遇到100万行的 Excel,还没打开,电脑和我都崩溃了,该怎么办?

CDA数据分析师 出品
作者:曹鑫
编辑:JYD

我真遇到了上百万行的 Excel
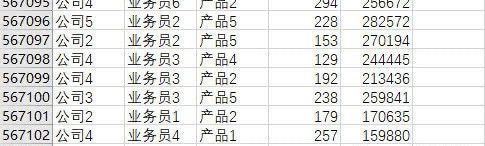
年底到了,我想把公司历年的销售明细和指标等业务数据放在一起透视做分析,觉得这样很方便,但是无奈一张表就50多万行,好几年的数据加在一起有两三百万行,受 excel行数限制,我只能将数据按年分开,一年一张表,每张表里的表头项目都是一样的。
业务发展越来越大,数据的规模会越来越大,在初期的时候,还觉得Excel 够用了,但是当 Excel 规模的数据量不断增加,我们开始发现打开 Excel 越来越慢,操作一下 Excel 要等很久。
直接双击打开?
最简单的方法,当然是双击打开,当你双击下去,看着鼠标变成旋转的模式,你就陷入了无尽的等待,听着电脑的机声音越来越大,最后还没打开,电脑和我就都崩溃了。这完全没法开展下一步的数据分析⼯作了,怎么办?
Access
首先想到的是个比较冷门,但又没那么冷门,好像学过,但又好像没用过,好像很难,但其实也没那么难的软件:Access。
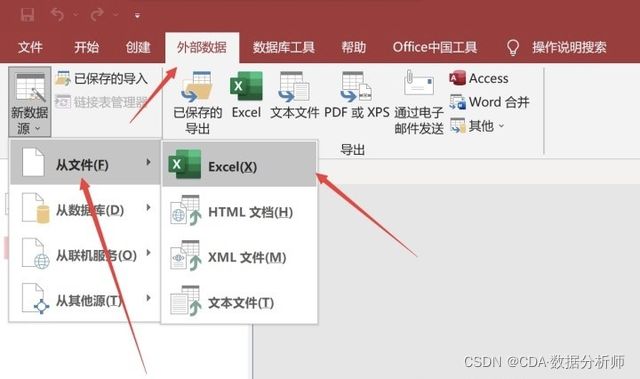
Access 导入 Excel 数据的操作很直观,打开 Access,点击「外部数据」-「新数据源」-「从文件」-「Excel」,按照指引一步步操作下去即可,而且 Access 也支持新表追加到旧表的后面,可以把几十万的表一张张拼接到一起。但估计你现在电脑里还有没有Access还不一定。
PowerBI
同样是微软出品的软件,现在更流行,你还可以选择 PowerBI 的一系列组合软件。
从Excel2010开始,微软推出了一个叫Power Query的插件,可以弥补Excel的不足,处理数据的能力边界大大提升,Excel2013也同样可以使用,现在还在用Excel2010和 2013的同学可以从微软官网下载powerquery插件使用。
而到了Excel2016,微软直接把PQ的功能嵌入进来,放在数据选项卡下。
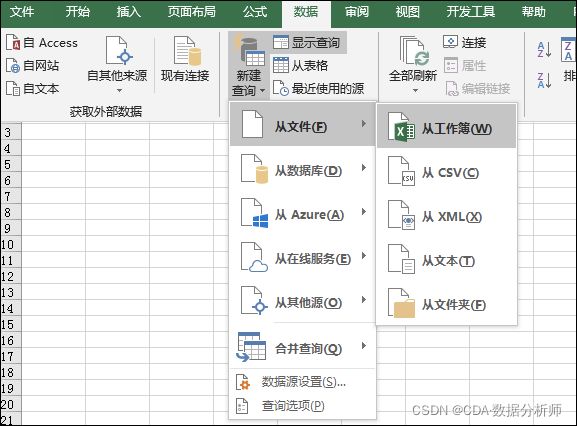
首先我们使用Excel2016打开一个空白的Excel工作簿文件,依次点击“数据/从文件/从工作簿”,在导航器界面,左侧列出了所有工作表,我们这个不是一个个去勾选加载,如果表很多,那么勾起来太麻烦,直接选任一个表,点击“转换数据”按钮,进入Power Query管理界面即可。
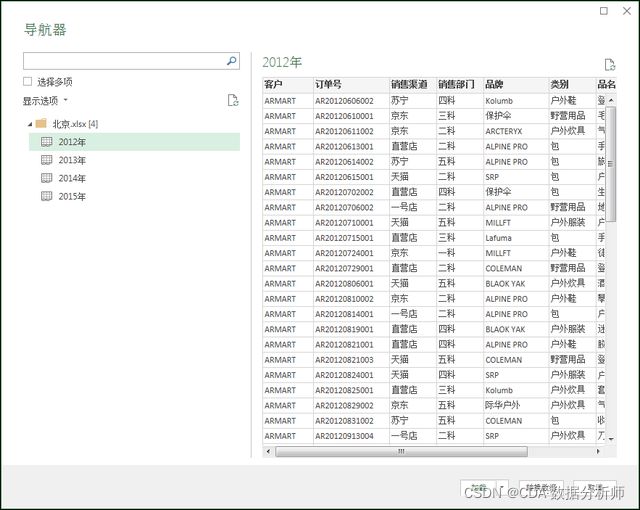
都说到这份儿上了,Python 党得出来说两句了:上百万行的数据还放在excel里面?!别说处理了,你连打开有时候可能都是问题。这种情况下最根本的办法了就是存入数据库然后再处理,即使再不济也可以放入access。可能有人会说可以是使用 power query或者power pivot来处理,但是,实际情况是这么大的数据量,PowerBI也很吃力。
那用 Python 试试?
Python 读取百万行的 Excel 大概要花费5分钟(以我以前的电脑配置 16GB 内存),如果你的配置更好,当然会更快,代码也很简单,如下图:
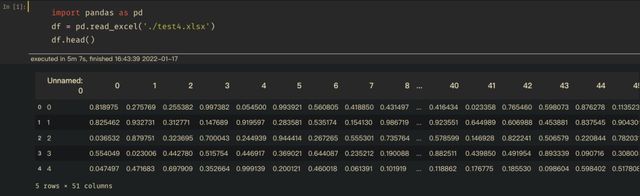
1.导入 pandas 包, import pandas as pd ,是最常用的数据处理包。
2.使入 pd.read_excel() 读取 test4.xlsx 文件,读取 Excel 有直接写好的方法。
3.使入 df.head() 查看一下前五行。
最终花了 5 分钟,才把这份 50 万行 50 列的数据打开了。虽然比起双击打开是要快一点的(至少打开了),但是还不满足,有没有更快的方式?这时候,就要开始跳出Excel,开始思考其他一些更高效的数据格式。
更高效的数据格式
CSV 格式
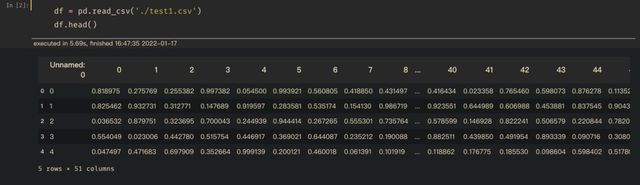
CSV文件,是一种以纯文本形式存储表格数据的简单文件格式。在CSV中,每列数据由特殊分隔符分割(如逗号,分号或制表符),用 Python 来读取都非常方便,只要格式规整,用 Pandas 里面的 read_csv 可以快速读取以上格式文件,在我的电脑上,同样是 50 万行 50 列的数据,原来打开要花 5 分钟,现在只花了 5 秒钟,速度提升了60倍:
Pickle 格式
当然 Python 里面还引入了其他的格式,你可能平时接触的不多,但是效果绝对让你惊喜。比如将数据存储为 pkl 的格式,“pickling” 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程。
我们来看看读取的速度,打开速度一下子提升到500毫秒。
从5分钟,到5秒钟,到500毫秒,没有最快只有更快。
随着业务扩展,数据量一定会越来越大。你也会面临着数据量越来越大,处理的效率越来越慢的问题。我们思考问题的路径就可以从软件 Access、PowerBI,到编程语言 Python,再到文件格式 Excel、CSV、Pickle,一路解决下去。