xcel电子表格是您有时必须处理的事情之一。要么是因为您的老板喜欢它们,要么是因为市场营销需要它们,您可能必须学习如何使用电子表格,这才对了解openpyxl有用!
电子表格是一种非常直观且用户友好的方式,无需任何技术背景即可操作大型数据集。这就是为什么它们今天仍然如此普遍。
在本文中,您将学习如何使用openpyxl进行以下操作:
- 自信地处理Excel电子表格
- 从电子表格中提取信息
- 创建简单或更复杂的电子表格,包括添加样式,图表等
本文是为那些对Python数据结构(如字典和列表)有相当了解的中级开发人员撰写的,同时他们对OOP和更多中级主题也很满意。
下载数据集: 单击此处下载本教程将关注的openpyxl练习的数据集。
在你开始之前
如果您被要求从数据库或日志文件中提取一些数据到Excel电子表格中,或者经常需要将Excel电子表格转换成更有用的编程形式,那么本教程非常适合您。让我们跳进openpyxl商队!
实际用例
首先,您什么时候需要像openpyxl实际情况一样使用软件包?您将在下面看到一些示例,但实际上,在数百种可能的情况下,这些知识可以派上用场。
将新产品导入数据库
您负责一家在线商店公司的技术,而您的老板不想为一个酷而昂贵的CMS系统付费。
每当他们想要将新产品添加到在线商店时,他们都会向您提供一个包含几百行的Excel电子表格,并且每行都有产品名称,描述,价格等。
现在,要导入数据,您必须遍历每个电子表格行并将每个产品添加到在线商店。
将数据库数据导出到电子表格
假设您有一个数据库表,其中记录了所有用户的信息,包括姓名,电话号码,电子邮件地址等。
现在,营销团队希望与所有用户联系,为他们提供一些折扣优惠或促销。但是,他们无权访问数据库,或者他们不知道如何使用SQL轻松提取信息。
你能帮什么忙?好吧,您可以使用快速脚本来openpyxl迭代每个用户记录,并将所有基本信息放入Excel电子表格中。
那将为您在公司的下一个生日聚会上多赚一块蛋糕!
将信息追加到现有电子表格
您可能还必须打开电子表格,读取其中的信息,然后根据某些业务逻辑将更多数据附加到该电子表格中。
例如,再次使用在线商店场景,假设您获得一个包含用户列表的Excel电子表格,则需要将他们在商店中花费的总金额追加到每一行。
此数据位于数据库中,为此,您必须阅读电子表格,遍历每一行,从数据库中获取花费的总金额,然后写回电子表格。
没问题openpyxl!
学习一些基本的Excel术语
这是使用Excel电子表格时会看到的基本术语的快速列表:
| 术语 | 说明 |
|---|---|
| 电子表格或工作簿 | 一个电子表格是要创建或一起工作的主要文件。 |
| 工作表或工作表 | 工作表用于在同一电子表格中拆分不同类型的内容。一个电子表格可以有一个或多个表。 |
| 柱 | 甲列是垂直线,并且它是由一个大写字母表示:甲。 |
| 行 | 甲行是水平行,它是由一个数字代表:1。 |
| 细胞 | 甲细胞是的组合列和行,通过两个大写字母和一个数字代表:A1。 |
openpyxl入门
既然您已经了解了诸如之类的工具的优势,那么openpyxl让我们开始吧,从安装软件包开始。对于本教程,您应该使用Python 3.7和openpyxl 2.6.2。要安装该软件包,您可以执行以下操作:
$ pip install openpyxl 安装软件包后,您应该可以使用以下代码创建一个超级简单的电子表格:
from openpyxl import Workbook
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "hello"
sheet["B1"] = "world!"
workbook.save(filename="hello_world.xlsx")
上面的代码应hello_world.xlsx在用于运行代码的文件夹中创建一个名为的文件。如果您使用Excel打开该文件,则应该看到类似以下内容的内容:
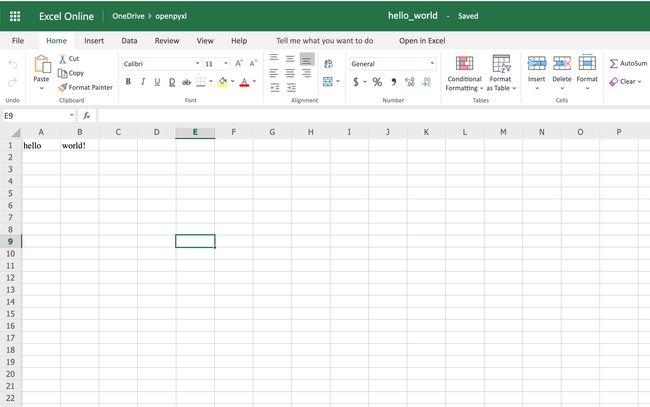
Woohoo,您创建的第一个电子表格!
使用openpyxl阅读Excel电子表格
让我们从使用电子表格可以做的最重要的事情开始:阅读它。
您将从直接读取电子表格的简单方法,到更复杂的示例,在这些示例中读取数据并将其转换为更有用的Python结构。
本教程的数据集
在深入研究一些代码示例之前,应下载此样本数据集并将其存储为sample.xlsx:
下载数据集: 单击此处下载本教程将关注的openpyxl练习的数据集。
这是您在整个教程中将使用的数据集之一,并且是一个电子表格,其中包含来自亚马逊在线产品评论的真实数据样本。该数据集只是Amazon 提供的内容的一小部分,但出于测试目的,它绰绰有余。
读取Excel电子表格的简单方法
最后,让我们开始阅读一些电子表格!首先,打开示例电子表格:
from openpyxl import load_workbook
workbook = load_workbook(filename="sample.xlsx")
workbook.sheetnames
['Sheet 1']
sheet = workbook.active
sheet
sheet.title
'Sheet 1'`
在上面的代码,你第一次打开电子表格sample.xlsx使用load_workbook(),然后你可以使用workbook.sheetnames可查看所有具有可与工作表。之后,workbook.active选择第一个可用的工作表,在这种情况下,您会看到它自动选择了工作表1。使用这些方法是打开电子表格的默认方法,您将在本教程中多次看到它。
现在,打开电子表格后,您可以像这样轻松地从其中检索数据:
sheet["A1"]
sheet["A1"].value
'marketplace'
sheet["F10"].value
"G-Shock Men's Grey Sport Watch"`
要返回单元格的实际值,您需要执行.value。否则,您将获得主要Cell对象。您也可以使用该方法.cell()使用索引符号检索单元格。请记住添加.value以获取实际值而不是Cell对象:
sheet.cell(row=10, column=6)
sheet.cell(row=10, column=6).value
"G-Shock Men's Grey Sport Watch"`
无论您决定采用哪种方式,您都可以看到返回的结果是相同的。但是,在本教程中,您将主要使用第一种方法:["A1"]。
注意:即使在Python中,您习惯于使用零索引的符号,但对于电子表格,您将始终使用单索引的符号,其中第一行或第一列始终具有index 1。
上面显示了打开电子表格的最快方法。但是,您可以传递其他参数来更改电子表格的加载方式。
其他阅读选项
您可以传递一些参数来load_workbook()更改电子表格的加载方式。最重要的是以下两个布尔值:
- read_only以只读模式加载电子表格,使您可以打开非常大的Excel文件。
- data_only忽略加载公式,而是仅加载结果值。
从电子表格导入数据
既然您已经了解了有关加载电子表格的基础知识,那么现在该开始了解有趣的部分了:电子表格中值的迭代和实际用法。
在本节中,您将学习可以遍历数据的所有不同方式,还可以学习如何将数据转换为可用的数据,更重要的是,如何以Python的方式进行处理。
遍历数据
您可以根据需要使用几种不同的方法来遍历数据。
您可以使用列和行的组合对数据进行切片:
sheet["A1:C2"]
((, | , | ), |
(, | , | ))` |
您可以获得行或列的范围:
Get all cells from column A
sheet["A"]
(, |
, |
...
, |
) |
Get all cells for a range of columns
sheet["A:B"]
((, |
, |
...
, |
), |
(, |
, |
...
, |
)) |
Get all cells from row 5
sheet[5]
(, |
, |
sheet.cell(row=10, column=6)
|
>>> sheet.cell(row=10, column=6).value
"G-Shock Men's Grey Sport Watch"无论您决定采用哪种方式,您都可以看到返回的结果是相同的。但是,在本教程中,您将主要使用第一种方法:["A1"]。 **注意:**即使在Python中,您习惯于使用零索引的符号,但对于电子表格,您将始终使用单索引的符号,其中第一行或第一列始终具有index1。 上面显示了打开电子表格的最快方法。但是,您可以传递其他参数来更改电子表格的加载方式。 #### 其他阅读选项 您可以传递一些参数来load_workbook()更改电子表格的加载方式。最重要的是以下两个布尔值: 1. **read_only**以只读模式加载电子表格,使您可以打开非常大的Excel文件。 2. **data_only**忽略加载公式,而是仅加载结果值。 ### 从电子表格导入数据 既然您已经了解了有关加载电子表格的基础知识,那么现在该开始了解有趣的部分了:**电子表格中值的迭代和实际用法**。 在本节中,您将学习可以遍历数据的所有不同方式,还可以学习如何将数据转换为可用的数据,更重要的是,如何以Python的方式进行处理。 #### 遍历数据 您可以根据需要使用几种不同的方法来遍历数据。 您可以使用列和行的组合对数据进行切片: >>> >>> sheet["A1:C2"] ((, | , | ), ( | , | , | )) |
您可以获得行或列的范围:
>>>
>>> # Get all cells from column A
>>> sheet["A"]
(, |
, |
...
, |
) |
>>> # Get all cells for a range of columns
>>> sheet["A:B"]
((, |
, |
...
, |
), |
(, |
, |
...
, |
)) |
>>> # Get all cells from row 5
>>> sheet[5]
(, |
, |
...
, |
) |
Get all cells for a range of rows
sheet[5:6]
((, |
, |
...
, |
), |
(, |
, |
...
, |
))` |
您会注意到,以上所有示例均返回tuple。如果要刷新有关如何tuples在Python中进行处理的记忆,请查看有关Python中的列表和元组的文章。
还有多种使用普通Python 生成器浏览数据的方法。您可以使用的主要方法是:
.iter_rows().iter_cols()
这两种方法都可以接收以下参数:
min_rowmax_rowmin_colmax_col
这些参数用于设置迭代的边界:
for row in sheet.iter_rows(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3):
... print(row)
(, | , | ) |
(, | , | ) |
for column in sheet.iter_cols(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3):
... print(column)
(, | ) |
(, | ) |
(, | )` |
您会注意到,在第一个示例中,使用遍历行时.iter_rows(),tuple每行选定一个元素。在使用.iter_cols()和遍历列时,tuple每列将获得一个。
您可以传递给这两种方法的另一个参数是Boolean values_only。设置True为时,将返回单元格的值,而不是Cell对象:
for value in sheet.iter_rows(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id')
('US', 3653882, 'R3O9SGZBVQBV76')`
如果要遍历整个数据集,则还可以使用属性.rows或.columns直接使用属性,这是使用.iter_rows()和.iter_cols()不使用任何参数的快捷方式:
for row in sheet.rows:
... print(row)
(, | , | |
...
, | , | )` |
当您遍历整个数据集时,这些快捷方式非常有用。
使用Python的默认数据结构处理数据
既然您已经知道在工作簿中遍历数据的基础知识,那么让我们看一下将数据转换为Python结构的明智方法。
如您先前所见,所有迭代的结果都以的形式出现tuples。但是,由于a tuple只是不可变的list,因此您可以轻松访问其数据并将其转换为其他结构。
例如,假设您要从sample.xlsx电子表格中提取产品信息并放入字典中,其中每个键都是产品ID。
一种简单的方法是遍历所有行,选择与产品信息相关的列,然后将其存储在字典中。让我们对此进行编码!
首先,看看标题,看看您最关心的信息是:
for value in sheet.iter_rows(min_row=1,
... max_row=1,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id', 'product_id', ...)`
此代码返回电子表格中所有列名称的列表。首先,获取名称如下的列:
product_idproduct_parentproduct_titleproduct_category
幸运的是,您需要的列彼此相邻,因此您可以使用min_column和max_column轻松获得所需的数据:
>>> for value in sheet.iter_rows(min_row=2, ... min_col=4, ... max_col=7, ... values_only=True): ... print(value) ('B00FALQ1ZC', 937001370, 'Invicta Women\'s 15150 "Angel" 18k Yellow...) ('B00D3RGO20', 484010722, "Kenneth Cole New York Women's KC4944...) ... 真好!现在您知道了如何获取所需的所有重要产品信息,下面将这些数据放入字典中:
import json
from openpyxl import load_workbook
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
products = {}
Using the values_only because you want to return the cells' values
for row in sheet.iter_rows(min_row=2,
min_col=4,
max_col=7,
values_only=True):
product_id = row[0]
product = {
"parent": row[1],
"title": row[2],
"category": row[3]
}
products[product_id] = product
Using json here to be able to format the output for displaying later
print(json.dumps(products))`
上面的代码返回类似于以下内容的JSON:
{ "B00FALQ1ZC": { "parent": 937001370, "title": "Invicta Women's 15150 ...", "category": "Watches" }, "B00D3RGO20": { "parent": 484010722, "title": "Kenneth Cole New York ...", "category": "Watches" } } 在这里您可以看到输出仅修剪为2个产品,但是如果按原样运行脚本,则应该得到98个产品。
将数据转换成Python类
为了最终完成本教程的阅读部分,让我们深入研究Python类,看看如何改进上面的示例并更好地构造数据。
为此,您将使用Python 3.7中可用的新Python 数据类。如果您使用的是旧版本的Python,则可以使用默认的类。
因此,首先,让我们看一下您拥有的数据,并决定要存储的内容和存储方式。
正如您一开始就看到的那样,这些数据来自Amazon,并且是产品评论的列表。您可以在Amazon上查看所有列的列表及其含义。
您可以从可用数据中提取两个重要元素:
- 产品展示
- 评论
一个产品有:
- ID
- 标题
- 父母
- 类别
该评论还有更多字段:
- ID
- 客户ID
- 星星
- 标题
- 身体
- 日期
您可以忽略一些检查字段,以使事情变得简单一些。
因此,可以在一个单独的文件中编写这两个类的直接实现classes.py:
import datetime
from dataclasses import dataclass
@dataclass
class Product:
id: str
parent: str
title: str
category: str
@dataclass
class Review:
id: str
customer_id: str
stars: int
headline: str
body: str
date: datetime.datetime`
定义数据类后,您需要将电子表格中的数据转换为这些新结构。
在进行转换之前,值得再次看一下标题,并在列和所需字段之间创建映射:
`>>> for value in sheet.iter_rows(min_row=1,
... max_row=1,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id', 'product_id', ...)Or an alternative
for cell in sheet[1]:
... print(cell.value)
marketplace
customer_id
review_id
product_id
product_parent
...`
让我们创建一个文件mapping.py,其中包含所有字段名称及其在电子表格中的列位置(零索引)的列表:
Product fields
PRODUCT_ID = 3
PRODUCT_PARENT = 4
PRODUCT_TITLE = 5
PRODUCT_CATEGORY = 6
Review fields
REVIEW_ID = 2
REVIEW_CUSTOMER = 1
REVIEW_STARS = 7
REVIEW_HEADLINE = 12
REVIEW_BODY = 13
REVIEW_DATE = 14`
您不一定必须执行上面的映射。解析行数据时,这样做更具可读性,因此最终不会出现很多魔术数字。
最后,让我们看一下将电子表格数据解析为产品列表和审阅对象所需的代码:
`from datetime import datetime
from openpyxl import load_workbook
from classes import Product, Review
from mapping import PRODUCT_ID, PRODUCT_PARENT, PRODUCT_TITLE,
PRODUCT_CATEGORY, REVIEW_DATE, REVIEW_ID, REVIEW_CUSTOMER,
REVIEW_STARS, REVIEW_HEADLINE, REVIEW_BODYUsing the read_only method since you're not gonna be editing the spreadsheet
workbook = load_workbook(filename="sample.xlsx", read_only=True)
sheet = workbook.activeproducts = []
reviews = []Using the values_only because you just want to return the cell value
for row in sheet.iter_rows(min_row=2, values_only=True):
product = Product(id=row[PRODUCT_ID],
parent=row[PRODUCT_PARENT],
title=row[PRODUCT_TITLE],
category=row[PRODUCT_CATEGORY])
products.append(product)# You need to parse the date from the spreadsheet into a datetime format spread_date = row[REVIEW_DATE] parsed_date = datetime.strptime(spread_date, "%Y-%m-%d") review = Review(id=row[REVIEW_ID], customer_id=row[REVIEW_CUSTOMER], stars=row[REVIEW_STARS], headline=row[REVIEW_HEADLINE], body=row[REVIEW_BODY], date=parsed_date) reviews.append(review)print(products[0])
print(reviews[0])`
运行上面的代码后,应该获得如下输出:
Product(id='B00FALQ1ZC', parent=937001370, ...)
Review(id='R3O9SGZBVQBV76', customer_id=3653882, ...)`
而已!现在,您应该以非常简单和可消化的类格式获取数据,并且可以开始考虑将其存储在数据库或您喜欢的任何其他类型的数据存储中。
使用这种OOP策略解析电子表格可以使以后的数据处理变得更加简单。
追加新数据
在开始创建非常复杂的电子表格之前,快速浏览一下如何将数据附加到现有电子表格的示例。
返回您创建的第一个示例电子表格(hello_world.xlsx),然后尝试将其打开并向其中添加一些数据,如下所示:
`from openpyxl import load_workbook
Start by opening the spreadsheet and selecting the main sheet
workbook = load_workbook(filename="hello_world.xlsx")
sheet = workbook.active
Write what you want into a specific cell
sheet["C1"] = "writing ;)"
Save the spreadsheet
workbook.save(filename="hello_world_append.xlsx"`
等等,如果您打开新的hello_world_append.xlsx电子表格,则会看到以下更改:

注意单元格上的其他文字;)C1。
使用openpyxl编写Excel电子表格
您可以将多种内容写入电子表格,从简单的文本或数字值到复杂的公式,图表甚至是图像。
让我们开始创建一些电子表格!
创建一个简单的电子表格
以前,您看到了一个非常快速的示例,该示例如何编写“ Hello world!”。到电子表格中,因此您可以从以下内容开始:
1 from openpyxl import Workbook
2
3 filename = "hello_world.xlsx"
4
5 workbook = Workbook()
6 sheet = workbook.active
7
8 sheet["A1"] = "hello"
9 sheet["B1"] = "world!" 10
11 workbook.save(filename=filename)`
上面代码中突出显示的行是最重要的代码行。在代码中,您可以看到:
- 第5行显示了如何创建一个新的空工作簿。
- 第8和9行显示了如何向特定单元格添加数据。
- 第11行显示完成后如何保存电子表格。
即使上面的这些行很简单,但是当事情变得更加复杂时,还是很了解它们仍然是一件好事。
注意:您将在下面的hello_world.xlsx一些示例中使用电子表格,因此请随时使用。
您可以采取以下措施来帮助实现下面的代码示例:将以下方法添加到Python文件或控制台:
def print_rows():
... for row in sheet.iter_rows(values_only=True):
... print(row)`
通过调用,可以更轻松地打印所有电子表格值print_rows()。
电子表格的基本操作
在您进入更高级的主题之前,对您而言,了解如何管理电子表格中最简单的元素非常有帮助。
添加和更新单元格值
您已经学习了如何向电子表格中添加值,如下所示:
sheet["A1"] = "value"`
还有另一种方法,您可以先选择一个单元格,然后更改其值:
cell = sheet["A1"]
cell
cell.value
'hello'
cell.value = "hey"
cell.value
'hey'`
调用后,新值仅存储到电子表格中workbook.save()。
在openpyxl添加值时,如果该小区之前并不存在创建一个单元格:
Before, our spreadsheet has only 1 row
print_rows()
('hello', 'world!')
Try adding a value to row 10
sheet["B10"] = "test"
print_rows()
('hello', 'world!')
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, 'test')`
如您所见,当尝试向cell中添加一个值时B10,最终得到一个具有10行的元组,只是您可以拥有该测试值。
管理行和列
处理电子表格时,最常见的事情之一就是添加或删除行和列。该openpyxl软件包允许您使用以下方法以非常直接的方式执行此操作:
.insert_rows().delete_rows().insert_cols().delete_cols()
这些方法中的每个方法都可以接受两个参数:
idxamount
hello_world.xlsx再次使用我们的基本示例,让我们看看这些方法如何工作:
print_rows()
('hello', 'world!')
Insert a column before the existing column 1 ("A")
sheet.insert_cols(idx=1)
print_rows()
(None, 'hello', 'world!')
Insert 5 columns between column 2 ("B") and 3 ("C")
sheet.insert_cols(idx=3, amount=5)
print_rows()
(None, 'hello', None, None, None, None, None, 'world!')
Delete the created columns
sheet.delete_cols(idx=3, amount=5)
sheet.delete_cols(idx=1)
print_rows()
('hello', 'world!')
Insert a new row in the beginning
sheet.insert_rows(idx=1)
print_rows()
(None, None)
('hello', 'world!')
Insert 3 new rows in the beginning
sheet.insert_rows(idx=1, amount=3)
print_rows()
(None, None)
>>> # Before, our spreadsheet has only 1 row
>>> print_rows()
('hello', 'world!')
>>> # Try adding a value to row 10
>>> sheet["B10"] = "test"
>>> print_rows()
('hello', 'world!')
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, 'test')如您所见,当尝试向cell中添加一个值时B10,最终得到一个具有10行的元组,只是您可以拥有该*测试*值。 #### 管理行和列 处理电子表格时,最常见的事情之一就是添加或删除行和列。该openpyxl软件包允许您使用以下方法以非常直接的方式执行此操作: *.insert_rows()*.delete_rows()*.insert_cols()*.delete_cols()这些方法中的每个方法都可以接受两个参数: 1.idx2.amounthello_world.xlsx`再次使用我们的基本示例,让我们看看这些方法如何工作:
>>>
>>> print_rows()
('hello', 'world!')
>>> # Insert a column before the existing column 1 ("A")
>>> sheet.insert_cols(idx=1)
>>> print_rows()
(None, 'hello', 'world!')
>>> # Insert 5 columns between column 2 ("B") and 3 ("C")
>>> sheet.insert_cols(idx=3, amount=5)
>>> print_rows()
(None, 'hello', None, None, None, None, None, 'world!')
>>> # Delete the created columns
>>> sheet.delete_cols(idx=3, amount=5)
>>> sheet.delete_cols(idx=1)
>>> print_rows()
('hello', 'world!')
>>> # Insert a new row in the beginning
>>> sheet.insert_rows(idx=1)
>>> print_rows()
(None, None)
('hello', 'world!')
>>> # Insert 3 new rows in the beginning
>>> sheet.insert_rows(idx=1, amount=3)
>>> print_rows()
(None, None)
(None, None)
(None, None)
(None, None)
('hello', 'world!')
Delete the first 4 rows
sheet.delete_rows(idx=1, amount=4)
print_rows()
('hello', 'world!')`
你需要记住的唯一的事情是,插入新的数据(行或列)时,插入发生前的idx参数。
因此,如果这样做insert_rows(1),它将在现有的第一行之前插入一个新行。
列是相同的:调用时insert_cols(2),它将在已经存在的第二列()之前插入一个新列B。
但是,在删除行或列时,将从作为参数传递的索引开始.delete_...删除数据。
例如,执行delete_rows(2)此操作将删除row 2,执行delete_cols(3)此操作时将删除第三列(C)。
管理表
表单管理也是您可能需要知道的事情之一,即使它可能不经常使用。
如果回头看一下本教程中的代码示例,您会注意到以下重复出现的代码:
sheet = workbook.active 这是从电子表格中选择默认工作表的方法。但是,如果要打开包含多个工作表的电子表格,则始终可以选择特定的工作表,如下所示:
`>>> # Let's say you have two sheets: "Products" and "Company Sales"workbook.sheetnames
['Products', 'Company Sales']You can select a sheet using its title
products_sheet = workbook["Products"]
sales_sheet = workbook["Company Sales"]`
您也可以非常轻松地更改工作表标题:
`>>> workbook.sheetnames
['Products', 'Company Sales']products_sheet = workbook["Products"]
products_sheet.title = "New Products"workbook.sheetnames
['New Products', 'Company Sales']`
如果要创建或删除工作表,也可以使用.create_sheet()和进行操作.remove():
`>>> workbook.sheetnames
['Products', 'Company Sales']operations_sheet = workbook.create_sheet("Operations")
workbook.sheetnames
['Products', 'Company Sales', 'Operations']You can also define the position to create the sheet at
hr_sheet = workbook.create_sheet("HR", 0)
workbook.sheetnames
['HR', 'Products', 'Company Sales', 'Operations']To remove them, just pass the sheet as an argument to the .remove()
workbook.remove(operations_sheet)
workbook.sheetnames
['HR', 'Products', 'Company Sales']workbook.remove(hr_sheet)
workbook.sheetnames
['Products', 'Company Sales']`
您可以做的另一件事是使用来复制工作表copy_worksheet():
`>>> workbook.sheetnames
['Products', 'Company Sales']products_sheet = workbook["Products"]
workbook.copy_worksheet(products_sheet)
workbook.sheetnames
['Products', 'Company Sales', 'Products Copy']`
如果您保存上面的代码后,打开您的电子表格,你会发现,板材产品复制是片的重复产品。
冻结行和列
使用大型电子表格时,您可能需要冻结几行或几列,以便在向右或向下滚动时它们仍然可见。
冻结数据使您可以随时关注重要的行或列,无论在电子表格中的滚动位置如何。
同样,openpyxl也可以通过使用worksheet freeze_panes属性来实现此目的。对于此示例,请返回我们的sample.xlsx电子表格并尝试执行以下操作:
`>>> workbook = load_workbook(filename="sample.xlsx")sheet = workbook.active
sheet.freeze_panes = "C2"
workbook.save("sample_frozen.xlsx")`
如果您打开sample_frozen.xlsx您最喜爱的电子表格编辑器的电子表格,你会发现该行1和列A,并B有冷冻总是可见无论身在何处,你的电子表格中导航。
例如,此功能很方便,可以使标题不可见,因此您始终知道每一列代表什么。
在编辑器中的外观如下:

请注意,您位于电子表格的末尾,但是您可以同时看到行1和列A以及B。
添加过滤器
您可以用来openpyxl向电子表格添加过滤器和排序。但是,当您打开电子表格时,不会根据这些排序和过滤器重新排列数据。
乍一看,这似乎是一个非常无用的功能,但是当您以编程方式创建要由其他人发送和使用的电子表格时,至少创建过滤器并允许人们以后使用它仍然是一件好事。
下面的代码是如何向现有sample.xlsx电子表格添加一些过滤器的示例:
`>>> # Check the used spreadsheet space using the attribute "dimensions"sheet.dimensions
'A1:O100'sheet.auto_filter.ref = "A1:O100"
workbook.save(filename="sample_with_filters.xlsx")`
现在,您应该会看到在编辑器中打开电子表格时创建的过滤器:

sheet.dimensions如果您确切知道要将过滤器应用于电子表格的哪一部分,则无需使用。
添加公式
公式(或多个公式)是电子表格最强大的功能之一。
它们使您能够将特定的数学方程式应用于一系列单元格。与公式一起使用openpyxl就像编辑单元格的值一样简单。
您可以看到以下支持的公式列表openpyxl:
`>>> from openpyxl.utils import FORMULAEFORMULAE
frozenset({'ABS',
'ACCRINT',
'ACCRINTM',
'ACOS',
'ACOSH',
'AMORDEGRC',
'AMORLINC',
'AND',
...
'YEARFRAC',
'YIELD',
'YIELDDISC',
'YIELDMAT',
'ZTEST'})`
让我们向sample.xlsx电子表格中添加一些公式。
从简单的事情开始,让我们检查电子表格中99条评论的平均星级:
`>>> # Star rating is column "H"sheet["P2"] = "=AVERAGE(H2:H100)"
workbook.save(filename="sample_formulas.xlsx")`
如果现在打开电子表格并转到单元格P2,则应该看到其值为:4.18181818181818。在编辑器中查看:

您可以使用相同的方法将任何公式添加到电子表格中。例如,让我们计算获得有用投票的评论数量:
`>>> # The helpful votes are counted on column "I"sheet["P3"] = '=COUNTIF(I2:I100, ">0")'
workbook.save(filename="sample_formulas.xlsx")`
您应该像这样21在P3电子表格单元格上获取编号:

您必须确保公式中的字符串始终用双引号引起来,因此您必须像上例中那样在公式周围使用单引号,或者必须在公式内部转义双引号:"=COUNTIF(I2:I100, \">0\")"。
您可以使用与上述相同的步骤将大量其他公式添加到电子表格中。自己去吧!
添加样式
即使不是每天都要设计电子表格的样式,但知道如何做仍然是一件好事。
使用openpyxl,您可以将多个样式选项应用于电子表格,包括字体,边框,颜色等。查看openpyxl 文档以了解更多信息。
您还可以选择将样式直接应用于单元格,或者创建模板并重复使用它以将样式应用于多个单元格。
让我们从简单的单元格样式开始,sample.xlsx再次使用我们作为基础电子表格:
`>>> # Import necessary style classesfrom openpyxl.styles import Font, Color, Alignment, Border, Side, colors
Create a few styles
bold_font = Font(bold=True)
big_red_text = Font(color=colors.RED, size=20)
center_aligned_text = Alignment(horizontal="center")
double_border_side = Side(border_style="double")
square_border = Border(top=double_border_side,
... right=double_border_side,
... bottom=double_border_side,
... left=double_border_side)Style some cells!
sheet["A2"].font = bold_font
sheet["A3"].font = big_red_text
sheet["A4"].alignment = center_aligned_text
sheet["A5"].border = square_border
workbook.save(filename="sample_styles.xlsx")`
如果现在打开电子表格,您应该在列的前5个单元格中看到很多不同的样式A:

妳去 你得到了:
- A2的文字为粗体
- A3中的文本为红色且字体较大
- A4文本居中
- A5,文本周围带有方形边框
注意:对于颜色,您也可以使用HEX代码代替Font(color="C70E0F")。
您还可以通过简单地将样式同时添加到单元中来组合样式:
`>>> # Reusing the same styles from the example abovesheet["A6"].alignment = center_aligned_text
sheet["A6"].font = big_red_text
sheet["A6"].border = square_border
workbook.save(filename="sample_styles.xlsx")`
在A6这里看看单元格:
当您想将多个样式应用于一个或多个单元格时,可以改用一个NamedStyle类,它就像可以反复使用的样式模板。看下面的例子:
`>>> from openpyxl.styles import NamedStyleLet's create a style template for the header row
header = NamedStyle(name="header")
header.font = Font(bold=True)
header.border = Border(bottom=Side(border_style="thin"))
header.alignment = Alignment(horizontal="center", vertical="center")Now let's apply this to all first row (header) cells
header_row = sheet[1]
for cell in header_row:
... cell.style = headerworkbook.save(filename="sample_styles.xlsx")`
如果现在打开电子表格,您应该看到其第一行为粗体,文本与中心对齐,并且底边框很小!在下面看看:

正如您在上面看到的,样式设置有很多选择,并且取决于用例,因此可以随时检查openpyxl 文档并查看您还可以做些什么。
条件格式
在向电子表格添加样式时,此功能是我个人最喜欢的功能之一。
这是一种更强大的样式化方法,因为它根据电子表格中数据的变化动态地应用样式。
简而言之,条件格式允许您根据特定条件指定要应用于单元格(或单元格范围)的样式列表。
例如,一个广泛使用的案例是拥有一个资产负债表,其中所有负数总计为红色,而正数总计为绿色。这种格式使发现好坏期间的效率大大提高。
事不宜迟,让我们选择我们最喜欢的电子表格sample.xlsx-并添加一些条件格式。
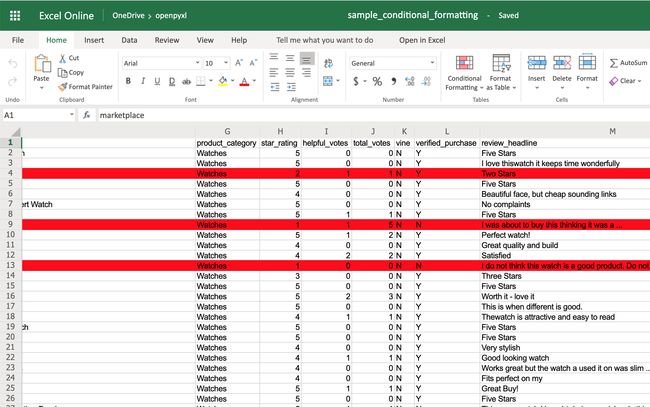
您可以从添加一个简单的开始,为少于3星的所有评论添加红色背景:
`>>> from openpyxl.styles import PatternFill, colorsfrom openpyxl.styles.differential import DifferentialStyle
from openpyxl.formatting.rule import Rulered_background = PatternFill(bgColor=colors.RED)
diff_style = DifferentialStyle(fill=red_background)
rule = Rule(type="expression", dxf=diff_style)
rule.formula = ["$H1<3"]
sheet.conditional_formatting.add("A1:O100", rule)
workbook.save("sample_conditional_formatting.xlsx")`
现在,您将看到所有星级评分低于3且带有红色背景的评论:
在代码方面,这里唯一的新东西是对象DifferentialStyle和Rule:
-
DifferentialStyle与NamedStyle,您已经在上面看到的十分相似,它用于汇总多种样式,例如字体,边框,对齐方式等。 -
Rule如果单元格与规则的逻辑匹配,则负责选择单元格并应用样式。
使用Rule对象,您可以创建许多条件格式设置方案。
但是,为简单起见,该openpyxl软件包提供了3种内置格式,这使得创建一些常见的条件格式设置模式变得更加容易。这些内置有:
ColorScaleIconSetDataBar
该ColorScale使您能够创建色彩渐变的能力:
`>>> from openpyxl.formatting.rule import ColorScaleRulecolor_scale_rule = ColorScaleRule(start_type="min",
... start_color=colors.RED,
... end_type="max",
... end_color=colors.GREEN)Again, let's add this gradient to the star ratings, column "H"
sheet.conditional_formatting.add("H2:H100", color_scale_rule)
workbook.save(filename="sample_conditional_formatting_color_scale.xlsx")`
现在H,根据星级,您应该在列上看到从红色到绿色的颜色渐变:

您还可以添加第三种颜色并制作两个渐变:
`>>> from openpyxl.formatting.rule import ColorScaleRule现在Hcolor_scale_rule = ColorScaleRule(start_type="num",
... start_value=1,
... start_color=colors.RED,
... mid_type="num",
... mid_value=3,
... mid_color=colors.YELLOW,Again, let's add this gradient to the star ratings, column "H"
>>> sheet.conditional_formatting.add("H2:H100", color_scale_rule)
>>> workbook.save(filename="sample_conditional_formatting_color_scale.xlsx")
,根据星级,您应该在列上看到从红色到绿色的颜色渐变: [](https://files.realpython.com/media/Screenshot_2019-06-24_19.00.57.26756963c1e9.png) 您还可以添加第三种颜色并制作两个渐变: >>> >>> from openpyxl.formatting.rule import ColorScaleRule>>> color_scale_rule = ColorScaleRule(start_type="num",
... start_value=1,
... start_color=colors.RED,
... mid_type="num",
... mid_value=3,
... mid_color=colors.YELLOW,
... end_type="num",
... end_value=5,
... end_color=colors.GREEN)
Again, let's add this gradient to the star ratings, column "H"
sheet.conditional_formatting.add("H2:H100", color_scale_rule)
workbook.save(filename="sample_conditional_formatting_color_scale_3.xlsx")`
这次,您会注意到介于1到3之间的星级具有从红色到黄色的渐变,而介于3到5之间的星级具有从黄色到绿色的渐变:

该图标集,您可以根据其价值的图标添加到单元格:
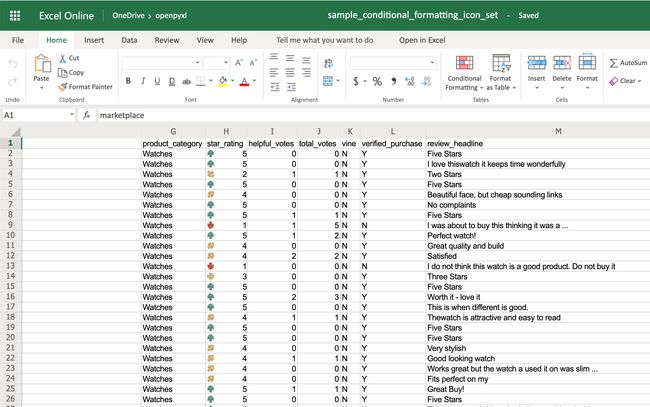
`>>> from openpyxl.formatting.rule import IconSetRuleicon_set_rule = IconSetRule("5Arrows", "num", [1, 2, 3, 4, 5])
sheet.conditional_formatting.add("H2:H100", icon_set_rule)
workbook.save("sample_conditional_formatting_icon_set.xlsx")`
您会在星级旁边看到一个彩色的箭头。该箭头为红色,当单元格的值为1时指向下方,随着等级的提高,箭头开始指向上方并变为绿色:
除了箭头,该openpyxl程序包还包含您可以使用的其他图标的完整列表。
最后,DataBar允许您创建进度条:
`>>> from openpyxl.formatting.rule import DataBarRuledata_bar_rule = DataBarRule(start_type="num",
... start_value=1,
... end_type="num",
... end_value="5",
... color=colors.GREEN)
sheet.conditional_formatting.add("H2:H100", data_bar_rule)
workbook.save("sample_conditional_formatting_data_bar.xlsx")`
现在,您将看到绿色的进度条,该星级越接近星级5,则变得越满:

如您所见,使用条件格式可以完成很多很酷的事情。
在这里,您仅看到了可以使用它实现的功能的几个示例,但是请查阅openpyxl 文档以查看大量其他选项。
添加图像
即使图像不是您经常在电子表格中看到的东西,但是能够添加它们还是很酷的。也许您可以将其用于品牌宣传或使电子表格更具个性。
为了能够使用将图像加载到电子表格openpyxl,您必须安装Pillow:
$ pip install Pillow 除此之外,您还需要一张图片。在这个例子中,你可以抓住真正的Python下面的标志,并将其从转换.webp到.png使用在线转换器,例如cloudconvert.com,保存最终的文件logo.png,并将其复制到您正在运行的实例的根文件夹:

之后,这是将图像导入hello_word.xlsx电子表格所需的代码:
`from openpyxl import load_workbook
from openpyxl.drawing.image import ImageLet's use the hello_world spreadsheet since it has less data
workbook = load_workbook(filename="hello_world.xlsx")
sheet = workbook.activelogo = Image("logo.png")
A bit of resizing to not fill the whole spreadsheet with the logo
logo.height = 150
logo.width = 150sheet.add_image(logo, "A3")
workbook.save(filename="hello_world_logo.xlsx")`
您的电子表格中有一张图片!这里是:

图像的左上角在您选择的单元格上,在这种情况下为A3。
添加漂亮的图表
电子表格可以执行的另一项强大功能是创建各种图表。
图表是快速可视化和理解数据负载的好方法。有很多不同的图表类型:条形图,饼图,折线图等。openpyxl有很多支持。
在这里,您将仅看到几个图表示例,因为对于每种图表类型,其背后的理论都是相同的:
注意:openpyxl当前不支持的一些图表类型包括Funnel,Gantt,Pareto,Treemap,Waterfall,Map和Sunburst。
对于您要构建的任何图表,您都需要定义图表类型:BarChart,LineChart等等,再加上要用于图表的数据,称为Reference。
在构建图表之前,您需要定义要查看的数据。有时,您可以按原样使用数据集,但其他时候,您需要稍微整理一下数据以获取更多信息。
让我们从构建带有一些示例数据的新工作簿开始:
1 from openpyxl import Workbook 2 from openpyxl.chart import BarChart, Reference 3 4 workbook = Workbook() 5 sheet = workbook.active 6 7 # Let's create some sample sales data 8 rows = [ 9 ["Product", "Online", "Store"], 10 [1, 30, 45], 11 [2, 40, 30], 12 [3, 40, 25], 13 [4, 50, 30], 14 [5, 30, 25], 15 [6, 25, 35], 16 [7, 20, 40], 17 ] 18 19 for row in rows: 20 sheet.append(row)
现在,您将开始创建一个条形图,该条形图显示每种产品的销售总数:
22 chart = BarChart() 23 data = Reference(worksheet=sheet, 24 min_row=1, 25 max_row=8, 26 min_col=2, 27 max_col=3) 28 29 chart.add_data(data, titles_from_data=True) 30 sheet.add_chart(chart, "E2") 31 32 workbook.save("chart.xlsx") 你有它。在下面,您可以看到一个非常简单的条形图,显示了在线产品在线销售与店内产品销售之间的区别:

与图像一样,图表的左上角在您添加图表的单元格上。就您而言,它在电池上E2。
注意:根据您使用的是Microsoft Excel还是开源替代品(LibreOffice或OpenOffice),图表可能会略有不同。
尝试创建折线图,稍稍更改数据:
1 import random 2 from openpyxl import Workbook 3 from openpyxl.chart import LineChart, Reference 4 5 workbook = Workbook() 6 sheet = workbook.active 7 8 # Let's create some sample sales data 9 rows = [ 10 ["", "January", "February", "March", "April", 11 "May", "June", "July", "August", "September", 12 "October", "November", "December"], 13 [1, ], 14 [2, ], 15 [3, ], 16 ] 17 18 for row in rows: 19 sheet.append(row) 20 21 for row in sheet.iter_rows(min_row=2, 22 max_row=4, 23 min_col=2, 24 max_col=13): 25 for cell in row: 26 cell.value = random.randrange(5, 100)
使用上面的代码,您将能够生成一些随机数据,这些数据涉及一年中3种不同产品的销售额。
完成后,您可以使用以下代码轻松创建折线图:
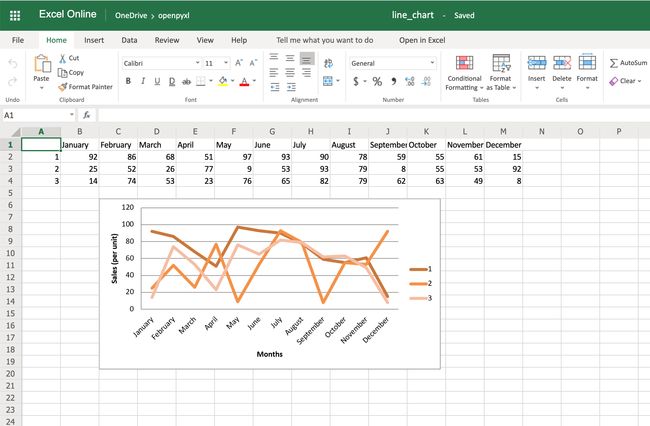
28 chart = LineChart() 29 data = Reference(worksheet=sheet, 30 min_row=2, 31 max_row=4, 32 min_col=1, 33 max_col=13) 34 35 chart.add_data(data, from_rows=True, titles_from_data=True) 36 sheet.add_chart(chart, "C6") 37 38 workbook.save("line_chart.xlsx") 这是以上代码的结果:

这里要记住的一件事是from_rows=True添加数据时正在使用的事实。此参数使图表逐行而不是逐列绘制。
在示例数据中,您看到每个产品都有一行包含12个值(每月1列)的行。这就是您使用的原因from_rows。如果您不传递该参数,则默认情况下,图表会尝试按列进行绘制,您将获得按月比较的销售额。
上述参数更改的另一个不同之处在于,我们Reference现在从第一列开始min_col=1,而不是第二列。由于图表现在希望第一列具有标题,因此需要进行此更改。
关于图表样式,您还可以更改其他几件事。例如,您可以向图表添加特定类别:
cats = Reference(worksheet=sheet, min_row=1, max_row=1, min_col=2, max_col=13) chart.set_categories(cats) 在保存工作簿之前,添加以下代码,您应该看到出现的月份名称而不是数字:

在代码方面,这是最小的更改。但是,就电子表格的可读性而言,这使某人打开电子表格并立即了解图表变得容易得多。
您可以提高图表可读性的另一件事是添加一个轴。您可以使用属性x_axis和y_axis:
chart.x_axis.title = "Months" chart.y_axis.title = "Sales (per unit)" 这将生成一个如下所示的电子表格:

如您所见,像上面这样的小变化使阅读图表变得更加容易和快捷。
还有一种使用Excel的默认ChartStyle属性来设置图表样式的方法。在这种情况下,您必须选择1到48之间的数字。根据您的选择,图表的颜色也会改变:
# You can play with this by choosing any number between 1 and 48 chart.style = 24 使用上面选择的样式,所有行都有一些橙色阴影:
关于每种样式编号的外观,没有明确的文档,但是此电子表格中有一些可用样式的示例。
完整的代码示例 显示隐藏
您可以应用更多的图表类型和自定义,因此,如果您需要一些特定的格式,请确保签出软件包文档。
将Python类转换为Excel电子表格
您已经了解了如何将Excel电子表格的数据转换为Python类,但是现在让我们做相反的事情。
假设您有一个数据库,并且正在使用一些对象关系映射(ORM)将数据库对象映射到Python类中。现在,您要将那些相同的对象导出到电子表格中。
让我们假设以下数据类代表来自数据库的有关产品销售的数据:
`from dataclasses import dataclass
from typing import List@dataclass
class Sale:
quantity: int@dataclass
class Product:
id: str
name: str
sales: List[Sale]`
现在,假设上面的类存储在db_classes.py文件中,让我们生成一些随机数据:
1 import random 2 3 # Ignore these for now. You'll use them in a sec ;) 4 from openpyxl import Workbook 5 from openpyxl.chart import LineChart, Reference 6 7 from db_classes import Product, Sale 8 9 products = [] 10 11 # Let's create 5 products 12 for idx in range(1, 6): 13 sales = [] 14 15 # Create 5 months of sales 16 for _ in range(5): 17 sale = Sale(quantity=random.randrange(5, 100)) 18 sales.append(sale) 19 20 product = Product(id=str(idx), 21 name="Product %s" % idx, 22 sales=sales) 23 products.append(product)
通过运行这段代码,您应该获得5个销售5个月的产品,每个月的销售数量是随机的。
现在,要将其转换为电子表格,您需要遍历数据并将其附加到电子表格中:
25 workbook = Workbook() 26 sheet = workbook.active 27 28 # Append column names first 29 sheet.append(["Product ID", "Product Name", "Month 1", 30 "Month 2", "Month 3", "Month 4", "Month 5"]) 31 32 # Append the data 33 for product in products: 34 data = [product.id, product.name] 35 for sale in product.sales: 36 data.append(sale.quantity) 37 sheet.append(data) 而已。那应该允许您创建一个电子表格,其中包含来自数据库的一些数据。
但是,为什么不使用您最近获得的一些很酷的知识来添加图表以及更直观地显示数据呢?
好吧,那么您可能可以执行以下操作:
38 chart = LineChart() 39 data = Reference(worksheet=sheet, 40 min_row=2, 41 max_row=6, 42 min_col=2, 43 max_col=7) 44 45 chart.add_data(data, titles_from_data=True, from_rows=True) 46 sheet.add_chart(chart, "B8") 47 48 cats = Reference(worksheet=sheet, 49 min_row=1, 50 max_row=1, 51 min_col=3, 52 max_col=7) 53 chart.set_categories(cats) 54 55 chart.x_axis.title = "Months" 56 chart.y_axis.title = "Sales (per unit)" 57 58 workbook.save(filename="oop_sample.xlsx") 现在我们在说话!这是从数据库对象生成的电子表格,其中包含图表和所有内容:

这是您总结图表新知识的好方法!
奖励:与熊猫一起工作
即使可以使用Pandas处理Excel文件,也有一些事情是Pandas无法完成的,或者openpyxl直接使用会更好。
例如,使用的一些优点openpyxl是能够轻松地使用样式,条件格式等自定义电子表格。
但是,请猜怎么着,您不必担心拣货。实际上,openpyxl既支持将数据从Pandas DataFrame转换为工作簿,也支持将openpyxl工作簿转换为Pandas DataFrame。
注意:如果您不熟悉 Pandas,请事先查看有关Pandas DataFrames的课程。
首先,请记住安装该pandas软件包:
$ pip install pandas 然后,让我们创建一个示例DataFrame:
1 import pandas as pd 2 3 data = { 4 "Product Name": ["Product 1", "Product 2"], 5 "Sales Month 1": [10, 20], 6 "Sales Month 2": [5, 35], 7 } 8 df = pd.DataFrame(data)
现在您已经有了一些数据,可以.dataframe_to_rows()用来将其从DataFrame转换为工作表:
10 from openpyxl import Workbook 11 from openpyxl.utils.dataframe import dataframe_to_rows 12 13 workbook = Workbook() 14 sheet = workbook.active 15 16 for row in dataframe_to_rows(df, index=False, header=True): 17 sheet.append(row) 18 19 workbook.save("pandas.xlsx") 您应该看到一个如下所示的电子表格:

如果要添加DataFrame的索引,则可以更改index=True,它将每行的索引添加到电子表格中。
另一方面,如果要将电子表格转换为DataFrame,也可以采用以下非常简单的方式进行操作:
`import pandas as pd
from openpyxl import load_workbookworkbook = load_workbook(filename="sample.xlsx")
sheet = workbook.activevalues = sheet.values
df = pd.DataFrame(values)`
另外,例如,如果您想添加正确的标题并将评论ID用作索引,那么您也可以这样做:
`import pandas as pd
from openpyxl import load_workbook
from mapping import REVIEW_IDworkbook = load_workbook(filename="sample.xlsx")
sheet = workbook.activedata = sheet.values
Set the first row as the columns for the DataFrame
cols = next(data)
data = list(data)Set the field "review_id" as the indexes for each row
idx = [row[REVIEW_ID] for row in data]
df = pd.DataFrame(data, index=idx, columns=cols)`
使用索引和列使您可以轻松地从DataFrame访问数据:
`>>> df.columns
Index(['marketplace', 'customer_id', 'review_id', 'product_id',
'product_parent', 'product_title', 'product_category', 'star_rating',
'helpful_votes', 'total_votes', 'vine', 'verified_purchase',
'review_headline', 'review_body', 'review_date'],
dtype='object')Get first 10 reviews' star rating
df["star_rating"][:10]
R3O9SGZBVQBV76 5
RKH8BNC3L5DLF 5
R2HLE8WKZSU3NL 2
R31U3UH5AZ42LL 5
R2SV659OUJ945Y 4
RA51CP8TR5A2L 5
RB2Q7DLDN6TH6 5
R2RHFJV0UYBK3Y 1
R2Z6JOQ94LFHEP 5
RX27XIIWY5JPB 4
Name: star_rating, dtype: int64Grab review with id "R2EQL1V1L6E0C9", using the index
df.loc["R2EQL1V1L6E0C9"]
marketplace US
customer_id 15305006
review_id R2EQL1V1L6E0C9
product_id B004LURNO6
product_parent 892860326
review_headline Five Stars
review_body Love it
review_date 2015-08-31
Name: R2EQL1V1L6E0C9, dtype: object`
无论您是要用来openpyxl美化您的Pandas数据集还是使用Pandas进行一些硬核代数,现在您都知道如何在这两个软件包之间切换。
结论
Phew,经过漫长的阅读之后,您现在知道如何在Python中使用电子表格了!您可以依靠openpyxl,您值得信赖的伙伴,来:
- 以Python方式从电子表格中提取有价值的信息
- 无论复杂程度如何,创建自己的电子表格
- 向电子表格中添加一些很酷的功能,例如条件格式或图表