背景
数据结构是指带有结构特性的数据元素的集合。在数据结构中,数据之间通过一定的组织结构关联在一起,便于计算机存储和使用。从大类划分,数据结构可以分为线性结构和非线性结构,适用于不同的应用场景。
- 线性结构:
线性结构作为最常用的数据结构,它的特点是单个数据之间存在一对一的线性关系。包含两种不同的存储结构:顺序存储结构和链式存储结构。顺序存储的线性表称为顺序表,顺序表中的存储元素是连续的。
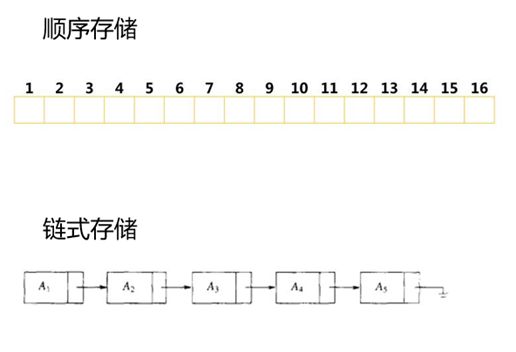
(线性结构)
链式存储的线性表被叫做链表,链表中的存储元素不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息
线性结构常见的有:数组、队列、链表和栈。
- 非线性结构:
除了线性结构,其他的数据结构均为非线性结构,特点是单个数据之间存在多个对应关系,常见的有:二维数组,多维数组,广义表,树结构,图结构
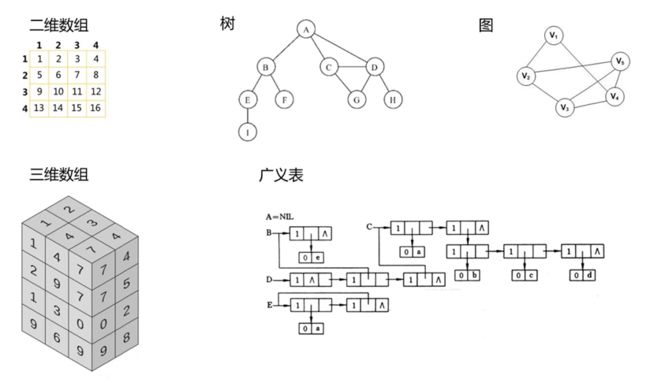
(常见的非线性结构)
稀疏数组(Sparse Array)
在各种各样的数据结构中,最基础、最常用的是数组。数组可以非常直观的表示数据在一维或多维空间中的关系,与现实中的情形更接近,所以被大多数程序员当做"首选"的数据结构,然而,在部分应用场景中使用数组存储数据时会出现各种各样的情况,这是就需要在数组的基础上,对数据结构进行优化,衍生出稀疏数组等新的数据结构。
以五子棋局为例,我们应该如何存储棋盘上的落子情况呢?

(使用二位数组存储五子棋盘)
如果使用一个二维数组对棋盘落子进行存储,当我们拿到一个棋盘类数据内容时,大部分内容都是没有意义的0,有意义数据并不相邻,很多空间被浪费。对于五子棋来说,这个问题可能不是很明显,但如果"棋盘"足够大,被浪费的空间就会影响到软件的功能实现,此时引入稀疏数组(SparseArray)就具有了重要的意义。
稀疏数组将数组中的内容进行压缩,存储在一个更为精练的二维数组中,稀疏数组的本质其实就是用时间置换空间。
具体的处理的方法是:
- 该数组之中一共有几行几列进行记录
- 把相同元素内容忽略后,只记录具有不同内容单元的位置
稀疏数组的实现
节约存储空间显然是稀疏数组的一个优势,但是读取性能是否可以会比二维数组差很多?
为了讲清这个问题,我们可以先看一下Android中SparseArray的实现逻辑。SparseArray内部是通过两个数组来进行数据存储的。一个存储key,另外一个存储value。我们从源代码中能够看到key和value各自是用数组表示:
private int[] mKeys;
private Object[] mValues;
同时,SparseArray在存储和读取数据时候,使用的是二分查找法:
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
...
}
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
...
}
在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好。所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。 而在获取数据的时候,也是使用二分查找法判断元素的位置,这样可以使数据的获取变得更加高效。所以,在key的数据量(可以理解为棋盘上去掉空白后的棋子数量)不大时,稀疏数组读取性能是有保障的。
典型应用场景
做开发的都知道,想让系统变快有个最简单的办法就是加内存。对于程序可以做大量的缓存来加速,即所谓"空间换时间"。但是在特定环境,程序可使用的内存是有限的。
在移动设备上,内存是个稀缺资源,例如iPhone 7的内存为2G,而最新款的iPhone 13也仅为4G。所以,稀疏数组这种"时间换空间"的技术最早被广泛应用在移动开发领域。
除了移动端,另一个内存紧缺的运行环境是浏览器。虽然没有明文规定,但在业界的共同认知里,浏览器会对单一线程进行内存限制,例如64位的chrome,每个tab页的内存消耗不允许超过4G。这个限制,在单页面应用还不成熟的十几年前,不会成为问题。因为,那时大家所关注的,还是如何提升后端的处理性能,前端只是一种静态的网页表达方式。
随着前端工程化的高速发展,各种前端工程脚手架日渐成熟,WebComponent标准被提上日程,企业开始由C/S向B/S应用转型。这就要求前端开发者,需要面对单页面处理复杂业务数据的挑战。前端程序从最开始设计以及整个开发过程中都需要考虑内存的使用情况,尽可能的降低内存占用,防止网页崩溃。以前端电子表格为例,我们通常需要为用户提供上百万个单元格(100列 x 1万行),但其中有数据的单元格可能只有几百个。为了减少数据模型占用的内存,我们最终的解决方式是将表格的数据存储方式由常规数组改成稀疏数组,内存占用可以降低到几十分之一,以确保浏览器内存不会被撑爆。
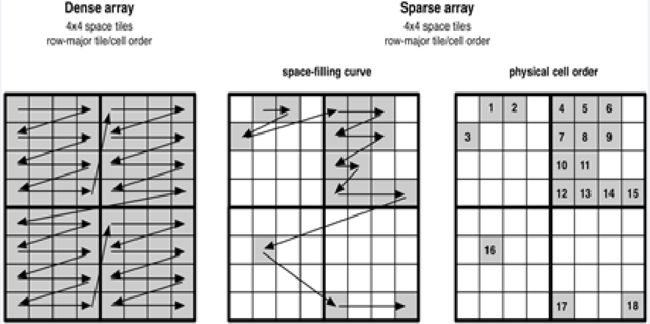
(稀疏矩阵存储策略)
不只是“时间换空间”;
相较于传统的链式存储或是数组存储,稀疏矩阵存储构建了基于索引Key的数据字典。在松散布局的表格数据中,稀疏矩阵只会对非空数据进行存储,而不需要对空数据开辟额外的内存空间。
使用这种特殊的存储策略,除了可以降低内存占用,还使得数据片段化变得容易,可以随时框取整个数据层中的一片数据,进行序列化或反序列化,而无需处理同一数据结构内的其他数据。
借用这样的特性,我们可以随时替换或恢复整个存储结构中的任何一个级别的节点,以改变引用的方式高效解决了表格数据回滚和恢复,而这一点也是电子表格支持在线协同的技术基础。
总结
本节为大家介绍了稀疏数组的基础知识,技术实现和应用场景,以前端电子表格为例,展示了这个技术在节约内存空间,实现回滚恢复等领域的优势。
在后续我们还会继续为大家介绍更多严肃和有趣的内容~

觉得不错点个赞再走吧~