoop03:8485;hadoop04:8485;hadoop05:8485/ns
指定NameNode的edits元数据在JournalNode上的存放位置
dfs.journalnode.edits.dir
/usr/local/hadoop/journaldata
指定JournalNode在本地磁盘存放数据的位置,必须事先存在
dfs.ha.automatic-failover.enabled
true
开启NameNode失败自动切换
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
配置失败自动切换实现方式,使用内置的zkfc
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
配置隔离机制,多个机制用换行分割,先执行sshfence,执行失败后执行shell(/bin/true),/bin/true会直接返回0表示成功
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
使用sshfence隔离机制时需要ssh免登陆
dfs.ha.fencing.ssh.connect-timeout
30000
配置sshfence隔离机制超时时间
dfs.replication
3
设置block副本数为3
dfs.block.size
134217728
设置block大小是128M
- 配置yarn-site.xml 配置文件,具体内容如下:
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-ha
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop01
yarn.resourcemanager.webapp.address.rm1
${yarn.resourcemanager.hostname.rm1}:8088
HTTP访问的端口号
yarn.resourcemanager.hostname.rm2
hadoop02
yarn.resourcemanager.webapp.address.rm2
${yarn.resourcemanager.hostname.rm2}:8088
yarn.resourcemanager.zk-address
hadoop01:2181,hadoop02:2181,hadoop03:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/data/hadoop/yarn-logs
yarn.log-aggregation.retain-seconds
259200
yarn.scheduler.minimum-allocation-mb
2048
单个任务可申请最少内存,默认1024MB
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.resource.cpu-vcores
1
- 配置mapred-site.xml,内容如下:
mapreduce.framework.name
yarn
指定mr框架为yarn方式
mapreduce.jobhistory.address
hadoop02:10020
历史服务器端口号
mapreduce.jobhistory.webapp.address
hadoop02:19888
历史服务器的WEB UI端口号
mapreduce.jobhistory.joblist.cache.size
2000
内存中缓存的historyfile文件信息(主要是job对应的文件目录)
修改slaves文件,设置datanode和nodemanager启动节点主机名称
[hadoop@hadoop01 hadoop]$ pwd
/usr/local/hadoop/etc/hadoop
[hadoop@hadoop01 hadoop]$ vim slaves
将数据节点加入该文件
hadoop03
hadoop04
hadoop05
- 配置hadoop用户免密码登陆
配置hadoop01到hadoop01、hadoop02、hadoop03、hadoop04、hadoop05的免密码登陆
由于上文生成了hadoop01的SSH密码,且分发到了hadoop01,hadoop02,hadoop03.只需分发到hadoop04/hadoop05节点即可
ssh-copy-id -i hadoop04
ssh-copy-id -i hadoop05
在hadoop02节点上,使用hadoop用户生成密钥,并分发到各节点上
[hadoop@hadoop02 hadoop]$ ssh-keygen -t rsa
分发公钥到各节点上
[hadoop@hadoop02 hadoop]$ ssh-copy-id -i hadoop01
[hadoop@hadoop02 hadoop]$ ssh-copy-id -i hadoop02
[hadoop@hadoop02 hadoop]$ ssh-copy-id -i hadoop03
[hadoop@hadoop02 hadoop]$ ssh-copy-id -i hadoop04
[hadoop@hadoop02 hadoop]$ ssh-copy-id -i hadoop05
将配置好的hadoop文件拷贝到各节点
[hadoop@hadoop01 hadoop]$ scp -r /home/hadoop/apps/hadoop/hadoop-2.7.6 hadoop@hadoop02:/home/hadoop/apps/hadoop
[hadoop@hadoop01 hadoop]$ scp -r /home/hadoop/apps/hadoop/hadoop-2.7.6 hadoop@hadoop03:/home/hadoop/apps/hadoop
[hadoop@hadoop01 hadoop]$ scp -r /home/hadoop/apps/hadoop/hadoop-2.7.6 hadoop@hadoop04:/home/hadoop/apps/hadoop
[hadoop@hadoop01 hadoop]$ scp -r /home/hadoop/apps/hadoop/hadoop-2.7.6 hadoop@hadoop05:/home/hadoop/apps/hadoop
在每个节点分别执行如下步骤:
第一步:使用root用户创建软链接
ln -s /home/hadoop/apps/hadoop-2.7.4 /usr/local/hadoop
第二步:使用root用户修改软链接属主
chown -R hadoop:hadoop /usr/local/hadoop
第三步:使用root用户添加环境变量
vim /etc/profile
添加内容:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
第四步:使用root用户重新编译环境变量使配置生效
source /etc/profile
五、集群启动
1.hadoop用户启动journalnode(分别在hadoop03、hadoop04、hadoop05上执行启动)
[hadoop@hadoop03 hadoop]$ /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
[hadoop@hadoop05 hadoop]$ jps
3841 Jps
3806 JournalNode
2. 格式化HDFS
关闭并停用所有节点防火墙
[root@hadoop05 hadoop]# systemctl stop firewalld.service
[root@hadoop05 hadoop]# systemctl disable firewalld.service
在hadoop01上执行命令:
[hadoop@hadoop01 bin]$ hdfs namenode -format
格式化成功后,出现如下提示,则表示HDFS格式化成功
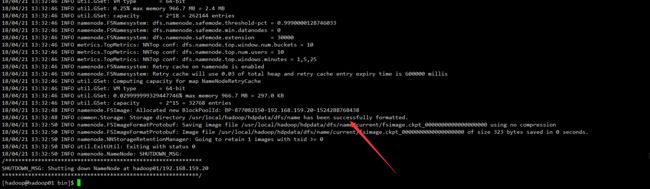
格式化成功之后会在core-site.xml中的hadoop.tmp.dir指定的路径下生成dfs文件夹,将该文件夹拷贝到hadoop02的相同路径下
[hadoop@hadoop01 hdpdata]$ scp -r /usr/local/hadoop/hdpdata hadoop@hadoop02:/usr/local/hadoop/
3.在hadoop01上执行格式化ZKFC操作
[hadoop@hadoop01 hdpdata]$ hdfs zkfc -formatZK
执行完成会出现如下内容

4. 在hadoop01上启动HDFS
- 启动HDFS
[hadoop@hadoop01 hdpdata]$ start-dfs.sh
- 启动yarn
[hadoop@hadoop01 hdpdata]$ start-yarn.sh
在hadoop02单独启动一个ResourceManger作为备份节点
[hadoop@hadoop02 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
在hadoop02上启动JobHistoryServer
[hadoop@hadoop02 hadoop]$ sbin/mr-jobhistory-daemon.sh start historyserver
管理地址访问:
NameNode (active):http://192.168.159.20:50070
NameNode (standby):http://192.168.159.21:50070
资源管理地址访问:
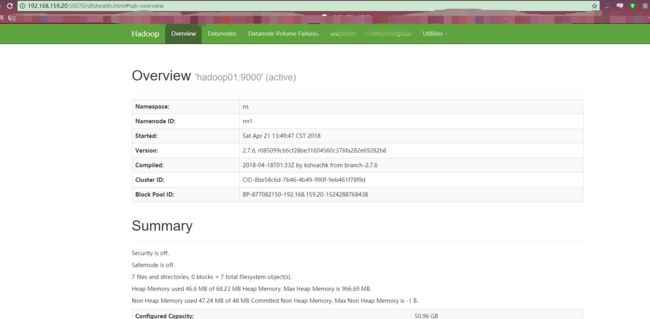
ResourceManager HTTP访问地址
ResourceManager :http://192.168.159.2:8088

六、集群验证
1.验证HDFS 是否正常工作及HA高可用
首先向hdfs上传一个文件
[hadoop@hadoop01 ~]$ hdfs dfs -put /home/hadoop/zookeeper.out /
查看上传结果
[hadoop@hadoop01 ~]$ hdfs dfs -ls /
Found 1 items
-rw-r--r-- 3 hadoop supergroup 42019 2018-04-22 14:33 /zookeeper.out
在active节点手动关闭active的namenode
sbin/hadoop-daemon.sh stop namenode
通过HTTP 50070端口查看standby namenode的状态是否转换为active
手动启动上一步关闭的namenode
sbin/hadoop-daemon.sh start namenode
2.验证YARN是否正常工作及ResourceManager HA高可用
运行测试hadoop提供的demo中的WordCount程序:
hadoop fs -mkdir /wordcount
hadoop fs -mkdir /wordcount/input
hadoop fs -mv /README.txt /wordcount/input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output
3.验证ResourceManager HA
手动关闭node02的ResourceManager
sbin/yarn-daemon.sh stop resourcemanager
通过HTTP 8088端口访问node01的ResourceManager查看状态
手动启动node02 的ResourceManager
sbin/yarn-daemon.sh start resourcemanager