机器学习(十二)分类算法之随机森林
作为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。最初,我是在参加校外竞赛时接触到随机森林算法的。最近几年的国内外大赛,包括2013年百度校园电影推荐系统大赛、2014年阿里巴巴天池大数据竞赛以及Kaggle数据科学竞赛,参赛者对随机森林的使用占有相当高的比例。此外,据我的个人了解来看,一大部分成功进入答辩的队伍也都选择了Random Forest 或者 GBDT 算法。所以可以看出,Random Forest在准确率方面还是相当有优势的。
那说了这么多,那随机森林到底是怎样的一种算法呢?
如果读者接触过决策树(Decision Tree)的话,那么会很容易理解什么是随机森林。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想–集成思想的体现。“随机”的含义我们会在下边部分讲到。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想
什么是集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
什么是随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。

例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终投票结果就是True
随机森林原理过程
学习算法根据下列算法而建造每棵树:
- 用N来表示训练用例(样本)的个数,M表示特征数目。
- 1 一次随机选出一个样本,重复N次, (有可能出现重复的样本)
- 2 随机去选出m个特征, m <
- 采取bootstrap抽样
为什么采用BootStrap抽样
- 为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的 - 为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
随机森林API
- class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- 随机森林分类器
- n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
- criteria:string,可选(default =“gini”)分割特征的测量方法
- max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
- max_features="auto”,每个决策树的最大特征数量
- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features) (same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
- bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
- min_samples_split:节点划分最少样本数
- min_samples_leaf:叶子节点的最小样本数
- 超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
随机森林预测案例
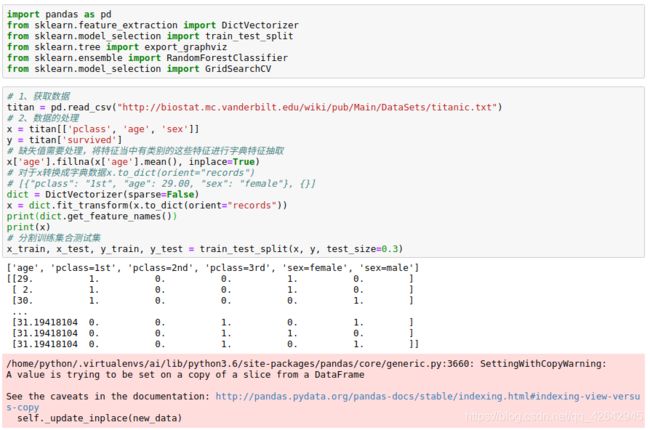
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# 1、获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 2、数据的处理
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取
x['age'].fillna(x['age'].mean(), inplace=True)
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
dict = DictVectorizer(sparse=False)
x = dict.fit_transform(x.to_dict(orient="records"))
print(dict.get_feature_names())
print(x)
# 分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
- 实例化随机森林
# 随机森林去进行预测
rf = RandomForestClassifier()
- 定义超参数的选择列表
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
- 使用GridSearchCV进行网格搜索
# 超参数调优
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("随机森林预测的准确率为:", gc.score(x_test, y_test))

对比决策树的预测的准确率:

注意
- 随机森林的建立过程
- 树的深度、树的个数等需要进行超参数调优