目前NewSQL开源项目比较有名有国内的TiDB以及硅谷的CockroachDB,另外还有一个后起之秀YugabyteDB,但是目前它还没有经过生产检验,相对不成熟。
它们均参考Google的spanner&F1论文,只是在很多的技术细节上不同。
以下是个人粗浅的分析,尽力做客观分析,如果有不对和不恰当的地方,欢迎指正。
1 架构
1.1 TiDB
TiDB采用中心化设计,计算存储分离架构,它由三部分组成:PD,TiDB,TiKV。
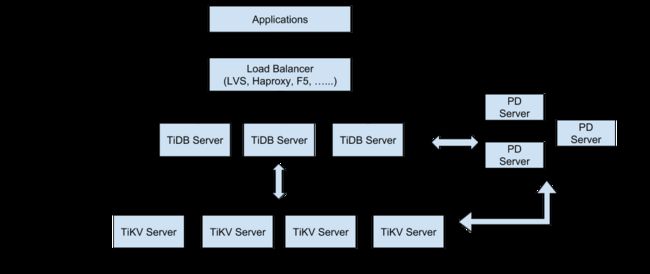
PD:负责集群的元数据管理,负载均衡,故障恢复,集群伸缩,集群升级,TSO时钟分配等。它自身也通过raft实现多副本数据同步,保证高可用。
TiDB:负责SQL解析,生成执行计划,执行计划执行以及ACID事务控制和执行。TiDB是无状态服务,可以透明弹性伸缩。
TiKV:是分布式KV层,底层采用RocksDB作为本地KV存储引擎,在之上构建了业务MVCC,数据按照字典序划分为很多region,这些region一般采用多副本,使用raft共识算法实现副本之间的数据强一致,被划分为同时也承担了TiDB的部分计算(计算下推)。
1.2 CockroachDB
CockroachDB(以下简称CRDB)采用去中心化设计,也使用计算存储分离架构。
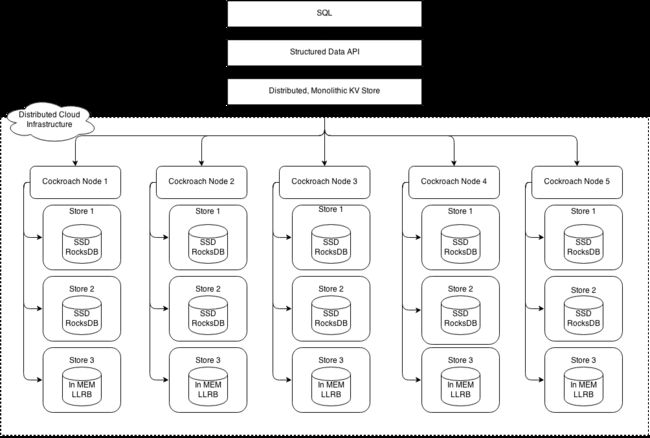
CRDB在逻辑上分成两层SQL层+分布式KV层。
跟TiDB一样,CRDB底层也使用RocksDB做KV存储引擎,按照字典序划分Range,采用Raft共识算法保证Range的副本之间数据的强一致。
CRDB节点之间通过Gossip协议进行信息交换。元数据管理采用两级管理,理论上最大支持4EB的数据。
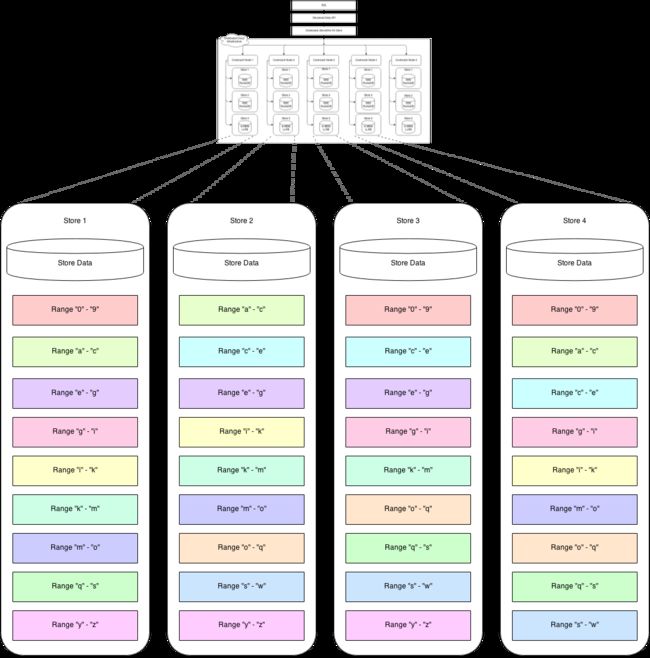
数据一致性
两者都采用raft共识算法,实现了multi-raft。

因为raft共识算法不能解决脑裂导致的双主问题,会导致stale read问题。因此TiDB和CRDB都引入了region(CRDB中对等概念是range)lease的概念,从逻辑上讲region lease holder和region raft leader是两个不同层面的概念,可以在物理上不是一个副本节点,所有的读写都由lease holder负责,为了避免多次IO,一般会在工程层面上优化,约束lease holder和region leader在同一个节点上。lease holder并不是没有代价,尽管可以约束lease holder和region leader在同一个节点上,但是lease需要在到期之前续约,会引入额外的网络开销,这种开销是客观的,当region很多的时候,事实上NewSQL面向的就是大规模数据存储,因此region就是会很多,因此对lease的更新也需要优化。TiDB不清楚有没有这方面的优化,没有看到相关的资料,只能后面阅读源码证实(大概率没有,这是一个非常好的技术亮点,没有不宣传的理由),CRDB在这方面还是做的不错,这也得益于底层的Gossip协议,它通过绑定region lease holder到Node的做法,同时在没有读写的情况下避免lease主动续约的方式极大的减少了这方面的网络开销。
另一个主题就是follower read,在此之前所有的读写都由lease holder负责,这样主副本的压力就很大,因此如果牺牲一定的实时性,可以在从副本上提供全局一致的读取服务。这方面TiDB的方案在实时性方面比CRDB要好,但是代价就是仍然需要跟leader进行一次通信,确认commit index,而CRDB的做法采用一个安全窗口,类似google spanner safe time一样,提供一致性读服务,但是存在10秒~30秒左右的滞后,并且暂时看不到降低的可能(架构使然)。
Raft的问题在于写提交速度比较慢,另外raft log现在都存储在RocksDB里面,如果log的存储不使用独立的磁盘的话,log的存储和数据的存储之间存在相互干扰。还有一点就是raft log的复制涉及到序列化反序列化优化,pipeline优化等,基于etcd raft在这方面做的并不是很好(有些是开发语言层面的问题),存在一定的优化空间。
Raft的log apply一般也要优化,比如采用latch机制,在提交log之前,完成业务逻辑处理,应该log的时候只做存储处理,这样避免所有副本都进行相同的冗余的业务逻辑。
TiDB和CRDB都引入了latch机制来优化写,另外因为lease holder和latch,就可以直接实现leader上本地读取操作了,不需要考虑raft的一致性读逻辑。
分布式事务
TiDB和CRDB都采用了乐观事务模型,但是具体方案又不同,总体上来讲tiDB是在commit阶段采用两阶段提交来实现分布式事务,而CRDB是在事务的整个过程中使用两阶段提交,因此CRDB的分布式事务由一点点悲观事务的味道,尽管本质上它仍然是乐观事务模型。
TiDB的事务采用Google Percolator事务模型。

这种事务模型需要一个全局的时钟,TiDB采用TSO时钟,这种时钟方案实现简单,但是问题在于存在单点瓶颈,另外就是不太适合跨地域多活部署。
整个事务模型是在正常的数据中增加了lock列来实现事务冲突检查和提交,不需要独立的分布式事务记录。TiDB使用三个CF来实现一行数据,其中一个CF存储lock信息,用于冲突检查,另一个CF存储最后提交的版本信息,最后一个CF存储真正提交的数据。这种模型虽然解耦了数据,MVCC和事务控制信息,但是带来的问题是读取一行数据的的时候需要多次IO。标准的流程是先读取lock信息,确认是否存在未提交的事务,然后读取提交的版本信息,确认可以读取MVCC的那一个版本,然后才是读取真正的数据,因为分布在不同的CF,意味着不同的SST文件,因此需要多次IO。尽管TiDB做了一些优化,但是这种开销是结构性的。
TiDB的事务模型简单容易实现,但是从演化的角度讲,很难进一步优化,这个可以对比CRDB就可以看的比较清楚。
CRDB的事务模型在开始的时候也考虑过采用类似的架构,但是主要是考虑到需要在client缓存未提交的数据,限制了事务的规模,另一方面不方便后续的优化,因此他们采用比较激进的方案。
分布式事务需要全局时钟,这方面CRDB没有采用TSO方案,这个和它采用无中心化的设计有关,它采用混合逻辑时钟(HLC),这种方案不依赖中心节点,方面扩展,即使是跨地域部署也没有什么问题。HLC的问题在于它提供的是一个时钟范围,而不是一个精确的时钟,导致在判断两个事务的HB的时候存在不确定性,导致可能引起事务重试或者终止。由于依赖NTP,因此当节点之间的时钟偏差较大的时候,事务冲突概率增加,影响集群吞吐,甚至不可用。另一方面基于HLC编程比较复杂,代码理解起来比较费劲。
CRDB不再事务协调者节点缓存未提交的数据,而是以write intent(意向写)的方式直接在参与者节点落盘,CRDB需要一个显示的事务记录,这个事务记录存储在第一个事务参与者所在分片上。当事务提交的时候,只需要修改事务记录中事务的状态为commit即可返回给客户端事务提交成功,其他的intents可以异步提交完成。
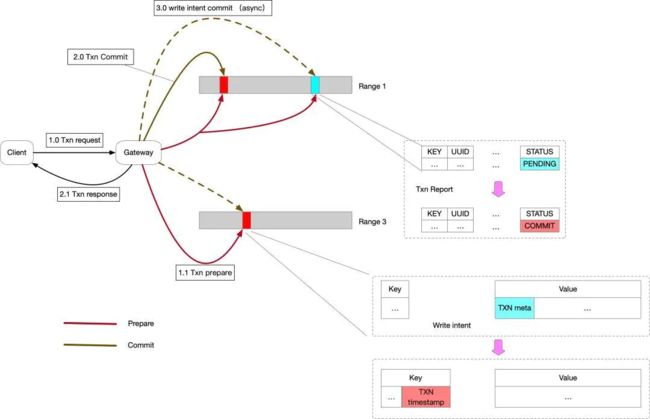
当然事情没有那么简单,想要实现SSI隔离,按照所参考的论文,需要在range上维护一个用于事务冲突检查的cache,它记录所有对这个range上的key的读写(包括事务ID,时间戳等信息),其他事务根据这个cache就可以判断出事务冲突,进而实现SSI事务隔离。这个cache的维护也不简单,需要考虑内存,cache中记录的淘汰,以及lease holder发生切换后的cache更新。
CRDB事务模型中没有事务死锁的问题,这是因为CRDB引入了随机事务优先级,这个事务优先级策略可以保证在发生事务死锁的时候(比如相互等待事务提交),可以最终自行终止其中一个事务来达到解锁的目的。
CRDB在分布式事务优化上做了很多的努力,总结如下:
1. 一阶段优化
如果所有的事务参与者都在一个分片上,那么就没必要采用两阶段提交了,可以利用raft log的原子性和rocksDB提供的本地事务能力直接提交。
2. 事务记录优化
3. 事务流水线
4. 事务并行提交
这里不再展开,想了解的同学可以查看我的另一篇文章CB-SQL分布式事务优化演进
分布式SQL
这方面TiDB和CRDB差别不大,两者都实现了分布式SQL,都采用了计算存储分离,但是都存在计算下推的逻辑,一个重要的区别是CRDB是列式存储(可以退化为行存),TiDB是行存(TiSpark是列式存储)。
对于计算下推,这方面CRDB实现起来比TiDB好做一些,主要是得益于无中心化的架构,每个节点即使存储节点也是计算几点,都可以承担SQL的服务。这种逻辑上的存储计算分离存在弊端,并未真正实现存储和计算的分离,在资源调度上比较难以平衡。
NewSQL的一个重要指标就是所有的能力都需要具备和数据一样的扩展能力。
水平扩展和故障恢复
NewSQL的水平扩展得益于自身的shared-nothing架构,只有64MB大小的分片很容易复制,利用raft的强一致性和快照技术就可以轻松实现水平扩展。
故障恢复可以拆解为一个range group的迁移+节点下线。
故障恢复需要注意的是,在三副本的情况下,当集群中两个节点同时故障的时候,同时集群的规模远大于连个节点时,并不一定就安全,如果正好有一个分片的两个副本位于故障节点上,那么很不幸,这个集群无法正常工作。因此三副本并不是一个那么安全的配置。参考AWS提出的故障背景噪声,当我们的集群规模很大的时候,就需要考虑这种潜在的安全风险,因此不能因为多副本就高枕无忧,仍然需要进行集群备份。
备份恢复
备份有两种,逻辑备份和物理备份。
逻辑备份类似mySQL的dump,物理备份就是直接备份rocksDB的SST文件,当然没有那么简单,我们需要获取一个集群快照,按照这个快照生成标准的SST文件,同时需要考虑分布式,并行备份。
备份操作会产生大量的磁盘和网络IO,对集群的正常服务存在影响。当然也可以优化,一种可行的方案就是增加类似learner的角色副本,备份只允许调度在这些副本上,并且这些副本使用独立的节点,没有其他的读写流量,这样就可以降低对正常业务的影响,另一种方案是根据业务的规律,一般凌晨是流量低谷,可以开展备份。
物理备份要比逻辑备份快很多,另外逻辑备份耗时太长,如果超过了MVCC GC时间,那么就存在数据丢失的问题。
只有物理备份也是不够的,这样会丢失很多数据,我们需要结合实时日志一起来尽量恢复数据,tiDB有binlog机制,CRDB提供了CDC,但是都需要我们来开发一些工具来配合。
关于CDC,感兴趣可以专门讲一讲。也可以参阅CB-SQL 变更数据捕获(CDC)
部署/监控
TiDB的CRDB的部署都比较简单,CRDB因为是无中心化架构,部署起来更加简单。另外默认情况下,CRDB内部的系统表都采用五副本,因此安全的生产部署是采用五个节点。
TiDB原来部署PD依赖etcd集群,现在好像不需要了,这样可以减少部署的负担和资源占用。
CRDB对K8S支持的很好,可以很方面的在容器环境下部署,灵活性比较好。
CRDB和TiDB的监控都比较齐全。
最佳实践
1. 自增ID
考虑到NewSQL普遍采用的分片策略,自增ID会产生热分片,并且很难分散热点,这种场景无法发挥NewSQL的优势,这也是NewSQL不是银弹的一个典型案例,一般建议用户使用UUID来替换。
2. Batch提交
NewSQL支持分布式事务,因此事务开销比较大,单次写入性能不及传统的数据库,因此业务最好使用batch提交的方式,增加集群吞吐
3. 集群预热
默认一个table创建的时候只有一个分片,因此开始写入时候因为分片少,并且频繁分裂,造成初期写入的时候性能体验不佳,这个阶段成为集群预热,可以通过预分片的方式改善。
4. 谨慎执行DDL
对于drop table以及增加/删除 索引/列,涉及到数据的大规模删除或者写入,如果table很大,那么这个过程会造成集群的性能抖动,需要谨慎处理。
5. 重视索引
NewSQL的数据规模要比传统数据库高出几个量级,因此普通的一个查询如果没有索引的辅佐的话,性能会非常差,我们需要合理的设计索引和查询语句
6. 容器部署
如果集群的节点规模很小,但是单个节点的磁盘容量很大,那么当一个节点故障的时候,就会涉及到大规模数据的迁移,占用大量的磁盘和网络IO,造成集群不稳定,因此我们采用小节点模式,即一个节点的存储和计算规模都不大,在容器中部署,可以很方便的控制CPU,磁盘,内存资源的使用,我们就可以实现这种部署,好处就是考虑到OLTP场景查询规模不大,我们通过小节点模式,可以分散每一个节点的压力,同时利用集群的优化,平衡负载均衡和故障恢复对集群稳定性的影响。
7. 避免超大事务
超大事务一般执行的时间比较长,那么在CRDB上很容易产生事务冲突,造成事务终止或者重启,这样的事务重试的成本就很高。对于TiDB显示的限制事务的规模,CRDB虽然没有明确的事务规模限制,但是如果事务规模太大的话,仍然会提示事务太大,直接终止事务。
8. 根据业务定制优化
NewSQL有自己的适用场景,我们需要根据业务进行相应的定制以及优化,直接使用默认参数配置肯定不能充分发挥NewSQL的优势。
9. 乐观事务
乐观事务相比于悲观事务,对于用户来说一个直接的感受就是在交互式事务场景下,乐观事务一定要关注commit的结果,而悲观事务在commit时极少概率发生错误。因此一些业务逻辑需要进行必要的修改,尤其是当业务嵌入到一个业务层面的分布式事务(跨DB,跨接口),那么这些事务中间件通常都是依赖底层的数据库的悲观事务模型设计的,这个需要格外注意。
10. 写偏序/事务冲突
RR隔离存在幻读的问题,而SI存在写偏序的问题。幻读在innodb引擎上使用间隙锁来解决,而SI是通过select for update来对读加锁解决。
SSI的问题在于事务的冲突概率增加了,很多基于MySQL的用户不太习惯,因为总是需要考虑事务重试。
11. RocksDB调优
RocksDB暴露了很多的调优参数,不同的场景对读写的要求不同,因此仍然需要我们进行必要的参数调优。RocksDB的调优也比较复杂,需要对其架构和技术细节有充分的理解才行。
12. MVCC GC
MVCC的好处是实现了读写相互不干扰,提升了系统的吞吐。问题是需要考虑历史版本的GC问题。
如果历史版本太多,会占用大量的磁盘空间,如果GC的太频繁,也会消耗大量的CPU和磁盘IO,另一个问题就是如果有读事务的耗时比较久,那么这种GC就会导致数据丢失,影响正常的业务。同时如果历史版本太多也会影响正常的读取业务,这主要是因为RocksDB的seek代价比较大。
这里需要额外说一个,在采用自增ID的场景下,TiDB我不是很清楚,对于CRDB,这个自增ID的维护也是一个附属于业务table的seq table,它是一个独立的table,只有一个分片,因为只有一行有效的数据,因此也无法分裂,这样当大规模密集写入的时候,这个分片的历史版本就会不断累积造成这个分片过大,CRDB有背压机制可以限制这种场景,但是用户体验就很差,因为写着写着就提示写入失败。我跟CRDB社区也进行了一些讨论,看看如何优化。
总结
网络上有一个链接,里面详细罗列了两者的差异,感兴趣可以看看
https://blog.csdn.net/vkingnew/article/details/88559050