前言:本篇文章只是记录王争的数据结构与算法之美的学习笔记,写下来能强迫自己系统的再过一遍,加深理解。这门课
以实际开发中遇到的问题为例,引入解决问题涉及到的的数据结构和算法,但不会讲的太细,最好结合一本实体书进行学习。
二分查找底层依赖的是
数组随机访问的特性,所以使用数组来实现,如果数据存储于链表中,只需要对链表稍加改造,就可以支持类似“二分”的查找算法,改造之后的数据结构就叫做跳表。
1. 跳表
对于一个单链表来说,即使存储的数据是有序的,如果想要查找某个数据,也只能从头遍历链表,时间复杂度为 O(n),如下图:

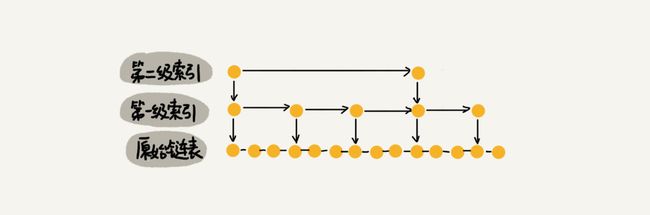
可以每两个结点提取一个结点到上一级,对链表建立一级索引,抽出来的这一级称为索引或者索引层,如下图所示:

如果查找值为 16 的结点,我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后通过索引节点的 down 指针,下降到原始链表,继续遍历,这时只需要再遍历 2 个节点,就可以找到值为 16 的结点了,这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
如果我们在第一级索引的基础上,再次抽出一个第二级索引,这样查找时需要遍历的结点数量又减少了,如下图:

如果数据很多,可以建立很多级索引:

当链表的长度 n 比较大时,在构建索引之后,查找效率的提升就会非常明显,这种
链表加多级索引的结构,就是跳表。
2. 时间复杂度
一个链表有 n 个结点,每两个结点会抽出一个结点作为上一级索引的节点,那么第一级索引的结点个数大约n/2,第二级索引的结点个数大约为n/4,那么第 k 级索引的结点个数就是 n/(2^k)。
假设索引由 h 级,最高级的索引由 2 个节点,可以得到n/(2^h) = 2,得出h=log2n-1,如果包含原始链表这一层,整个跳表的高度就是 log2n,我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那么在跳表中查询一个数据的时间复杂度就是O(m * logn)。
按照前面那种索引结构,每一级索引最多只需要遍历 3 个结点,也就是 m = 3,那么为什么是 3 呢?
假如查找的数据是 x,在第 k 级索引中,遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以通过 y 的 down 指针,从第 k 级索引下降到第 k-1级索引。在第k - 1级索引中,y 和 z 之间只有 3 个节点(包含 y 和 z),所以,在 k-1级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点,如下图:
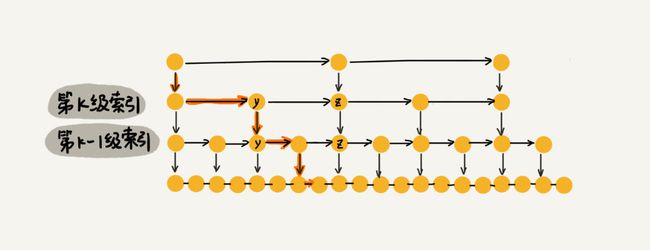
所以 m=3,在跳表中查询任意数据的时间复杂度就是 O(logn),这个查找的时间复杂度跟二分查找是一样的。但是这种查询效率的提升的前提是建立了很多索引,用空间换时间。
3. 空间复杂度
相对于单链表,跳表需要存储很多索引,需要更多的存储空间。
假设原始链表大小为 n,我们来看下每层索引的结点数:

结点总和就是n/2 + n/4 + n/8 + ... + 4 + 2 = n - 2,所以跳表的空间复杂度为O(n)。
上面是每两个结点抽一个结点到上级索引,我们可以每 3 个结点,或者每 5 个结点,抽一个结点到上级索引,这样就不用那么多索引节点了,如下图所示:
上面是每 3 个结点抽一个结点到上级索引,我们也把每级索引的结点个数都写下来,也是一个等比数列:

总的索引结点大约就是 n/3+n/9+n/27+...+9+3+1=n/2,虽然空间复杂度还是 O(n),但是相比于每两个结点抽一个结点的索引构建方法,要减少了一半的索引节点存储空间。
软件开发中,不必太在意索引占用的额外空间,索引节点只需要存储关键值和几个指针,不需要存储对象。
4. 插入和删除结点
跳表是一个动态的数据结构,不仅支持查找,还支持动态的插入、删除,时间复杂度也是 O(logn)。
在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是 O(1),但是耗时的是查找操作,时间复杂度为 O(n)。但是在跳表中查找某个结点的时间复杂度是 O(logn),所以查找某个数据应该插入的位置时间复杂度也是 O(logn),如下图:

删除时,如果这个结点在索引中也有出现,除了要删除原始链表中的结点,还要删除索引中的,所以在查找要删除的结点的时候,一定要获取前驱结点。
5. 索引动态更新
上面提到的插入操作如果很多的时候,如果不更新索引,就可能出现某 2 个索引结点之间数据非常多的情况,极端情况下,还会退化成单链表,如下图:
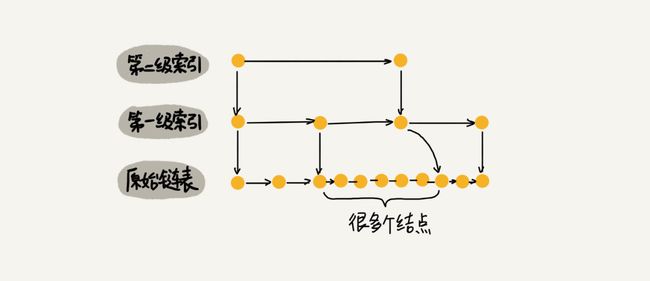
跳表是通过随机函数来维护这个平衡性的。
当往跳表中插入数据的时候,可以选择同时将这个数据插入到部分索引层中,通过一个随机函数,去决定将这个结点插入到哪几级索引中,比如随机函数生成了值 k,那就将这个结点加到第一级到第 k 级这 k 级索引中。
随机函数,从概率上来讲,能够保证跳表的索引大小和数据大小的平衡性,不至于性能过度退化。
6. 总结
Redis 中的有序集合是通过跳表 + 散列表来实现的。
跳表是一种动态数据结构,使用了空间换时间的设计思路,通过构建多级索引来提高查询的效率,支持快速插入、删除、查找,时间复杂度为 O(logn),空间复杂度为 O(n)。